poolformer
1.0.0
Pekerjaan tindak lanjut kami "Metaformer Baselines for Vision" (Code: Metaformer) memperkenalkan lebih banyak baselin Metaformer termasuk
Ini adalah implementasi Pytorch dari poolformer yang diusulkan oleh makalah kami "Metaformer sebenarnya adalah apa yang Anda butuhkan untuk penglihatan" (CVPR 2022 oral).
Catatan : Alih -alih merancang mixer token yang rumit untuk mencapai kinerja SOTA, target dari pekerjaan ini adalah untuk menunjukkan kompetensi model transformator yang sebagian besar berasal dari Metaformer arsitektur umum. Pooling/Poolformer hanyalah alat untuk mendukung klaim kami.
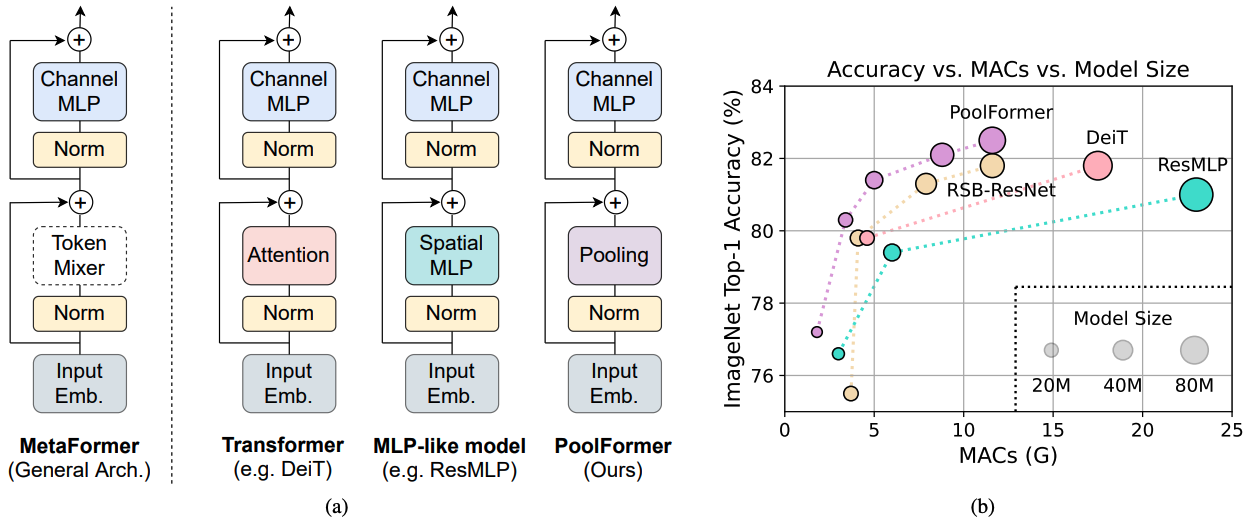 Gambar 1: Metaformer dan kinerja model berbasis MetaFormer pada set validasi ImageNet-1K. Kami berpendapat bahwa kompetensi model transformator/MLP terutama berasal dari arsitektur umum Metaformer alih-alih mixer token spesifik yang dilengkapi. Untuk menunjukkan hal ini, kami mengeksploitasi operator non-parametrik yang sangat sederhana, menggabungkan, untuk melakukan pencampuran token yang sangat mendasar. Anehnya, model yang dihasilkan poolformer secara konsisten mengungguli deit dan resmlp seperti yang ditunjukkan pada (b), yang mendukung sumur bahwa Metaformer sebenarnya adalah apa yang kita butuhkan untuk mencapai kinerja kompetitif. RSB-resnet dalam (b) berarti hasilnya berasal dari “Resnet Strikes Back” di mana ResNet dilatih dengan prosedur pelatihan yang lebih baik untuk 300 zaman.
Gambar 1: Metaformer dan kinerja model berbasis MetaFormer pada set validasi ImageNet-1K. Kami berpendapat bahwa kompetensi model transformator/MLP terutama berasal dari arsitektur umum Metaformer alih-alih mixer token spesifik yang dilengkapi. Untuk menunjukkan hal ini, kami mengeksploitasi operator non-parametrik yang sangat sederhana, menggabungkan, untuk melakukan pencampuran token yang sangat mendasar. Anehnya, model yang dihasilkan poolformer secara konsisten mengungguli deit dan resmlp seperti yang ditunjukkan pada (b), yang mendukung sumur bahwa Metaformer sebenarnya adalah apa yang kita butuhkan untuk mencapai kinerja kompetitif. RSB-resnet dalam (b) berarti hasilnya berasal dari “Resnet Strikes Back” di mana ResNet dilatih dengan prosedur pelatihan yang lebih baik untuk 300 zaman.
