poolformer
1.0.0
フォローアップ作業「Vision For VisionのMetaformer Baselines」(Code:Metaformer)は、より多くのメタフォーザーベースラインを紹介します。
これは、私たちの論文「Metaformerは実際にはビジョンに必要なものです」(CVPR 2022 Oral)によって提案されたPoolformerのPytorchの実装です。
注:SOTAパフォーマンスを実現するために複雑なトークンミキサーを設計する代わりに、この作業のターゲットは、一般的なアーキテクチャメタフォーマーから主に生じるトランスモデルの能力を実証することです。プーリング/プールフォーマーは、当社の主張をサポートするためのツールにすぎません。
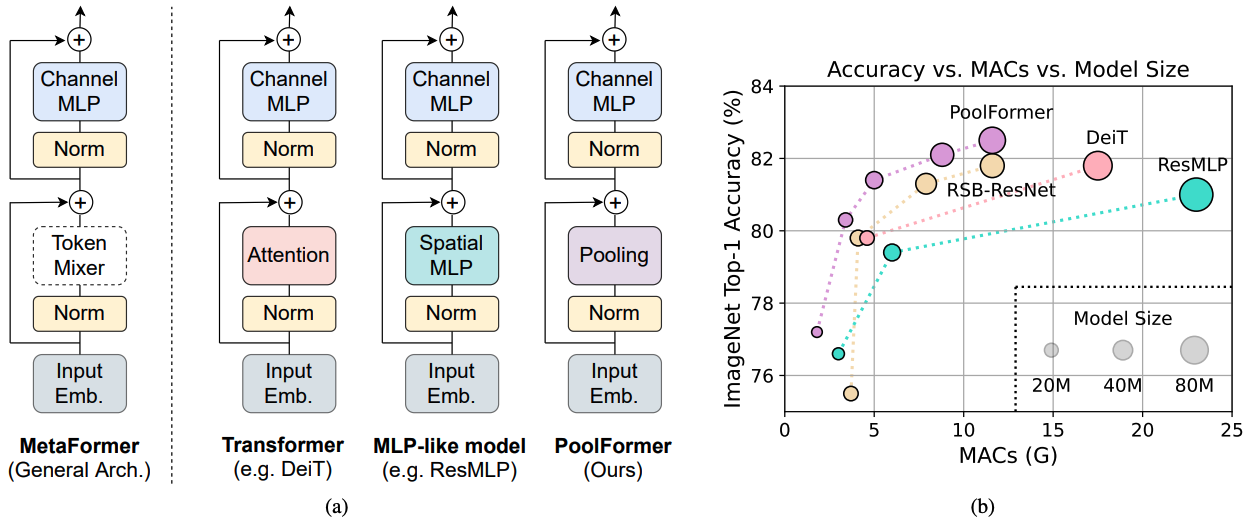 図1: ImagENET-1K検証セット上のメタフォーマーベースのモデルのメタフォーマーとパフォーマンス。トランス/MLP様モデルの能力は、主に装備された特定のトークンミキサーの代わりに一般的なアーキテクチャメタフォーザーに由来すると主張します。これを実証するために、恥ずかしいほどシンプルなノンパラメトリックオペレーターであるプールを活用して、非常に基本的なトークンミキシングを実施します。驚くべきことに、結果のモデルプールフォーマーは、(b)に示すように、一貫してDEITとRESMLPを上回ります。 (b)のRSB-Resnetは、ResNetが300エポックの改善されたトレーニング手順でトレーニングされている「Resnet Strikes Back」からの結果であることを意味します。
図1: ImagENET-1K検証セット上のメタフォーマーベースのモデルのメタフォーマーとパフォーマンス。トランス/MLP様モデルの能力は、主に装備された特定のトークンミキサーの代わりに一般的なアーキテクチャメタフォーザーに由来すると主張します。これを実証するために、恥ずかしいほどシンプルなノンパラメトリックオペレーターであるプールを活用して、非常に基本的なトークンミキシングを実施します。驚くべきことに、結果のモデルプールフォーマーは、(b)に示すように、一貫してDEITとRESMLPを上回ります。 (b)のRSB-Resnetは、ResNetが300エポックの改善されたトレーニング手順でトレーニングされている「Resnet Strikes Back」からの結果であることを意味します。
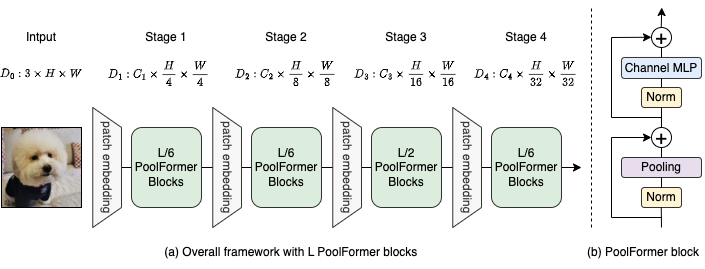
図2:(a)プールフォーマーの全体的なフレームワーク。 (b)プールフォーマーブロックのアーキテクチャ。トランスブロックと比較して、基本的なトークン混合のみを実施するために、非常にシンプルなノンパラメトリック演算子のプーリングに注意を置き換えます。
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
COCO構成と訓練されたモデルの検出とインスタンスセグメンテーションはこちらです。
ADE20K構成とトレーニングモデルのセマンティックセグメンテーションはこちらです。
POOLFOMER、DEIT、RESMLP、RESNET、SWINのグラッカムアクティベーションマップを視覚化するコードがここにあります。
