data efficient gans
1.0.0

Generado usando solo 100 imágenes de Obama, gatos gruñones, pandas, el puente de los suspiros, la fuente Medici, el Templo del Cielo, sin prioridad.
[¡NUEVO!] ¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡ ¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡
[¡NUEVO!] Nuestro tutorial de Colab se lanzó!
[¡NUEVO!] La capacitación FFHQ es compatible! Vea el readMe de Diffaugment-StyleGan2.
[¡NUEVO!] Tiempo para generar videos de interpolación de 100 disparos con Generate_GIF.py!
[¡NUEVO!] Nuestro repositorio de difamación-Biggan-iMagenet (para capacitación en TPU) se lanza!
[¡NUEVO!] Nuestro repositorio de Diffaugment-Biggan-Cifar Pytorch se lanza!
Este repositorio contiene nuestra implementación del aumento diferenciable (difusión) tanto en Pytorch como en TensorFlow. Se puede utilizar para mejorar significativamente la eficiencia de los datos para el entrenamiento de GaN. Hemos proporcionado Diffaugment-StyleGan2 (TensorFlow) y Diffaugment-StyleGan2-Pytorch, Diffaugment-Biggan-Cifar (Pytorch) para el entrenamiento de GPU y Diffaugment-Biggan-Imagenet (Tensorflow) para el entrenamiento de TPU.

Generación de bajo disparo sin pre-entrenamiento. Con la difusión, nuestro modelo puede generar imágenes de alta fidelidad utilizando solo 100 retratos de Obama, gatos gruñones o pandas de nuestros conjuntos de datos de 100 disparos recopilados, 160 gatos o 389 perros del conjunto de datos Animalface a una resolución 256 × 256.
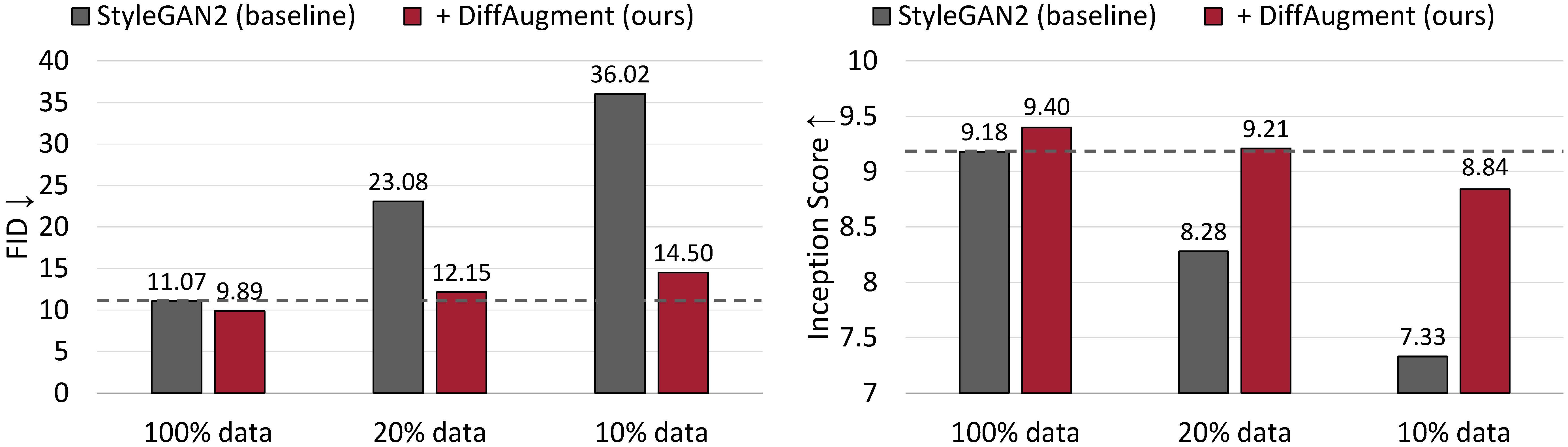
Resultados de generación incondicional en CIFAR-10. El rendimiento de StyleGan2 se degrada drásticamente con menos datos de entrenamiento. Con la difusión, podemos igualar aproximadamente su FID y superar su puntaje de inicio (es) utilizando solo el 20% de datos de entrenamiento.
Aumento diferenciable para la capacitación de GaN eficiente en datos
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu y Song Han
MIT, Universidad de Tsinghua, Adobe Research, CMU
arxiv

Descripción general de la difusión para actualizar D (izquierda) y G (derecha). La difusión aplica el aumento t tanto a la muestra real X como a la salida generada G (z). Cuando actualizamos G, los gradientes deben ser propagados a través de T (III), lo que requiere que T sea diferenciable WRT la entrada.
Para generar un video de interpolación utilizando nuestros modelos previamente capacitados:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gifo para entrenar un nuevo modelo:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4 También puede probar 100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen , o la carpeta que contiene sus propias imágenes de entrenamiento. Consulte el ReadMe de DiffAugment-StyleGan2 para las dependencias y los detalles.
[¡NUEVO!] Entrenamiento de Pytorch ya está disponible:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1Para ejecutar Diffaugment de StyleGan2 + para la generación incondicional en los conjuntos de datos de 100 disparos, CIFAR, FFHQ o LSUN, consulte el Diffaugment-StyleGan2 ReadMe o Diffaugment-Stylegan2-Pytorch para la versión Pytorch.
Consulte el Readme de difunto-Biggan-Cifar para ejecutar Biggan + Diffaugment para la generación condicional en CIFAR (usando GPU), y el Readme de Diffaugment-Biggan-IMagenet para ejecutar ImageNet (usando TPUS).
Para ayudarlo a utilizar la difusión en su propia base de código, proporcionamos operaciones de diferencia portátiles de las versiones TensorFlow y Pytorch en Diffaugment_tf.py y Diffaugment_Pytorch.py. En general, la difusión se puede adoptar fácilmente en cualquier modelo sustituyendo cada d (x) con d (t (x)) , donde x puede ser imágenes reales o imágenes falsas, D es el discriminador, y t es la operación de difusión. Por ejemplo,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...Hemos implementado el color, la traducción y la difusión de recorte como se visualiza a continuación:

Si encuentra útil este código, cite nuestro documento:
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
Agradecemos al NSF Carrerae Award #1943349, MIT-IBM Watson AI Lab, Google, Adobe y Sony por apoyar esta investigación. Investigación respaldada con TPUS de la nube de TensorFlow Research Cloud (TFRC) de Google. Agradecemos a William S. Peebles y Yijun Li por sus útiles comentarios.


