data efficient gans
1.0.0

Dihasilkan hanya menggunakan 100 gambar Obama, kucing pemarah, panda, jembatan desahan, air mancur Medici, kuil surga, tanpa pra-pelatihan.
[Baru!] Pelatihan Pytorch dengan Diffaugment-Stylegan2-Pytorch sekarang tersedia!
[Baru!] Tutorial Colab kami dirilis!
[Baru!] Pelatihan FFHQ didukung! Lihat readme difaugment-stylegan2.
[Baru!] Waktu untuk menghasilkan video interpolasi 100-shot dengan generate_gif.py!
[Baru!] Repo Diffaugment-Biggan-Imagenet kami (untuk pelatihan TPU) dirilis!
[Baru!] Repo Pytorch Diffaugment-Biggan-Cifar kami dirilis!
Repositori ini berisi implementasi augmentasi yang dapat dibedakan (difaugment) di Pytorch dan TensorFlow. Ini dapat digunakan untuk secara signifikan meningkatkan efisiensi data untuk pelatihan GAN. Kami telah memberikan difaugment-stylegan2 (TensorFlow) dan Diffaugment-Stylegan2-Pytorch, Diffaugment-Biggan-Cifar (Pytorch) untuk pelatihan GPU, dan Diffaugment-Biggan-Imagenet (TensorFlow) untuk pelatihan TPU.

Generasi low-shot tanpa pra-pelatihan. Dengan difaugment, model kami dapat menghasilkan gambar kesetiaan tinggi hanya menggunakan 100 potret Obama, kucing pemarah, atau panda dari dataset 100-shot kami yang dikumpulkan, 160 kucing atau 389 anjing dari dataset Animalface pada resolusi 256 × 256.
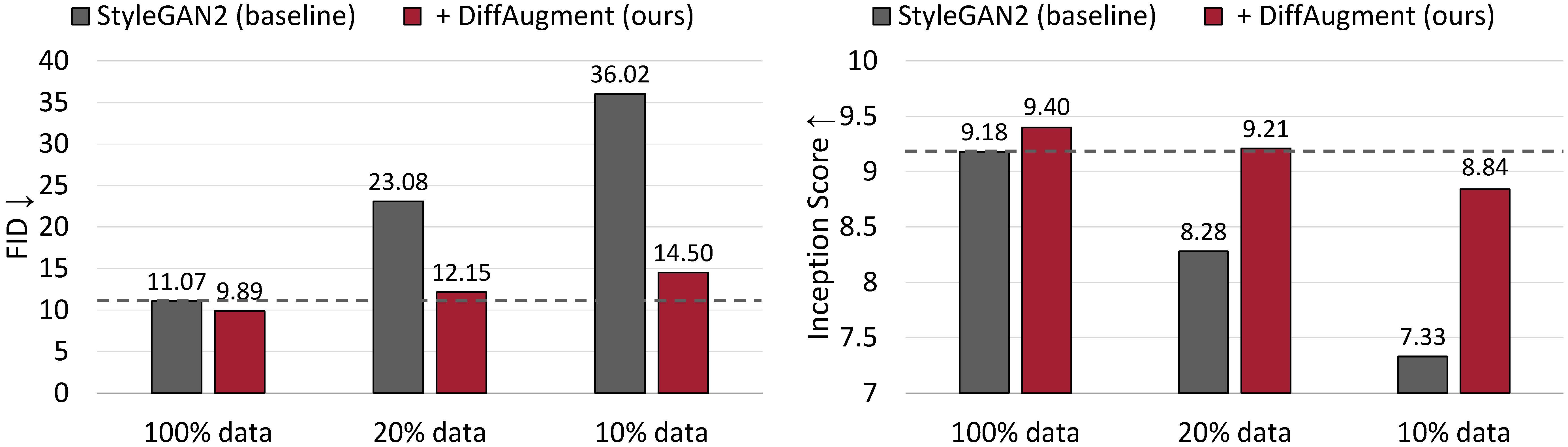
Hasil generasi tanpa syarat pada CIFAR-10. Kinerja StyleGan2 menurun secara drastis mengingat lebih sedikit data pelatihan. Dengan difaugment, kami dapat secara kasar mencocokkan FID dan mengungguli skor awalnya (IS) hanya menggunakan 20% data pelatihan.
Augmentasi yang dapat dibedakan untuk pelatihan GAN yang efisien data
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu, dan Song Han
MIT, Universitas Tsinghua, Penelitian Adobe, CMU
arxiv

Tinjauan difaugment untuk memperbarui d (kiri) dan g (kanan). Diffaugment menerapkan augmentasi t untuk sampel nyata x dan output g (z) yang dihasilkan. Saat kami memperbarui G, gradien harus dipropagasi kembali melalui T (III), yang mengharuskan T untuk menjadi perbedaan input.
Untuk menghasilkan video interpolasi menggunakan model pra-terlatih kami:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gifatau untuk melatih model baru:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4 Anda juga dapat mencoba 100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen , atau folder yang berisi gambar pelatihan Anda sendiri. Silakan merujuk ke Diffaugment-Stylegan2 Readme untuk dependensi dan detail.
[Baru!] Pelatihan Pytorch sekarang tersedia:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1Untuk menjalankan Diffaugment StyleGan2 + untuk generasi tanpa syarat pada dataset 100-shot, CIFAR, FFHQ, atau LSUN, silakan merujuk ke Diffaugment-Stylegan2 ReadMe atau Diffaugment-Stylegan2-PyTorch untuk versi Pytorch.
Silakan merujuk ke Diffaugment-Biggan-Cifar ReadMe untuk menjalankan Biggan + Diffaugment untuk generasi bersyarat pada CIFAR (menggunakan GPU), dan readme difaugment-Biggan-Imagenet untuk dijalankan di ImageNet (menggunakan TPU).
Untuk membantu Anda menggunakan difaugment dalam basis kode Anda sendiri, kami menyediakan operasi diffaugment portabel dari versi TensorFlow dan Pytorch dalam difaugment_tf.py dan difaugment_pytorch.py. Secara umum, difaugment dapat dengan mudah diadopsi dalam model apa pun dengan mengganti setiap d (x) dengan d (t (x)) , di mana x dapat menjadi gambar nyata atau gambar palsu, D adalah diskriminator, dan T adalah operasi difaugment. Misalnya,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...Kami telah mengimplementasikan warna, terjemahan, dan diffaugment potongan seperti yang divisualisasikan di bawah ini:

Jika Anda menemukan kode ini bermanfaat, silakan kutip kertas kami:
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
Kami berterima kasih kepada NSF Career Award #1943349, MIT-IBM Watson AI Lab, Google, Adobe, dan Sony untuk mendukung penelitian ini. Penelitian yang didukung dengan Cloud TPU dari Google TensorFlow Research Cloud (TFRC). Kami berterima kasih kepada William S. Peebles dan Yijun Li atas komentar yang bermanfaat.


