poolformer
1.0.0
Notre travail de suivi "MetaFormer Baslines for Vision" (Code: Metaformer) présente plus
Il s'agit d'une implémentation Pytorch de PoolFormer proposé par notre article "Metaformer est en fait ce dont vous avez besoin pour la vision" (CVPR 2022 oral).
Remarque : Au lieu de concevoir un mélangeur de jetons compliqué pour atteindre les performances SOTA, la cible de ce travail est de démontrer que la compétence des modèles de transformateurs provient largement du métaformateur d'architecture générale. La mise en commun / poolFormer n'est que les outils pour soutenir notre affirmation.
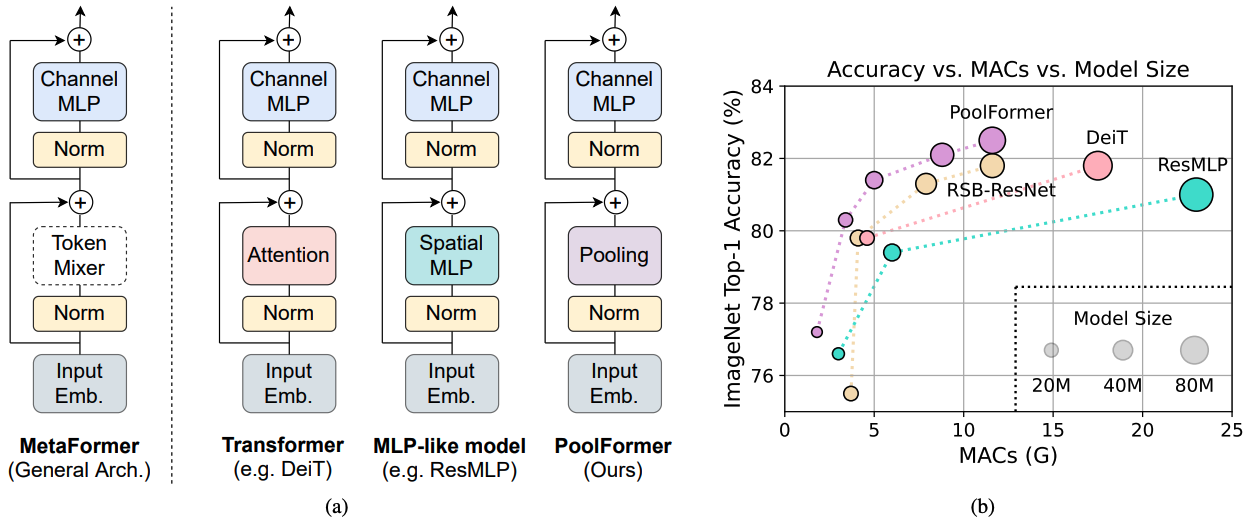 Figure 1: Métaformateur et performances des modèles basés sur des métaformateurs sur l'ensemble de validation ImageNet-1k. Nous soutenons que la compétence des modèles de transformateur / MLP provient principalement du métaformateur de l'architecture générale au lieu des mélangeurs de jeton spécifiques équipés. Pour le démontrer, nous exploitons un opérateur non paramétrique embarrassant de façon embarrassante, la mise en commun, pour mener un mélange de jetons extrêmement basique. Étonnamment, le modèle de PoolFormer résultant surtoutait constamment le Deit et le RESMLP comme indiqué en (b), qui soutient bien que le métaformateur est en fait ce dont nous avons besoin pour obtenir des performances compétitives. RSB-Resnet dans (b) signifie que les résultats proviennent de «Resnet Strikes Back» où Resnet est formé avec une procédure de formation améliorée pour 300 époques.
Figure 1: Métaformateur et performances des modèles basés sur des métaformateurs sur l'ensemble de validation ImageNet-1k. Nous soutenons que la compétence des modèles de transformateur / MLP provient principalement du métaformateur de l'architecture générale au lieu des mélangeurs de jeton spécifiques équipés. Pour le démontrer, nous exploitons un opérateur non paramétrique embarrassant de façon embarrassante, la mise en commun, pour mener un mélange de jetons extrêmement basique. Étonnamment, le modèle de PoolFormer résultant surtoutait constamment le Deit et le RESMLP comme indiqué en (b), qui soutient bien que le métaformateur est en fait ce dont nous avons besoin pour obtenir des performances compétitives. RSB-Resnet dans (b) signifie que les résultats proviennent de «Resnet Strikes Back» où Resnet est formé avec une procédure de formation améliorée pour 300 époques.
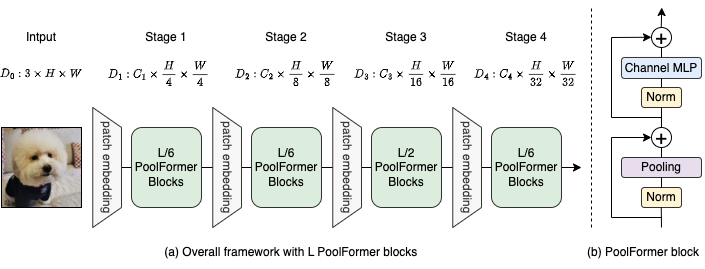
Figure 2: (a) Le cadre global de PoolFormer. (b) L'architecture du bloc PoolFormer. Comparé au bloc de transformateur, il remplace l'attention par un opérateur non paramétrique extrêmement simple, la mise en commun, pour mener uniquement le mélange de jetons de base.
