poolformer
1.0.0
تقدم عملنا "Metaformer BaseLines for Vision" (الكود: MetaFormer) المزيد من خطوط الأساس التلوي بما في ذلك
هذا هو تطبيق Pytorch لـ Poolformer الذي اقترحه ورقيتنا "Metaformer هو في الواقع ما تحتاجه للرؤية" (CVPR 2022 عن طريق الفم).
ملاحظة : بدلاً من تصميم الخلاط الرمزي المعقد لتحقيق أداء SOTA ، فإن الهدف من هذا العمل هو إظهار كفاءة نماذج المحولات إلى حد كبير من النمو العام للعمارة العامة. التجميع/poolformer هي مجرد أدوات لدعم مطالبنا.
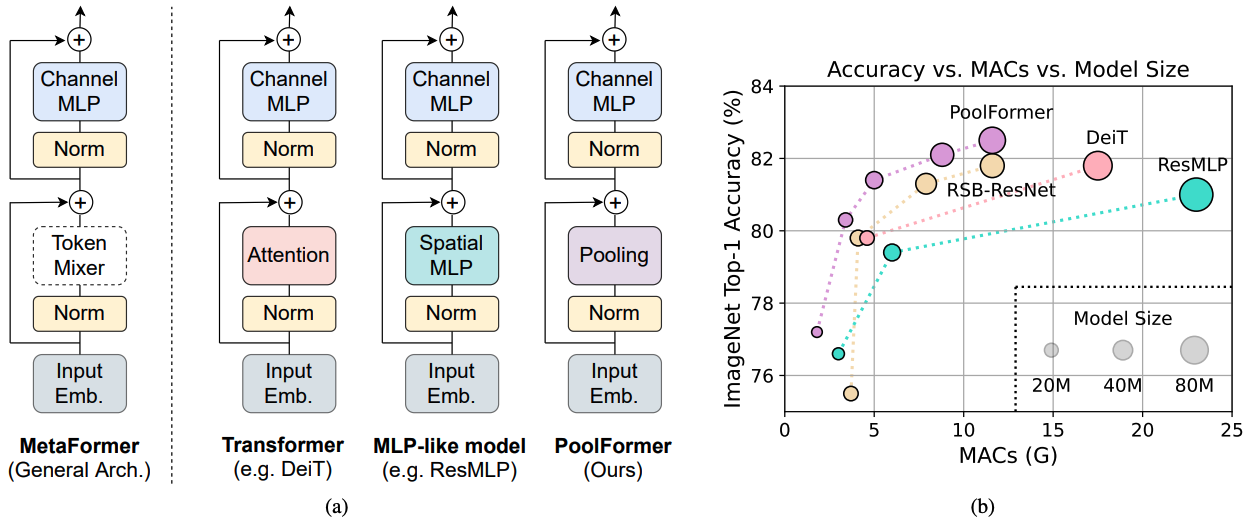 الشكل 1: metaformer وأداء النماذج المستندة إلى metaformer على مجموعة التحقق من صحة ImageNet-1K. نؤكد أن كفاءة النماذج التي تشبه المحول/MLP تنبع في المقام الأول من Metaformer General Architecture بدلاً من خلاطات الرمز المميز المحدد المجهز. لإثبات ذلك ، نستغل مشغلًا بسيطًا غير محرج ، بتجميع ، لإجراء خلط رمزي أساسي للغاية. من المثير للدهشة ، أن مجموعة تجمع النموذج الناتجة يتفوق باستمرار على Deit و Resmlp كما هو موضح في (ب) ، والتي تدعم جيدًا أن MetaFormer هو في الواقع ما نحتاج إلى تحقيق أداء تنافسي. RSB-RESNET في (ب) تعني أن النتائج هي من "Resnet Strikes Back" حيث يتم تدريب Resnet مع إجراء التدريب المحسّن لـ 300 عصر.
الشكل 1: metaformer وأداء النماذج المستندة إلى metaformer على مجموعة التحقق من صحة ImageNet-1K. نؤكد أن كفاءة النماذج التي تشبه المحول/MLP تنبع في المقام الأول من Metaformer General Architecture بدلاً من خلاطات الرمز المميز المحدد المجهز. لإثبات ذلك ، نستغل مشغلًا بسيطًا غير محرج ، بتجميع ، لإجراء خلط رمزي أساسي للغاية. من المثير للدهشة ، أن مجموعة تجمع النموذج الناتجة يتفوق باستمرار على Deit و Resmlp كما هو موضح في (ب) ، والتي تدعم جيدًا أن MetaFormer هو في الواقع ما نحتاج إلى تحقيق أداء تنافسي. RSB-RESNET في (ب) تعني أن النتائج هي من "Resnet Strikes Back" حيث يتم تدريب Resnet مع إجراء التدريب المحسّن لـ 300 عصر.
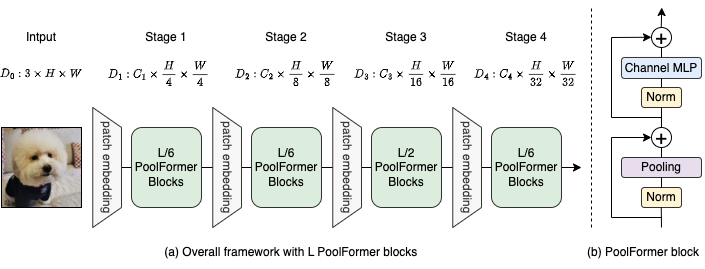
الشكل 2: (أ) الإطار العام للتجمع. (ب) بنية كتلة البلياردو. بالمقارنة مع كتلة المحولات ، فإنه يحل محل الانتباه بمشغل بسيط للغاية غير براريامي ، لتجميع ، لإجراء خلط رمزي أساسي فقط.
