data efficient gans
1.0.0

Généré en utilisant seulement 100 images d'Obama, des chats grincheux, des pandas, le pont des soupirs, la fontaine Médicis, le temple du ciel, sans pré-formation.
[Nouveau!] Une formation Pytorch avec diffaugment-stylegan2-pytorch est maintenant disponible!
[Nouveau!] Notre tutoriel Colab est publié!
[Nouveau!] La formation FFHQ est soutenue! Voir le Diffaugment-Stylegan2 Readme.
[Nouveau!] Il est temps de générer des vidéos d'interpolation à 100 coups avec generate_gif.py!
[NOUVEAU!] Notre diffo Diffaugment-Biggan-Imagenet (pour la formation TPU) est publié!
[NOUVEAU!] Notre déménagement Pytorch diffar de diffarch est sorti!
Ce référentiel contient notre implémentation d'une augmentation différenciable (diffaument) dans Pytorch et TensorFlow. Il peut être utilisé pour améliorer considérablement l'efficacité des données pour l'entraînement GAN. Nous avons fourni le diffaugment-stylegan2 (tensorflow) et le diffaugment-stylegan2-pytorch, le diffaugment-biggan-cifar (pytorch) pour la formation GPU et le diffaugment-biggan-iMagenet (Tensorflow) pour la formation TPU.

Génération à faible coup sans pré-formation. Avec diffaugment, notre modèle peut générer des images à haute fidélité en utilisant seulement 100 portraits Obama, des chats grincheux ou des pandas à partir de nos ensembles de données de 100 coups collectés, 160 chats ou 389 chiens à partir de l'ensemble de données AnimalFace à une résolution 256 × 256.
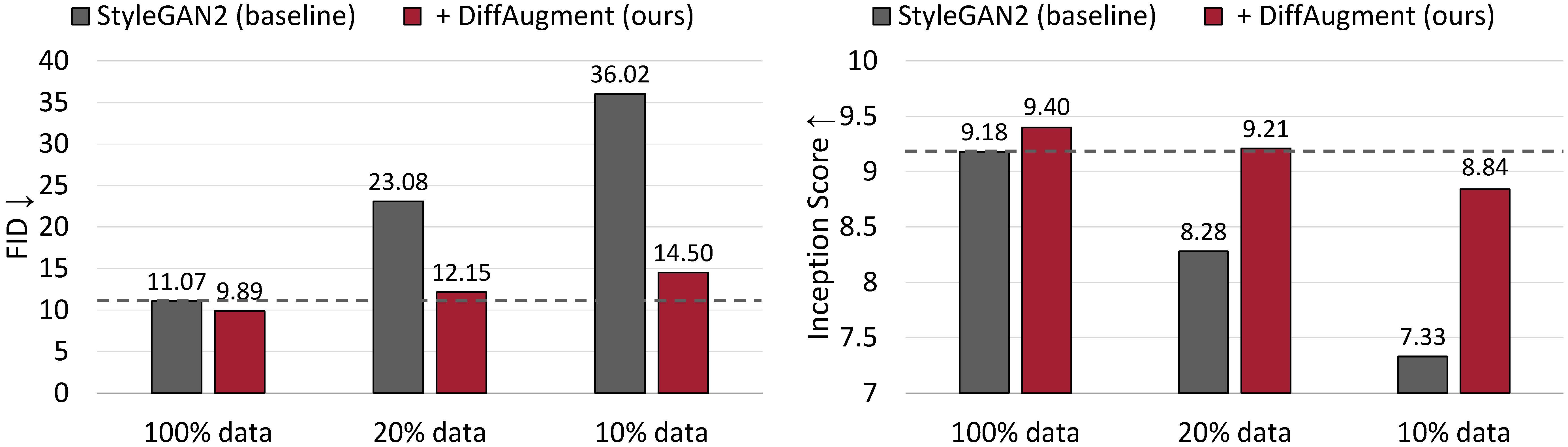
Résultats de la génération inconditionnelle sur CIFAR-10. Les performances de Stylegan2 se dégradent radicalement étant donné moins de données de formation. Avec le diffaugment, nous sommes en mesure de faire correspondre à peu près son FID et de surpasser son score de création (IS) en utilisant seulement 20% de données de formation.
Augmentation différenciable pour la formation GAN économe en données
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu et Song Han
MIT, Université de Tsinghua, Research Adobe, CMU
arxiv

Présentation du diffaugment pour la mise à jour de d (gauche) et g (à droite). Le diffaugment applique l'augmentation T à la fois à l'échantillon réel x et à la sortie générée G (Z). Lorsque nous mettons à jour G, les gradients doivent être rétro-propagés via t (iii), ce qui nécessite que t soit différenciable dans l'entrée.
Pour générer une vidéo d'interpolation à l'aide de nos modèles pré-formés:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gifou pour former un nouveau modèle:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4 Vous pouvez également essayer 100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen ou le dossier contenant vos propres images de formation. Veuillez vous référer à la lecture du diffaugment-stylegan2 pour les dépendances et les détails.
[Nouveau!] La formation Pytorch est maintenant disponible:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1Pour exécuter STYLEGAN2 + Diffaugment pour une génération inconditionnelle sur les ensembles de données à 100 coups, CIFAR, FFHQ ou LSUN, veuillez vous référer à la lecture du diffaugment-stylegan2 ou du diffaugment-stylegan2-pytorch pour la version Pytorch.
Veuillez vous référer au Diffaugment-Biggan-Cifar ReadMe pour exécuter Biggan + Diffaugment pour la génération conditionnelle sur CIFAR (en utilisant des GPU), et le Diffaugment-Biggan-Imagenet Readme pour fonctionner sur Imagenet (en utilisant des TPU).
Pour vous aider à utiliser le diffaugment dans votre propre base de code, nous fournissons des opérations de diffaument portables des versions TensorFlow et Pytorch dans diffaugment_tf.py et diffaugment_pytorch.py. Généralement, le diffaugment peut être facilement adopté dans n'importe quel modèle en substituant chaque d (x) par d (t (x)) , où x peut être des images réelles ou de fausses images, D est le discriminateur et T est l'opération de difficulté. Par exemple,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...Nous avons mis en œuvre le diffaument des couleurs, de la traduction et de la découpe comme visualisé ci-dessous:

Si vous trouvez ce code utile, veuillez citer notre article:
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
Nous remercions le NSF Career Award # 1943349, MIT-IBM Watson AI Lab, Google, Adobe et Sony pour avoir soutenu cette recherche. La recherche est soutenue avec les TPU cloud du cloud de recherche Tensorflow de Google (TFRC). Nous remercions William S. Peebles et Yijun Li pour les commentaires utiles.