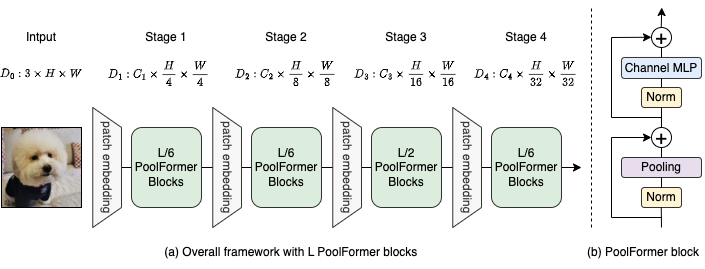
Gambar 2: (a) Kerangka kerja keseluruhan dari poolformer. (B) Arsitektur Blok Poolformer. Dibandingkan dengan Transformer Block, ia menggantikan perhatian dengan operator non-parametrik yang sangat sederhana, menggabungkan, untuk hanya melakukan pencampuran token dasar.
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
Deteksi dan segmentasi instan pada konfigurasi coco dan model terlatih ada di sini.
Segmentasi semantik pada konfigurasi ADE20K dan model terlatih ada di sini.
Kode untuk memvisualisasikan peta aktivasi lulusan poolfomer, deit, resmlp, resnet dan swin ada di sini.
Kode untuk mengukur Mac ada di sini.
obor> = 1.7.0; TorchVision> = 0.8.0; pyyaml; Apex-amp (jika Anda ingin menggunakan FP16); Timm ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
Data Persiapan: Imagenet dengan struktur folder berikut, Anda dapat mengekstrak Imagenet dengan skrip ini.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| Model | #Params | Resolusi gambar | #Mac* | Top1 Acc | Unduh |
|---|---|---|---|---|---|
| poolformer_s12 | 12m | 224 | 1.8g | 77.2 | Di Sini |
| poolformer_s24 | 21m | 224 | 3.4g | 80.3 | Di Sini |
| poolformer_s36 | 31m | 224 | 5.0g | 81.4 | Di Sini |
| poolformer_m36 | 56m | 224 | 8.8g | 82.1 | Di Sini |
| poolformer_m48 | 73m | 224 | 11.6g | 82.5 | Di Sini |
Semua model pretrain juga dapat diunduh oleh Baidu Yun (kata sandi: ESAC). * Untuk perbandingan yang nyaman dengan model masa depan, kami memperbarui jumlah Mac yang dihitung oleh FVCore Library (contoh kode) yang juga dilaporkan dalam versi ARXIV baru.
Terintegrasi ke dalam ruang pelukan? menggunakan gradio. Cobalah demo web:
Kami juga menyediakan notebook Colab yang menjalankan langkah -langkah untuk melakukan inferensi dengan poolformer:
Untuk mengevaluasi model poolformer kami, jalankan:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint Kami menunjukkan cara melatih poolformers di 8 GPU. Hubungan antara tingkat pembelajaran dan ukuran batch adalah LR = BS/1024*1E-3. Untuk kenyamanan, dengan asumsi ukuran batch adalah 1024, maka tingkat pembelajaran ditetapkan sebagai 1E-3 (untuk ukuran batch 1024, menetapkan tingkat pembelajaran sebagai 2E-3 kadang-kadang melihat kinerja yang lebih baik).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp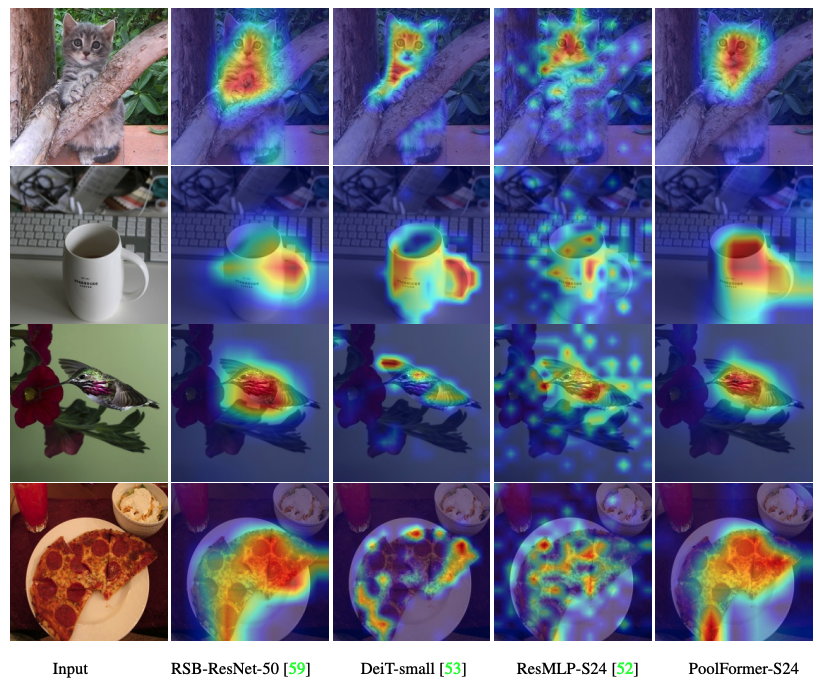
Kode untuk memvisualisasikan peta aktivasi lulusan poolfomer, deit, resmlp, resnet dan swin ada di sini.
Implementasi kami terutama didasarkan pada basis kode berikut. Kami berterima kasih kepada penulis atas karya -karya mereka yang luar biasa.
Model pytorch-image, mmdetection, mmsmegmentation.
Selain itu, Weihao Yu ingin mengucapkan terima kasih kepada program TPU Research Cloud (TRC) atas dukungan dari sumber daya komputasi parsial.


