data efficient gans
1.0.0

สร้างขึ้นโดยใช้ภาพของโอบามาเพียง 100 ภาพแมวที่ไม่พอใจแพนด้าสะพานถอนหายใจน้ำพุเมดิชิวิหารแห่งสวรรค์โดยไม่ต้องฝึกอบรมล่วงหน้า
[ใหม่!] การฝึกอบรม Pytorch กับ Diffaugment-Stylegan2-Pytorch พร้อมให้บริการแล้ว!
[ใหม่!] การสอน colab ของเราได้รับการปล่อยตัว!
[ใหม่!] สนับสนุนการฝึกอบรม FFHQ! ดู readme สไตล์ Diffaugment
[ใหม่!] เวลาในการสร้างวิดีโอการแก้ไข 100-shot ด้วย generate_gif.py!
[ใหม่!] repo diffaugment-biggan-imagenet ของเรา (สำหรับการฝึกอบรม TPU) ได้รับการปล่อยตัว!
[ใหม่!] repo diffaugment-biggan-cifar pytorch ของเราได้รับการปล่อยตัว!
พื้นที่เก็บข้อมูลนี้มีการดำเนินการตามการเพิ่มความแตกต่าง (diffaugment) ของเราทั้งใน Pytorch และ Tensorflow สามารถใช้เพื่อปรับปรุงประสิทธิภาพข้อมูลสำหรับการฝึกอบรม GAN อย่างมีนัยสำคัญ เราได้จัดเตรียมรูปแบบ diffaugment (tensorflow) และ diffaugment-stylegan2-pytorch, diffaugment-biggan-cifar (pytorch) สำหรับการฝึกอบรม GPU และ diffaugment-biggan-imagenet (tensorflow) สำหรับการฝึกอบรม TPU

การถ่ายภาพต่ำโดยไม่ต้องฝึกอบรมล่วงหน้า ด้วย Diffaugment โมเดลของเราสามารถสร้างภาพความเที่ยงตรงสูงโดยใช้ภาพบุคคลโอบามาเพียง 100 ภาพแมวที่ไม่พอใจหรือแพนด้าจากชุดข้อมูล 100 นัดที่เรารวบรวมได้, แมว 160 ตัวหรือสุนัข 389 ตัวจากชุดข้อมูล Animalface ที่ความละเอียด 256 × 256
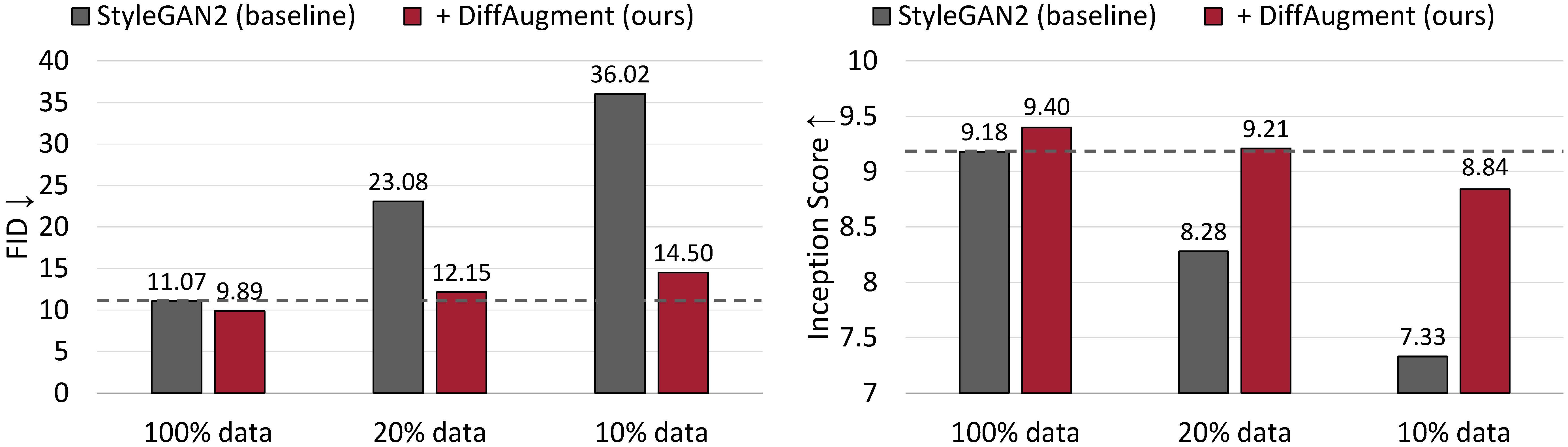
ผลการสร้างที่ไม่มีเงื่อนไขใน CIFAR-10 ประสิทธิภาพของ Stylegan2 ลดลงอย่างมากเนื่องจากข้อมูลการฝึกอบรมน้อยลง ด้วย Diffaugment เราสามารถจับคู่ FID และมีประสิทธิภาพสูงกว่าคะแนนการลงทะเบียน (IS) โดยใช้ข้อมูลการฝึกอบรมเพียง 20%
การเสริมที่แตกต่างกันสำหรับการฝึกอบรม GAN ที่ประหยัดข้อมูล
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu และ Song Han
MIT, มหาวิทยาลัย Tsinghua, Adobe Research, CMU
arxiv

