data efficient gans
1.0.0

Сгенерировано с использованием только 100 изображений Обамы, сварливых кошек, панд, моста вздохов, фонтана Медичи, Храма Небес, без предварительного обучения.
[Новая!] Обучение Pytorch с дифференцированным стилем-пирогом теперь доступно!
[Новый!] Наш учебник Colab выпущен!
[Новый!] FFHQ обучение поддерживается! Смотрите Diffaugment-Stylegan2 Readme.
[Новое!] Время, чтобы генерировать 100-выстрел интерполяционные видео с Generate_gif.py!
[Новый!] Наша репозитория дифференциации-Биггана-Имагенета (для обучения TPU) выпускается!
[Новый!] Наша дифференциальный репо-репо!
Этот репозиторий содержит нашу реализацию дифференцируемого увеличения (различия) как в Pytorch, так и в Tensorflow. Его можно использовать для значительного повышения эффективности данных для обучения GAN. Мы предоставили дифференциальный стиль-стильган2 (tensorflow) и дифференциальный стиль-стильган2-питор, дифференциал-биггана-цифар (Pytorch) для обучения графического процессора и дифференциации-биггана-имагенера (tensorflow) для обучения TPU.

Низко-выстрел генерации без предварительного обучения. При различии наша модель может генерировать изображения с высокой точностью, используя только 100 портретов Обамы, сварливые кошки или панды из наших собранных наборов 100 выстрелов, 160 кошек или 389 собак из набора данных Animalface с разрешением 256 × 256.
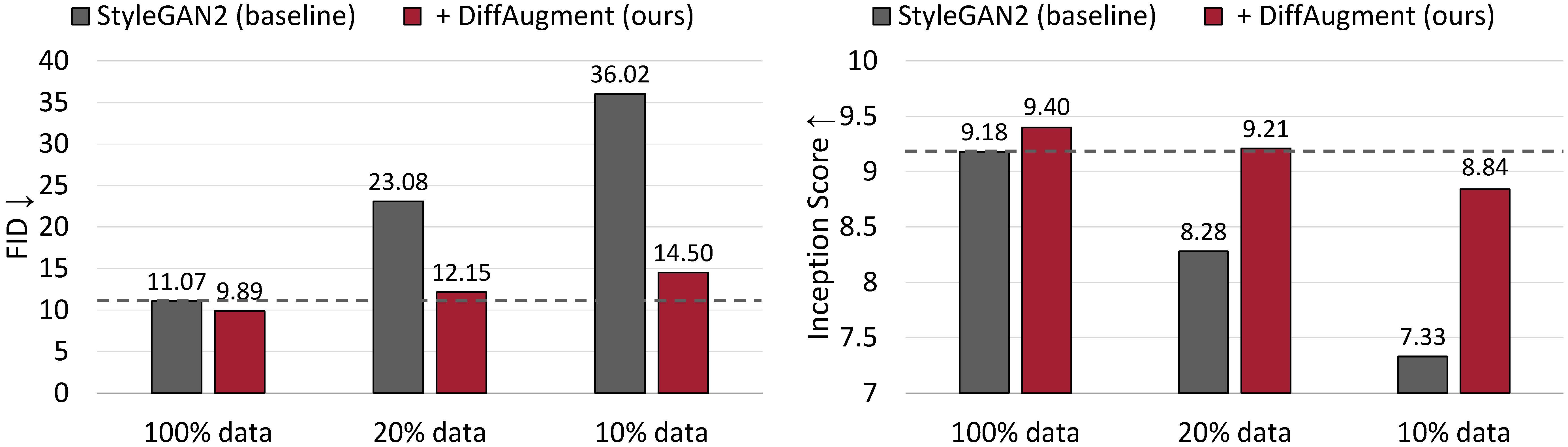
Безусловные результаты генерации по CIFAR-10. Производительность Stylegan2 резко ухудшается, учитывая меньше учебных данных. При различии мы можем приблизительно соответствовать его FID и превзойти его основание (IS), используя только 20% данных обучения.
Дифференцируемое увеличение для обучения GAN, эффективного GAN,
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu и Song Han
MIT, Университет Цинхуа, Adobe Research, CMU
arxiv

Обзор различия для обновления D (слева) и G (справа). Диффулирование применяет увеличение t к реальной выборке X и сгенерированному выходу g (z). Когда мы обновляем g, градиенты должны быть обработаны через T (III), который требует, чтобы T был дифференцируемый вход.
Для создания интерполяционного видео с использованием наших предварительно обученных моделей:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gifили для обучения новой модели:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4 Вы также можете попробовать 100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen или папка, содержащая ваши собственные тренировочные изображения. Пожалуйста, обратитесь к Diffaugment-Stylegan22 Readme для зависимостей и деталей.
[Новый!] Обучение Pytorch теперь доступно:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1Чтобы запустить Stylegan2 + Diffaugment для безусловного генерации на наборах данных из 100 выстрелов, Cifar, FFHQ или LSUN, пожалуйста, см.
Пожалуйста, обратитесь к Diffaugment-Biggan-Cifar Readme, чтобы запустить Biggan + Diffaugment для условного генерации на CIFAR (с использованием графических процессоров), и Diffaugment-Biggan-Imagenet Readme для работы на ImageNet (с использованием TPU).
Чтобы помочь вам использовать различия в собственной кодовой базе, мы предоставляем переносные операции дифференциации версий TensorFlow и Pytorch в Diffaugment_tf.py и Diffaugment_pytorch.py. Как правило, дифференциация может быть легко применено в любой модели, заменяя каждый d (x) на d (t (x)) , где x могут быть реальными изображениями или поддельными изображениями, D является дискриминатором, а T - операция различия. Например,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...Мы внедрили распределение цвета, перевода и выреза, как визуализировано ниже:

Если вы найдете этот код полезным, пожалуйста, укажите нашу статью:
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
Мы благодарим NSF Career Award #1943349, MIT-IBM Watson AI Lab, Google, Adobe и Sony за поддержку этого исследования. Исследования, поддерживаемые облачными TPU от Google Tensorflow Research Cloud (TFRC). Мы благодарим Уильяма С. Пибла и Иджун Ли за полезные комментарии.


