poolformer
1.0.0
Nosso trabalho de acompanhamento "Metaformer Baselines for Vision" (Code: Metaformer) apresenta mais linhas de base metaformadas, incluindo
Esta é uma implementação do Poolformer proposta pelo nosso artigo "Metaformer é realmente o que você precisa para a visão" (CVPR 2022 oral).
NOTA : Em vez de projetar o misturador de token complicado para alcançar o desempenho do SOTA, o alvo deste trabalho é demonstrar a competência dos modelos de transformadores em grande parte decorrente do metaformador de arquitetura geral. Pooling/Poolformer são apenas as ferramentas para apoiar nossa reivindicação.
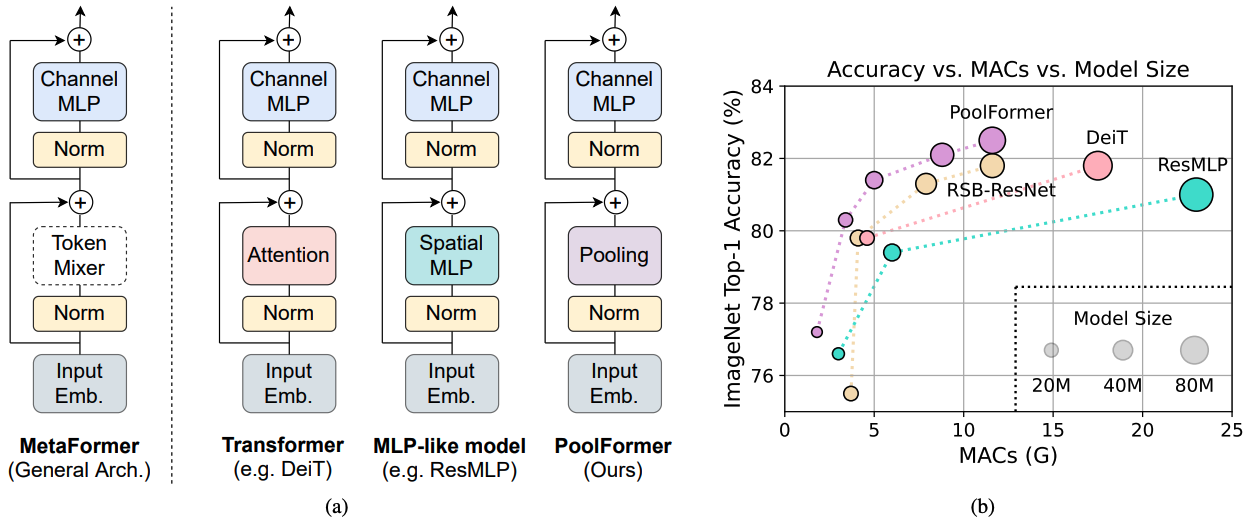 Figura 1: Metaformer e desempenho de modelos baseados em metaformadores no conjunto de validação ImageNet-1K. Argumentamos que a competência dos modelos do tipo transformador/MLP resulta principalmente do metaformador de arquitetura geral em vez dos misturadores de token específicos equipados. Para demonstrar isso, exploramos um operador não paramétrico embaraçosamente simples, agrupando, para realizar uma mistura de token extremamente básica. Surpreendentemente, o modelo de modelo de modelo resultante supera consistentemente o DEIT e o RESMLP, conforme mostrado em (B), que suporta bem que o Metaformer é realmente o que precisamos para obter um desempenho competitivo. RSB-RESNET em (b) significa que os resultados são de “RESNET GRATES DE VOLTA”, onde a resnet é treinada com um procedimento de treinamento aprimorado para 300 épocas.
Figura 1: Metaformer e desempenho de modelos baseados em metaformadores no conjunto de validação ImageNet-1K. Argumentamos que a competência dos modelos do tipo transformador/MLP resulta principalmente do metaformador de arquitetura geral em vez dos misturadores de token específicos equipados. Para demonstrar isso, exploramos um operador não paramétrico embaraçosamente simples, agrupando, para realizar uma mistura de token extremamente básica. Surpreendentemente, o modelo de modelo de modelo resultante supera consistentemente o DEIT e o RESMLP, conforme mostrado em (B), que suporta bem que o Metaformer é realmente o que precisamos para obter um desempenho competitivo. RSB-RESNET em (b) significa que os resultados são de “RESNET GRATES DE VOLTA”, onde a resnet é treinada com um procedimento de treinamento aprimorado para 300 épocas.
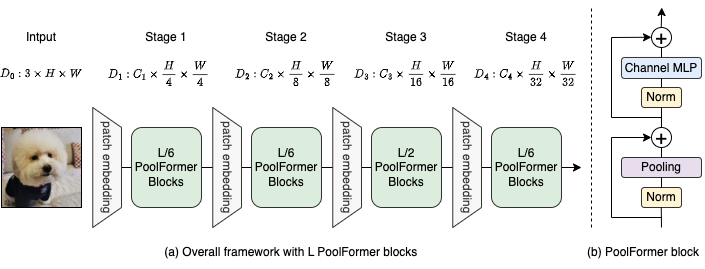
Figura 2: (a) A estrutura geral do Poolformer. (b) A arquitetura do bloco de formas de pool. Comparado ao bloco de transformadores, ele substitui a atenção por um operador não paramétrico extremamente simples, em pool, para realizar apenas a mistura básica de token.
