poolformer
1.0.0
우리의 후속 작업 "Vision for Vision"(Code : Metaformer)은
이것은 우리의 논문에서 제안한 풀 포머 의 Pytorch 구현입니다.
참고 : SOTA 성능을 달성하기 위해 복잡한 토큰 믹서를 설계하는 대신,이 작업의 목표는 변압기 모델의 역량을 대부분 일반 아키텍처 메타 양식에서 비롯된 것입니다. Pooling/Poolformer는 우리의 주장을 뒷받침하는 도구 일뿐입니다.
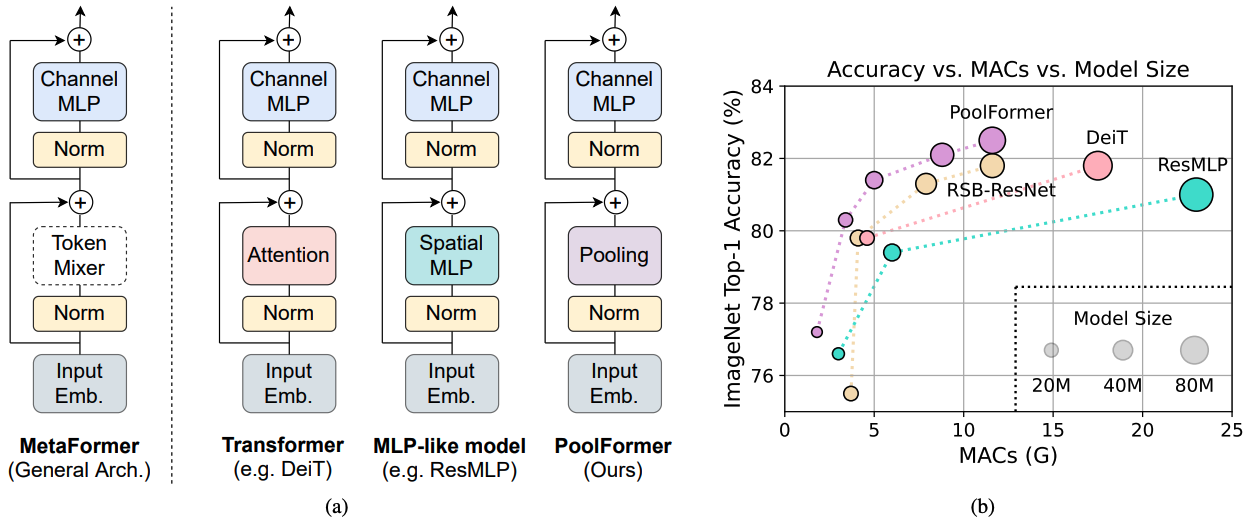 그림 1 : ImageNet-1K 유효성 검사 세트에 대한 메타 포머 기반 모델의 메타 포머 및 성능. 우리는 트랜스포머/MLP와 같은 모델의 역량이 주로 장착 된 특정 토큰 믹서 대신 일반 아키텍처 메타 구성서에서 비롯된 것이라고 주장합니다. 이를 입증하기 위해, 우리는 매우 기본적인 토큰 믹싱을 수행하기 위해 당황스럽고 간단한 비모수 조작자 인 풀링을 이용합니다. 놀랍게도, 결과적으로 모델 풀 포머는 (b)와 같이 DEIT 및 RESMLP보다 지속적으로 성능이 우수하며, 이는 메타 포머가 실제로 경쟁력있는 성능을 달성하는 데 필요한 것임을 잘 지원합니다. (b)의 RSB-Resnet은 결과가 300 개의 에포크에 대한 교육 절차가 향상된“RESNET Strikes Back”의 결과를 의미합니다.
그림 1 : ImageNet-1K 유효성 검사 세트에 대한 메타 포머 기반 모델의 메타 포머 및 성능. 우리는 트랜스포머/MLP와 같은 모델의 역량이 주로 장착 된 특정 토큰 믹서 대신 일반 아키텍처 메타 구성서에서 비롯된 것이라고 주장합니다. 이를 입증하기 위해, 우리는 매우 기본적인 토큰 믹싱을 수행하기 위해 당황스럽고 간단한 비모수 조작자 인 풀링을 이용합니다. 놀랍게도, 결과적으로 모델 풀 포머는 (b)와 같이 DEIT 및 RESMLP보다 지속적으로 성능이 우수하며, 이는 메타 포머가 실제로 경쟁력있는 성능을 달성하는 데 필요한 것임을 잘 지원합니다. (b)의 RSB-Resnet은 결과가 300 개의 에포크에 대한 교육 절차가 향상된“RESNET Strikes Back”의 결과를 의미합니다.
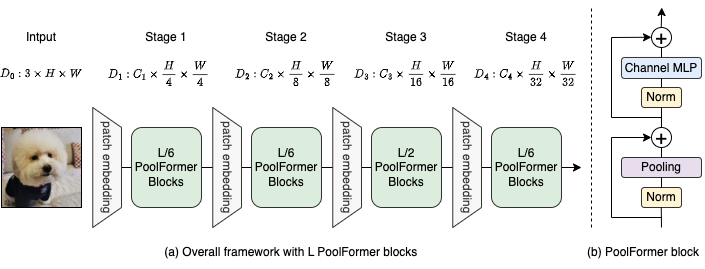
그림 2 : (a) 풀 포폼의 전체 프레임 워크. (b) 풀 포폼 블록의 아키텍처. Transformer 블록과 비교하여 기본 토큰 믹싱 만 수행하기 위해 매우 간단한 비모수 연산자 인 Pooling으로주의를 대체합니다.