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
La détection et la segmentation des instances sur les configurations de coco et les modèles formés sont là.
La segmentation sémantique sur les configurations ADE20K et les modèles formés est là.
Le code pour visualiser les cartes d'activation de Grad-CAM de PoolFomer, Deit, Resmlp, Resnet et Swin est ici.
Le code pour mesurer les Mac est là.
torche> = 1,7,0; TorchVision> = 0,8,0; pyyaml; APEX-AMP (si vous souhaitez utiliser FP16); Timm ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
Données Préparez: ImageNet avec la structure du dossier suivant, vous pouvez extraire ImageNet par ce script.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| Modèle | #Params | Résolution d'image | # Macs * | TOP1 ACC | Télécharger |
|---|---|---|---|---|---|
| poolFormer_S12 | 12m | 224 | 1,8 g | 77.2 | ici |
| PoolFormer_S24 | 21m | 224 | 3,4 g | 80.3 | ici |
| poolFormer_S36 | 31m | 224 | 5,0 g | 81.4 | ici |
| poolFormer_M36 | 56m | 224 | 8,8 g | 82.1 | ici |
| PoolFormer_M48 | 73m | 224 | 11,6g | 82.5 | ici |
Tous les modèles pré-entraînés peuvent également être téléchargés par Baidu Yun (mot de passe: ESAC). * Pour une comparaison pratique avec les futurs modèles, nous mettons à jour les nombres de Mac comptés par la bibliothèque FVCore (exemple de code) qui sont également signalés dans la nouvelle version ArXIV.
Intégré dans les espaces de câlins? Utilisation de Gradio. Essayez la démo Web:
Nous fournissons également un cahier Colab qui exécute les étapes pour effectuer l'inférence avec PoolFormer:
Pour évaluer nos modèles PoolFormer, exécutez:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint Nous montrons comment former des formateurs de pool sur 8 GPU. La relation entre le taux d'apprentissage et la taille du lot est LR = BS / 1024 * 1E-3. Pour plus de commodité, en supposant que la taille du lot est de 1024, alors le taux d'apprentissage est défini comme 1E-3 (pour la taille du lot de 1024, la définition du taux d'apprentissage comme 2E-3 voit parfois de meilleures performances).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp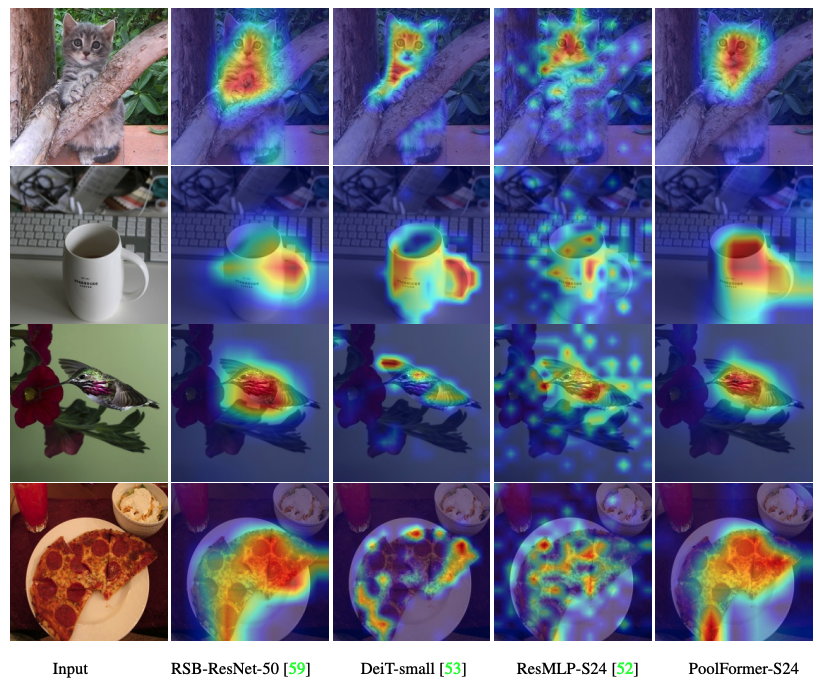
Le code pour visualiser les cartes d'activation de Grad-CAM de PoolFomer, Deit, Resmlp, Resnet et Swin est ici.
Notre implémentation est principalement basée sur les bases de code suivantes. Nous remercions avec reconnaissance les auteurs pour leurs merveilleuses œuvres.
Pytorch-Image-Models, MMDection, mmsegmentation.
En outre, Weihao Yu tient à remercier le programme TPU Research Cloud (TRC) pour le soutien des ressources de calcul partiels.