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
الكشف وتجزئة المثيل على تكوينات COCO والموديلات المدربة موجودة هنا.
التجزئة الدلالية على تكوينات ADE20K والنماذج المدربة موجودة هنا.
رمز لتصور خرائط تنشيط Grad-Cam لـ Poolfomer و Deit و Resmlp و Resnet و Swin هنا.
رمز لقياس MACs هنا.
الشعلة> = 1.7.0 ؛ torchvision> = 0.8.0 ؛ pyyaml Apex-AMP (إذا كنت تريد استخدام FP16) ؛ Timm ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
إعداد البيانات: ImageNet مع بنية المجلد التالية ، يمكنك استخراج ImageNet بهذا البرنامج النصي.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| نموذج | #Params | قرار الصورة | #Macs* | TOP1 ACC | تحميل |
|---|---|---|---|---|---|
| poolformer_s12 | 12m | 224 | 1.8 جم | 77.2 | هنا |
| poolformer_s24 | 21m | 224 | 3.4g | 80.3 | هنا |
| poolformer_s36 | 31M | 224 | 5.0g | 81.4 | هنا |
| poolformer_m36 | 56 م | 224 | 8.8g | 82.1 | هنا |
| poolformer_m48 | 73 م | 224 | 11.6 جم | 82.5 | هنا |
يمكن أيضًا تنزيل جميع النماذج المسبقة بواسطة Baidu Yun (كلمة المرور: ESAC). * للمقارنة المريحة مع النماذج المستقبلية ، نقوم بتحديث أرقام Macs التي تحسبها مكتبة FVCore (رمز المثال) والتي يتم الإبلاغ عنها أيضًا في إصدار Arxiv الجديد.
مدمجة في مساحات Huggingface؟ باستخدام Gradio. جرب عرض الويب:
نقدم أيضًا دفتر كولاب الذي يدير خطوات لإجراء الاستدلال مع Poolformer:
لتقييم نماذج التجمع الخاصة بنا ، قم بتشغيل:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint نظهر كيفية تدريب المسبح على 8 وحدات معالجة الرسومات. العلاقة بين معدل التعلم وحجم الدُفعة هي LR = BS/1024*1E-3. للراحة ، على افتراض أن حجم الدُفعة هو 1024 ، يتم تعيين معدل التعلم على أنه 1E-3 (لحجم الدُفعة 1024 ، مما يضع معدل التعلم على أنه 2E-3 يرى أحيانًا أداء أفضل).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp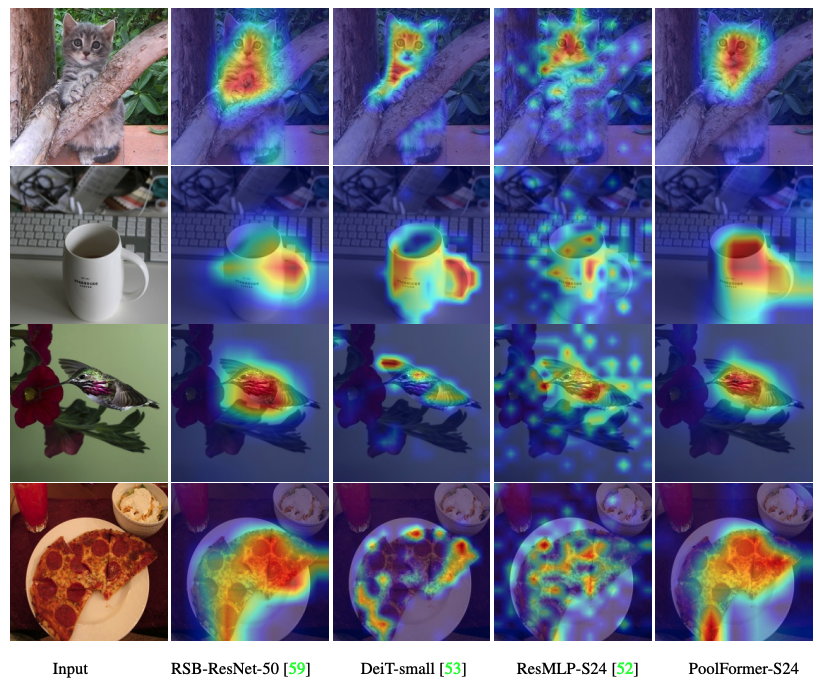
الكود لتصور خرائط تنشيط Grad-Cam لـ Poolfomer و Deit و Resmlp و Resnet و Swin هنا.
يعتمد تنفيذنا بشكل أساسي على قواعد الكود التالية. نشكر المؤلفين بامتنان على أعمالهم الرائعة.
Pytorch-dimage-models ، mmdetection ، mmsegressation.
علاوة على ذلك ، تود Weihao Yu أن تشكر برنامج TPU Research Cloud (TRC) لدعم الموارد الحسابية الجزئية.