ภาพรวมของ diffaugment สำหรับการอัปเดต d (ซ้าย) และ g (ขวา) Diffaugment ใช้การเพิ่ม t กับตัวอย่างจริง X และเอาต์พุต G (z) ที่สร้างขึ้น เมื่อเราอัปเดต G การไล่ระดับสีจะต้องกลับมาก่อนผ่าน t (iii) ซึ่งต้องการ t ที่จะแตกต่างกันได้
เพื่อสร้างวิดีโอการแก้ไขโดยใช้โมเดลที่ผ่านการฝึกอบรมมาก่อน:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gifหรือเพื่อฝึกอบรมรุ่นใหม่:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4 นอกจากนี้คุณยังสามารถลอง 100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen หรือโฟลเดอร์ที่มีภาพการฝึกอบรมของคุณเอง โปรดดู readme สไตล์ Diffaugment สำหรับการพึ่งพาและรายละเอียด
[ใหม่!] ตอนนี้การฝึกอบรม Pytorch มีอยู่แล้ว:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1ในการเรียกใช้ stylegan2 + diffaugment สำหรับการสร้างแบบไม่มีเงื่อนไขในชุดข้อมูล 100-shot, CIFAR, FFHQ หรือ LSUN โปรดดูที่ diffaugment-stylegan2 readme หรือ diffaugment-stylegan2-pytorch สำหรับรุ่น pytorch
โปรดดู diffaugment-biggan-cifar readme เพื่อเรียกใช้ biggan + diffaugment สำหรับการสร้างแบบมีเงื่อนไขบน cifar (ใช้ GPU) และ diffaugment-biggan-imagenet readme เพื่อทำงานบน Imagenet (โดยใช้ TPUs)
เพื่อช่วยให้คุณใช้ diffaugment ใน codebase ของคุณเองเราให้บริการการทำงานแบบพกพาแบบพกพาของทั้งรุ่น tensorflow และ pytorch ใน diffaugment_tf.py และ diffaugment_pytorch.py โดยทั่วไปการกระจายความแตกต่างสามารถนำมาใช้อย่างง่ายดายในแบบจำลองใด ๆ โดยการแทนที่ทุก d (x) ด้วย d (t (x)) โดยที่ x สามารถเป็นภาพจริงหรือภาพปลอม d คือ discriminator และ t คือการดำเนินการ diffaugment ตัวอย่างเช่น,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...เราได้ใช้สีการแปลและการคัตเอาท์ diffaugment ดังที่แสดงให้เห็นด้านล่าง:

หากคุณพบว่ารหัสนี้มีประโยชน์โปรดอ้างอิงกระดาษของเรา:
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
เราขอขอบคุณ NSF Career Award #1943349, MIT-IBM Watson AI Lab, Google, Adobe และ Sony สำหรับการสนับสนุนการวิจัยนี้ การวิจัยสนับสนุนด้วยคลาวด์ TPU จาก Cloud Tensorflow Research Cloud (TFRC) ของ Google เราขอขอบคุณ William S. Peebles และ Yijun Li สำหรับความคิดเห็นที่เป็นประโยชน์