Macを測定するためのコードはこちらです。
トーチ> = 1.7.0; TorchVision> = 0.8.0; pyyaml; apex-amp(FP16を使用する場合); TIMM( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
データの準備:次のフォルダー構造を使用したImagenetでは、このスクリプトでImagenetを抽出できます。
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| モデル | #params | 画像解像度 | #macs* | TOP1 ACC | ダウンロード |
|---|---|---|---|---|---|
| poolformer_s12 | 12m | 224 | 1.8g | 77.2 | ここ |
| poolformer_s24 | 21m | 224 | 3.4g | 80.3 | ここ |
| poolformer_s36 | 31m | 224 | 5.0g | 81.4 | ここ |
| poolformer_m36 | 56m | 224 | 8.8g | 82.1 | ここ |
| poolformer_m48 | 73m | 224 | 11.6g | 82.5 | ここ |
すべての前のモデルは、Baidu Yun(パスワード:ESAC)によってダウンロードすることもできます。 *将来のモデルとの便利な比較のために、新しいARXIVバージョンでも報告されているFVCoreライブラリ(サンプルコード)でカウントされるMacの数を更新します。
ハギングフェイススペースに統合されていますか?グラデーションの使用。 Webデモを試してみてください:
また、プールフォーマーとの推論を実行する手順を実行するコラブノートブックも提供しています。
プールフォーマーモデルを評価するには、実行してください。
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint 8つのGPUでプールフォーマーを訓練する方法を示します。学習率とバッチサイズの関係は、LR = BS/1024*1E-3です。便利な場合、バッチサイズが1024であると仮定すると、学習率は1E-3として設定されます(1024のバッチサイズの場合、学習率は2E-3がより良いパフォーマンスを見ることがあります)。
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp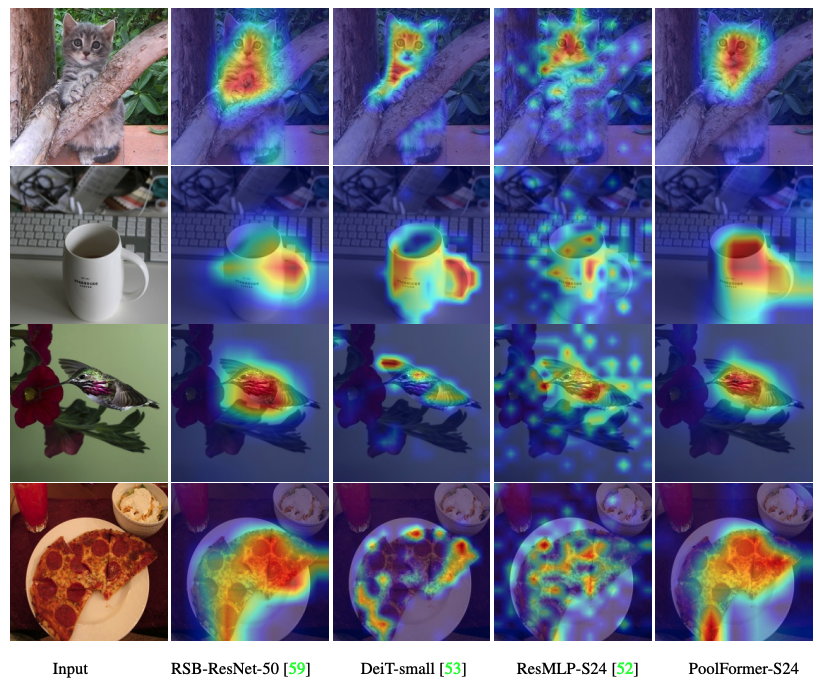
POOLFOMER、DEIT、RESMLP、RESNET、SWINのグラッカムアクティベーションマップを視覚化するコードがここにあります。
私たちの実装は、主に次のコードベースに基づいています。著者の素晴らしい作品に感謝します。
Pytorch-Image-Models、mmdetection、mmsegmentation。
また、Weihao Yuは、部分的な計算リソースのサポートについてTPU Research Cloud(TRC)プログラムに感謝したいと思います。


