poolformer
1.0.0
我们的后续工作“视觉元基准基线”(代码:元拟合器)介绍了更多的元法基准,包括
这是我们的论文“元构造者实际上是您所需要的”(CVPR 2022口服)提出的池形成器的pytorch实现。
注意:这项工作的目标不是设计复杂的令牌搅拌机以实现SOTA性能,而是证明变压器模型的能力在很大程度上源于一般体系结构元元素。汇总/泳池形式只是支持我们主张的工具。
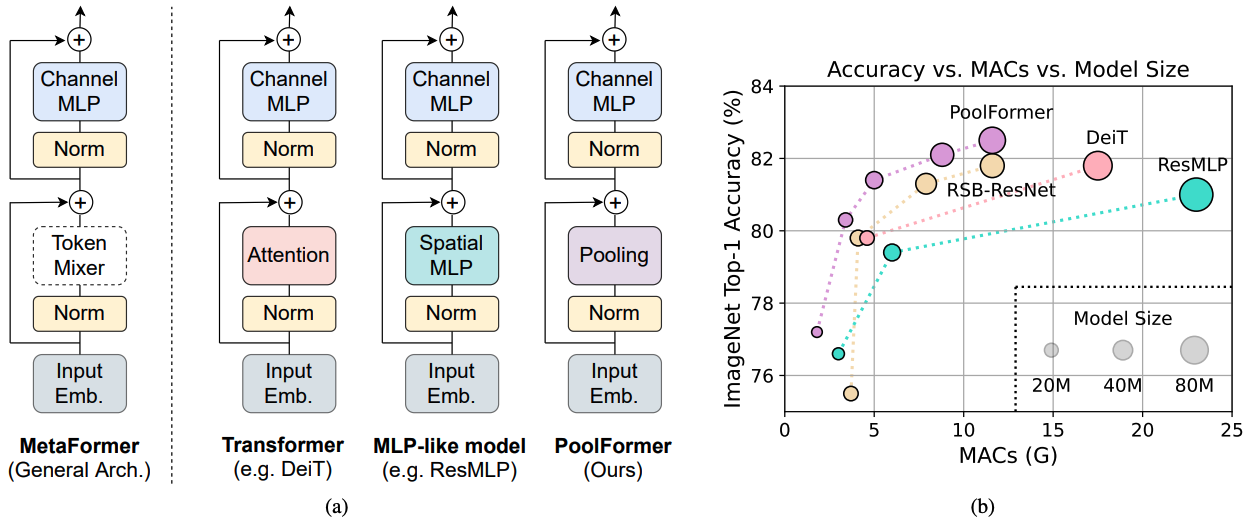 图1: Imagenet-1K验证集上基于元图的模型的元图和性能。我们认为,变压器/MLP样模型的能力主要源于一般体系结构元构造器,而不是配备的特定令牌混合器。为了证明这一点,我们利用了一个令人尴尬的简单非参数操作员汇总,以进行极为基本的令牌混合。令人惊讶的是,所得的模型池形成器始终胜过(b)所示的DEIT和RESMLP,这很好地支持了Metaformer实际上是我们实现竞争性能所需的。 (b)中的rsb-resnet表示结果来自“重新打击”,其中重新网络通过改进的300个时期的训练程序进行了训练。
图1: Imagenet-1K验证集上基于元图的模型的元图和性能。我们认为,变压器/MLP样模型的能力主要源于一般体系结构元构造器,而不是配备的特定令牌混合器。为了证明这一点,我们利用了一个令人尴尬的简单非参数操作员汇总,以进行极为基本的令牌混合。令人惊讶的是,所得的模型池形成器始终胜过(b)所示的DEIT和RESMLP,这很好地支持了Metaformer实际上是我们实现竞争性能所需的。 (b)中的rsb-resnet表示结果来自“重新打击”,其中重新网络通过改进的300个时期的训练程序进行了训练。
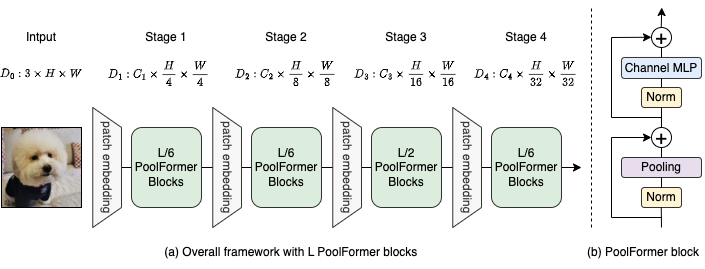
图2:(a)池形成器的整体框架。 (b)泳池形式块的体系结构。与变压器块相比,它用非常简单的非参数操作员(合并)来取代注意力,以仅进行基本的令牌混合。
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
可可配置和训练有素的模型上的检测和实例细分在这里。
ADE20K配置和训练有素的模型上的语义细分在这里。
可视化游泳位,DEIT,RESMLP,RESNET和SWIN的GRAD-CAM激活图的代码在这里。
测量Mac的代码在这里。
火炬> = 1.7.0;火炬> = 0.8.0; pyyaml; APEX-AMP(如果要使用FP16); timm( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
