data efficient gans
1.0.0

オバマ、不機嫌そうな猫、パンダ、ため息の橋、メディチ噴水、天国の神殿の100枚の画像のみを使用して生成されました。
[New!] Diffaugment-Stylegan2-Pytorchを使用したPytorchトレーニングが利用可能になりました!
[新しい!] Colabチュートリアルがリリースされました!
[New!] FFHQトレーニングがサポートされています! diffaugment-stylegan2 readmeを参照してください。
[新しい!] Generate_gif.pyで100ショットの補間ビデオを生成する時間!
[New!] Diffaugment-Biggan-Imagenet Repo(TPUトレーニング用)がリリースされました!
[NEW!] Diffaugment-Biggan-Cifar Pytorch Repoがリリースされました!
このリポジトリには、PytorchとTensorflowの両方での微分可能な増強(拡散)の実装が含まれています。 GANトレーニングのデータ効率を大幅に改善するために使用できます。 diffaugment-stylegan2(Tensorflow)およびdiffaugment-stylegan2-pytorch、GPUトレーニングのためにdiffaugment-biggan-cifar(pytorch)、およびTPUトレーニングにdiffaugment-biggan-imagenet(tensorflow)を提供しました。

トレーニング前の低ショット生成。違いにより、私たちのモデルは、収集された100ショットデータセット、160匹の猫、または256×256解像度で389匹の犬から100個のオバマポートレート、不機嫌な猫、またはパンダを使用して、忠実度の高い画像を生成できます。
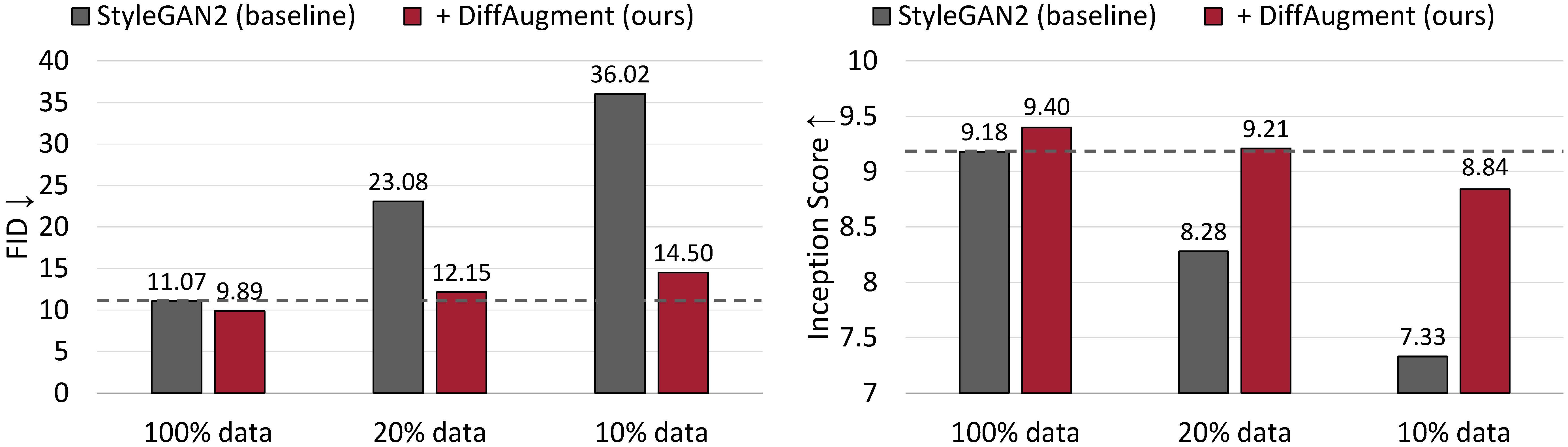
CIFAR-10での無条件の生成結果。 StyleGan2のパフォーマンスは、トレーニングデータが少ないと劇的に劣化します。 Diffaugmentを使用すると、FIDを大まかに一致させ、 20%のトレーニングデータのみを使用して開始スコア(IS)を上回ることができます。
データ効率の良いGANトレーニングのための微分可能な増強
Shengyu Zhao、Zhijian Liu、Ji Lin、Jun-Yan Zhu、Song Han
MIT、Tsinghua University、Adobe Research、CMU
arxiv

d(左)とg(右)を更新するためのdiffaugmentの概要。拡散は、実際のサンプルxと生成された出力g(z)の両方に増強tを適用します。 Gを更新するとき、勾配はt(iii)を介して戻る必要があります。これには、入力を微分可能にする必要があります。
事前に訓練されたモデルを使用して補間ビデオを生成するには:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gifまたは新しいモデルをトレーニングするには:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4また、 100-shot-grumpy_cat 、 100-shot-panda 、 100-shot-bridge_of_sighs 、 100-shot-medici_fountain 、 100-shot-temple_of_heaven 、 100-shot-wuzhen 、または独自のトレーニング画像を含むフォルダーを試すこともできます。依存関係と詳細については、diffaugment-stylegan2 readmeを参照してください。
[新しい!] Pytorchトレーニングが利用可能になりました:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1100ショットデータセット、CIFAR、FFHQ、またはLSUNでの無条件の生成のStyleGan2 +拡散を実行するには、pytorchバージョンのdiffaugment-stylegan2 readmeまたはdiffaugment-stylegan2-pytorchを参照してください。
diffaugment-biggan-cifar readmeを参照して、cifar(gpusを使用)で条件付き生成のためにBiggan + diffaugmentを実行し、diffaugment-biggan-imagenet readmeはimagenet(TPUを使用)で実行します。
独自のコードベースで拡散を使用するのを支援するために、diffaugment_tf.pyおよびdiffaugment_pytorch.pyのTensorflowバージョンとPytorchバージョンの両方のポータブル拡散操作を提供します。一般に、すべてのd(x)をd(t(x))に置き換えることにより、任意のモデルで拡散を簡単に採用できます。ここで、 xは実際の画像または偽の画像であり、 dは識別子であり、 tは拡散操作です。例えば、
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...以下で視覚化されているように、色、翻訳、切り抜きの拡散を実装しました。

このコードが役立つ場合は、私たちの論文を引用してください。
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
NSFキャリアアワード#1943349、MIT-IBM Watson AI Lab、Google、Adobe、およびSonyがこの研究をサポートしてくれたことに感謝します。 GoogleのTensorflow Research Cloud(TFRC)のクラウドTPUでサポートされている研究。有益なコメントをしてくれたWilliam S. PeeblesとYijun Liに感謝します。


