data efficient gans
1.0.0

오바마, 심술쟁이 고양이, 팬더, 한숨, 메디치 분수, 하늘의 성전, 사전 훈련 없이만 100 개의 이미지를 사용하여 생성되었습니다.
[New!] Diffaugment-StyleGan2-Pytorch를 사용한 Pytorch 교육이 가능합니다!
[New!] Colab 튜토리얼이 출시되었습니다!
[NEW!] FFHQ 교육이 지원됩니다! diffaugment-stylegan2 readme를 참조하십시오.
[New!] Generate_gif.py와 함께 100 샷 보간 비디오를 생성 할 시간!
[New!] 우리의 Diffaugment-Biggan-Imagenet Repo (TPU 교육을위한)가 출시되었습니다!
[New!] Diffaugment-Biggan-Cifar Pytorch Repo가 출시되었습니다!
이 저장소에는 Pytorch 및 Tensorflow에서 차별화 가능한 증강 (Diffaugment)의 구현이 포함되어 있습니다. GAN 교육의 데이터 효율성을 크게 향상시키는 데 사용될 수 있습니다. 우리는 Diffaugment-StyleGan2 (Tensorflow) 및 diffaugment-stylegan2-pytorch, GPU 훈련을위한 Diffaugment-biggan-cifar (pytorch) 및 TPU 훈련을위한 확산-비가 간-이마 게넷 (Tensorflow)을 제공했습니다.

사전 훈련없이 샷 생성. Diffaugment를 사용하여 우리의 모델은 100 개의 오바마 초상화, 심술 궂은 고양이 또는 팬더를 수집 한 100 샷 데이터 세트, 160 마리의 고양이 또는 389 마리의 개를 사용하여 256 × 256 해상도로 고 충실도 이미지를 생성 할 수 있습니다.
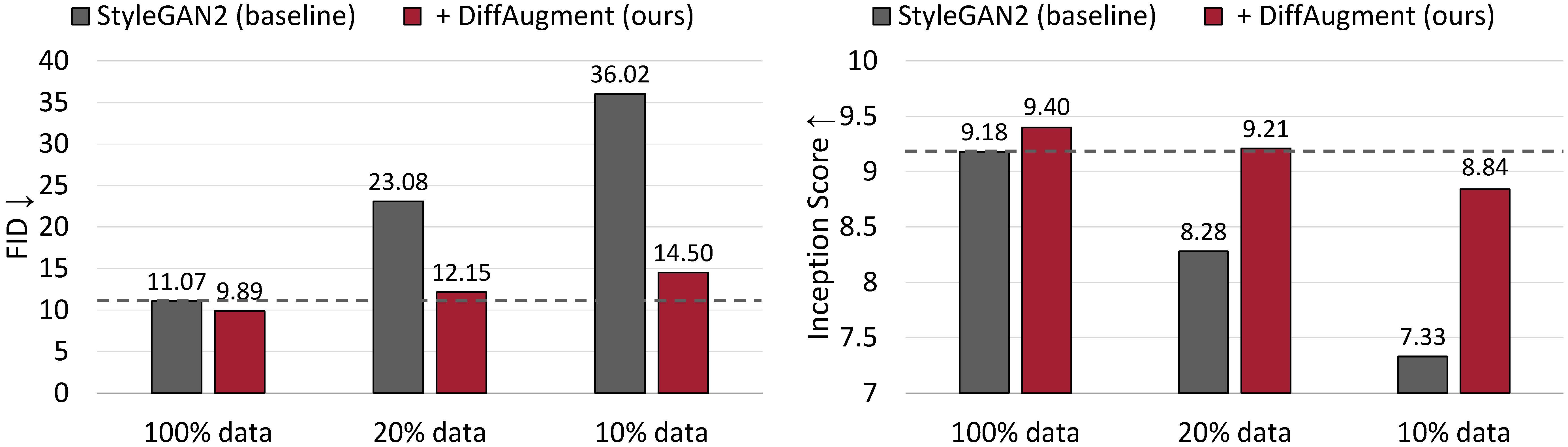
CIFAR-10에 대한 무조건 생성 결과. Stylegan2의 성능은 훈련 데이터가 적은 경우 크게 저하됩니다. Diffaugment를 사용하면 FID와 대략 20%의 교육 데이터 만 사용하여 Inception 점수 (IS)를 능가 할 수 있습니다.
데이터 효율적인 GAN 교육을위한 차별화 가능한 증강
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu 및 Song Han
MIT, Tsinghua University, Adobe Research, CMU
arxiv

D (왼쪽) 및 g (오른쪽)를 업데이트하기위한 Diffaugment 개요. 확산은 증강 t를 실제 샘플 x와 생성 된 출력 g (z) 모두에 적용합니다. G를 업데이트 할 때 Gradients는 t (III)를 통해 역전을 가져와야하며, 이는 t가 입력을 차별화 할 수 있어야합니다.
미리 훈련 된 모델을 사용하여 보간 비디오를 생성하려면 :
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gif또는 새로운 모델을 훈련시키기 위해 :
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4 또한 100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen 또는 자체 교육 이미지가 포함 된 폴더를 사용해 볼 수도 있습니다. 종속성 및 세부 사항은 Diffaugment-StyleGan2 Readme를 참조하십시오.
[New!] Pytorch Training을 사용할 수 있습니다.
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1100- 샷 데이터 세트, Cifar, FFHQ 또는 LSUN에서 무조건 생성에 대한 StyleGan2 + Diffaugment를 실행하려면 Pytorch 버전의 Diffaugment-StyleGan2 readme 또는 Diffaugment-StyleGan2-Pytorch를 참조하십시오.
CIFAR (GPU 사용)에서 조건부 생성을 위해 Biggan + Diffaugment를 실행하려면 Diffaugment-Biggan-Cifar Readme 및 Diffaugment-Biggan-Imagenet readme (TPU를 사용하여)를 실행하려면 Diffaugment-Biggan-Cifar Readme을 참조하십시오.
자신의 코드베이스에서 Diffaugment를 사용하기 위해 Diffaugment_tf.py 및 diffaugment_pytorch.py에서 Tensorflow 및 Pytorch 버전의 휴대용 확산 작업을 제공합니다. 일반적으로, 모든 d (x)를 d (t (x) 로 대체함으로써 모든 모델에서 확산을 쉽게 채택 할 수 있으며, 여기서 x 는 실제 이미지 또는 가짜 이미지, d 는 판별 자이고, t는 차이 작업입니다. 예를 들어,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...아래 시각화 된 색상, 번역 및 컷 아웃 확산을 구현했습니다.

이 코드가 도움이되면 논문을 인용하십시오.
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
이 연구를 지원해 주신 NSF Career Award #1943349, MIT-IBM Watson AI Lab, Google, Adobe 및 Sony에게 감사드립니다. Google의 Tensorflow Research Cloud (TFRC)의 Cloud TPU를 지원하는 연구. 유용한 의견에 대해 William S. Peebles와 Yijun Li에게 감사드립니다.