数据准备:具有以下文件夹结构的Imagenet,您可以通过此脚本提取成像网。
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| 模型 | #params | 图像分辨率 | #MAC* | top1 acc | 下载 |
|---|---|---|---|---|---|
| POOMFORMER_S12 | 12m | 224 | 1.8克 | 77.2 | 这里 |
| POOLFORMER_S24 | 21m | 224 | 3.4克 | 80.3 | 这里 |
| POOMFORMER_S36 | 31m | 224 | 5.0g | 81.4 | 这里 |
| POOLFORMER_M36 | 56m | 224 | 8.8克 | 82.1 | 这里 |
| POOMFORMER_M48 | 73m | 224 | 11.6g | 82.5 | 这里 |
所有审慎的型号也可以通过Baidu Yun(密码:ESAC)下载。 *为了方便地与未来模型进行比较,我们更新了FVCore库(示例代码)计数的Mac数量,这些数字也在新的Arxiv版本中报告。
集成到拥抱面空间?使用Gradio。尝试网络演示:
我们还提供了一个COLAB笔记本,该笔记本运行了与PoolFormer执行推理的步骤:
为了评估我们的泳池形式模型,请运行:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint 我们展示了如何在8 GPU上培训泳池形式。学习率与批处理大小之间的关系是LR = BS/1024*1E-3。为了方便起见,假设批处理大小为1024,则将学习率设置为1E-3(批次大小为1024,将学习率定为2E-3有时会看到更好的性能)。
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp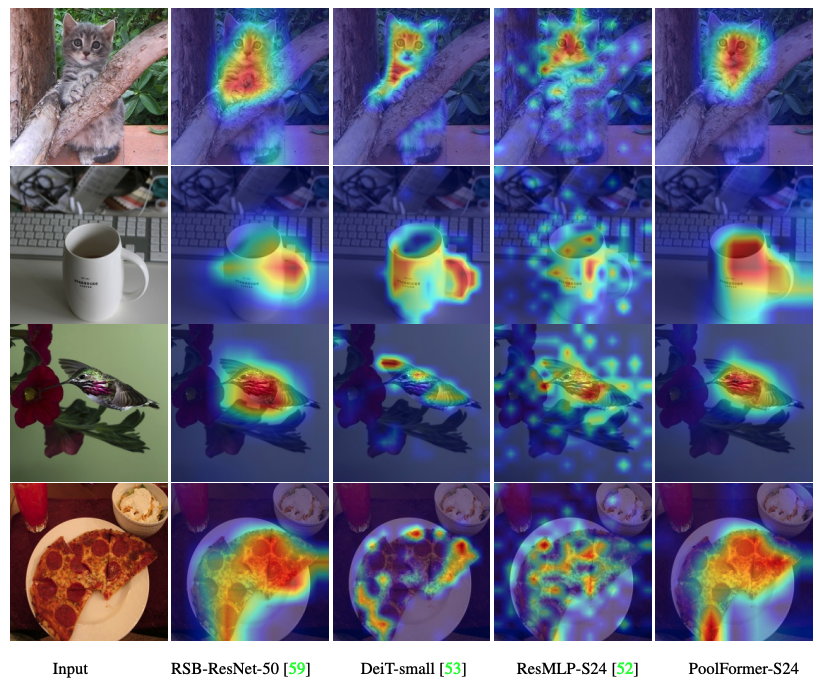
可视化游泳位,DEIT,RESMLP,RESNET和SWIN的GRAD-CAM激活图的代码在这里。
我们的实施主要基于以下代码库。我们非常感谢作者的精彩作品。
pytorch-image模型,mmdetection,mmmevementation。
此外,Weihao Yu要感谢TPU研究云(TRC)计划的支持部分计算资源。