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
Coco 구성 및 훈련 된 모델의 탐지 및 인스턴스 분할이 여기에 있습니다.
ADE20K 구성 및 훈련 된 모델의 시맨틱 세분화가 여기에 있습니다.
Poofolomer, DEIT, RESMLP, RESNET 및 SWIN의 Grad-CAM 활성화 맵을 시각화하는 코드가 여기에 있습니다.
Mac을 측정하기위한 코드는 여기에 있습니다.
토치> = 1.7.0; Torchvision> = 0.8.0; pyyaml; Apex-AMP (FP16을 사용하려는 경우); TIMM ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
데이터 준비 : Imagenet 다음 폴더 구조를 사용하면이 스크립트로 Imagenet을 추출 할 수 있습니다.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| 모델 | #Params | 이미지 해상도 | #MACS* | Top1 Acc | 다운로드 |
|---|---|---|---|---|---|
| PoolFormer_S12 | 12m | 224 | 1.8g | 77.2 | 여기 |
| PoolFormer_S24 | 21m | 224 | 3.4g | 80.3 | 여기 |
| PoolFormer_S36 | 31m | 224 | 5.0g | 81.4 | 여기 |
| Poolformer_M36 | 56m | 224 | 8.8g | 82.1 | 여기 |
| PoolFormer_M48 | 73m | 224 | 11.6g | 82.5 | 여기 |
사전 예방 된 모든 모델은 Baidu Yun (Password : ESAC)에서 다운로드 할 수도 있습니다. * 향후 모델과 편리하게 비교하기 위해, 우리는 새로운 ARXIV 버전 에보 고 된 FVCore 라이브러리 (예제 코드)가 계산 한 MAC의 수를 업데이트합니다.
포옹 페이스 공간에 통합 되었습니까? Gradio 사용. 웹 데모를 시도해보십시오.
우리는 또한 풀 폼과 함께 추론을 수행하기위한 단계를 실행하는 Colab 노트북을 제공합니다.
풀폼 모델을 평가하려면 실행하십시오.
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint 우리는 8 GPU에서 풀 포폼을 훈련시키는 방법을 보여줍니다. 학습 속도와 배치 크기의 관계는 LR = BS/1024*1E-3입니다. 편의를 위해 배치 크기가 1024라고 가정하면 학습 속도는 1E-3으로 설정됩니다 (배치 크기 1024의 경우 2E-3이 때때로 학습 속도를 더 나은 성능을 볼 수 있으므로 학습 속도를 설정합니다).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp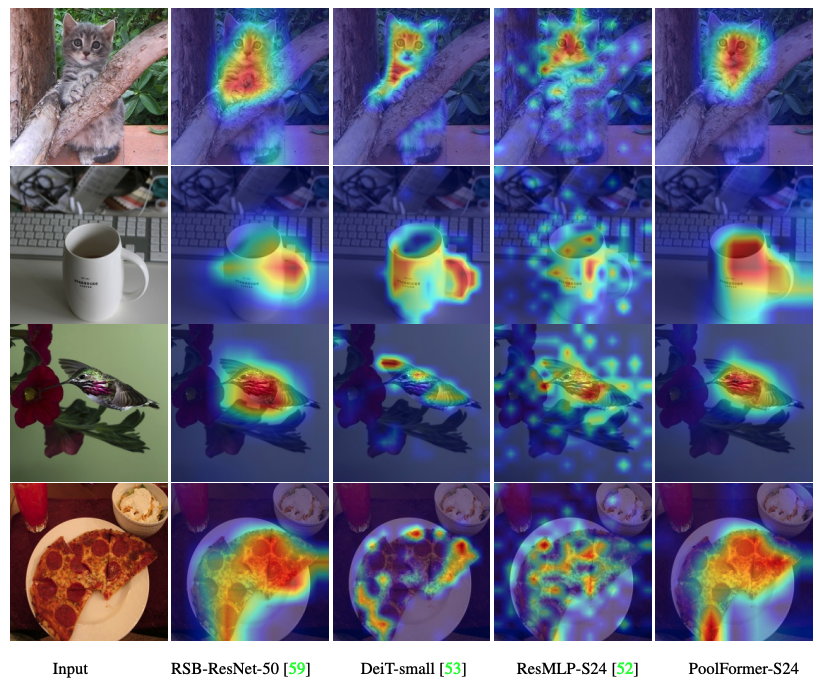
Poofolomer, DEIT, RESMLP, RESNET 및 SWIN의 Grad-CAM 활성화 맵을 시각화하는 코드가 여기에 있습니다.
우리의 구현은 주로 다음 코드베이스를 기반으로합니다. 우리는 훌륭한 작품에 대해 저자들에게 감사하게 감사합니다.
Pytorch-Image 모델, mmdetection, mmsementation.
또한 Weihao Yu는 부분 계산 리소스 지원에 대한 TPU Research Cloud (TRC) 프로그램에 감사의 말씀을 전합니다.