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
A segmentação de detecção e instância em configurações de Coco e modelos treinados estão aqui.
Segmentação semântica em configurações Ade20K e modelos treinados estão aqui.
O código para visualizar mapas de ativação de pós-câmeras de Poolfomer, Deit, Resmlp, Resnet e Swin estão aqui.
O código para medir os Macs está aqui.
tocha> = 1.7.0; Torchvision> = 0,8,0; Pyyaml; APEX-AMP (se você deseja usar FP16); timm ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
Dados Prepare: ImageNet Com a seguinte estrutura de pastas, você pode extrair o ImageNet por este script.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| Modelo | #Params | Resolução da imagem | #Macs* | Top1 acc | Download |
|---|---|---|---|---|---|
| PoolFormer_S12 | 12m | 224 | 1.8g | 77.2 | aqui |
| PoolFormer_S24 | 21m | 224 | 3.4G | 80.3 | aqui |
| PoolFormer_S36 | 31m | 224 | 5.0g | 81.4 | aqui |
| PoolFormer_M36 | 56m | 224 | 8.8g | 82.1 | aqui |
| PoolFormer_M48 | 73m | 224 | 11.6g | 82.5 | aqui |
Todos os modelos pré -tenhados também podem ser baixados por Baidu Yun (senha: ESAC). * Para uma comparação conveniente com modelos futuros, atualizamos o número de Macs contados pela FVCORE Library (código de exemplo), que também são relatados na nova versão do ARXIV.
Integrado aos espaços Huggingface? Usando Gradio. Experimente a demonstração da web:
Também fornecemos um notebook Colab que executa as etapas para executar a inferência no Poolformer:
Para avaliar nossos modelos de formas de pool, execute:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint Mostramos como treinar formas de pool em 8 GPUs. A relação entre a taxa de aprendizagem e o tamanho do lote é LR = BS/1024*1E-3. Por conveniência, assumindo que o tamanho do lote é 1024, a taxa de aprendizado é definida como 1E-3 (para o tamanho do lote de 1024, definindo a taxa de aprendizado como 2e-3 às vezes vê melhor desempenho).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp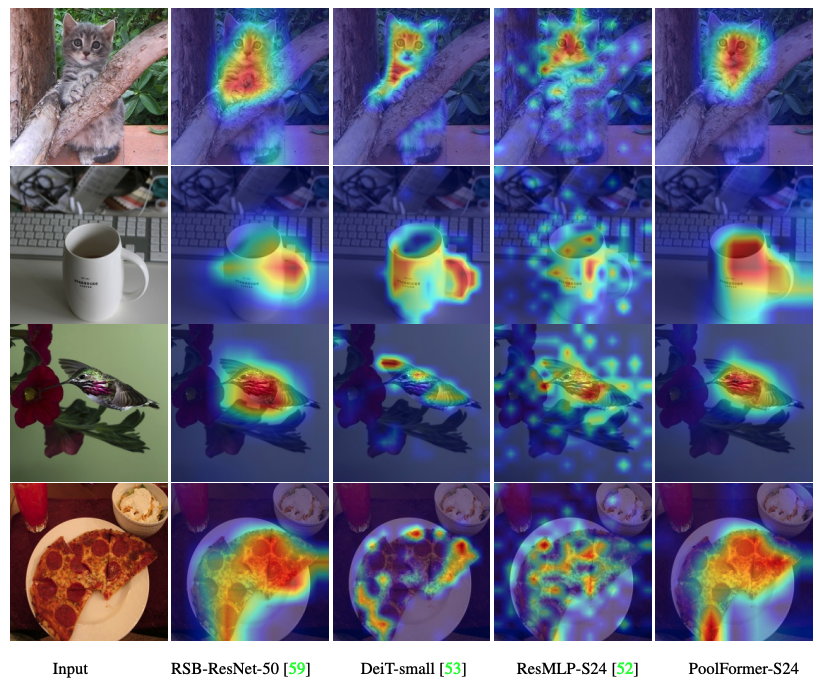
O código para visualizar mapas de ativação de pós-câmeras de Poolfomer, Deit, Resmlp, Resnet e Swin estão aqui.
Nossa implementação é baseada principalmente nas seguintes bases de código. Agradecemos com gratidão aos autores por seus maravilhosos trabalhos.
Modelos Pytorch-Image, MmDetection, Mmsegmentation.
Além disso, Weihao Yu gostaria de agradecer ao programa TPU Research Cloud (TRC) pelo apoio de recursos computacionais parciais.


