poolformer
1.0.0
Наша последующая работа «Базовые показатели метаформеров для зрения» (код: метаформер) вводит больше базовых показателей метаформеров, включая
Это реализация Pytorch Poolformer , предложенную нашей статьей «Метаноформер, на самом деле то, что вам нужно для зрения» (CVPR 2022 Oral).
ПРИМЕЧАНИЕ . Вместо того, чтобы проектировать сложные токеновые микшер для достижения производительности SOTA, цель этой работы состоит в том, чтобы продемонстрировать компетентность моделей трансформаторов, в значительной степени связанной с общей архитектурой метаформер. Обмен/Poolformer - это лишь инструменты для поддержки нашей претензии.
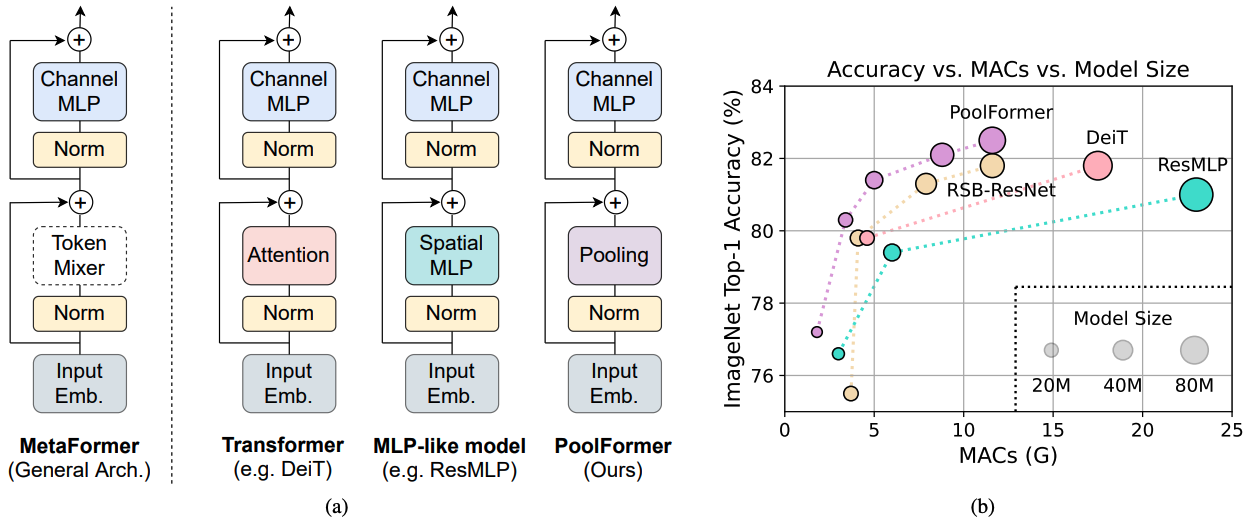 Рисунок 1: Метаформер и производительность моделей на основе метаформеров на наборе валидации ImageNet-1K. Мы утверждаем, что компетентность моделей Transformer/MLP, в первую очередь, связана с общей архитектурой метаформером вместо оборудованных специфических токеновых смесителей. Чтобы продемонстрировать это, мы используем смущающе простого непараметрического оператора, объединяя, чтобы провести чрезвычайно базовое смешивание токенов. Удивительно, но полученный модельный Poolformer постоянно превосходит DEIT и RESMLP, как показано в (b), что хорошо поддерживает, что MetaFormer на самом деле является тем, что нам нужно для достижения конкурентной работы. RSB-resnet в (b) означает, что результаты взяты из «ударов Resnet Back», где Resnet обучен улучшенной процедурой обучения для 300 эпох.
Рисунок 1: Метаформер и производительность моделей на основе метаформеров на наборе валидации ImageNet-1K. Мы утверждаем, что компетентность моделей Transformer/MLP, в первую очередь, связана с общей архитектурой метаформером вместо оборудованных специфических токеновых смесителей. Чтобы продемонстрировать это, мы используем смущающе простого непараметрического оператора, объединяя, чтобы провести чрезвычайно базовое смешивание токенов. Удивительно, но полученный модельный Poolformer постоянно превосходит DEIT и RESMLP, как показано в (b), что хорошо поддерживает, что MetaFormer на самом деле является тем, что нам нужно для достижения конкурентной работы. RSB-resnet в (b) означает, что результаты взяты из «ударов Resnet Back», где Resnet обучен улучшенной процедурой обучения для 300 эпох.
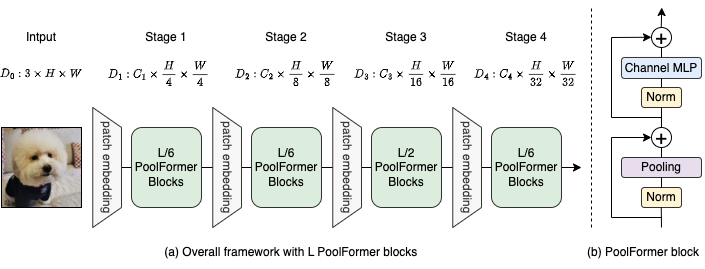
Рисунок 2: (а) Общая структура Poolformer. (б) Архитектура блока Poolformer. По сравнению с блоком трансформатора, он заменяет внимание чрезвычайно простым непараметрическим оператором, объединением, для проведения только базового смешивания токенов.
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
Обнаружение и сегментация экземпляров на конфигурации Coco и обученные модели здесь.
Семантическая сегментация на конфигурации ADE20K и обученные модели здесь.
Код для визуализации карт активации Grad-Cam Poolfomer, DEIT, RESMLP, Resnet и SWIN здесь.
Код для измерения Mac здесь.
TORCH> = 1,7,0; TOCHVISION> = 0,8,0; Pyyaml; Apex-AMP (если вы хотите использовать FP16); TIMM ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
Данные Подготовка: ImageNet Со следующей структурой папок, вы можете извлечь ImageNet с помощью этого сценария.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| Модель | #Парамы | Разрешение изображения | #Macs* | Top1 Acc | Скачать |
|---|---|---|---|---|---|
| Poolformer_S12 | 12 м | 224 | 1,8 г | 77.2 | здесь |
| poolformer_s24 | 21 м | 224 | 3,4 г | 80.3 | здесь |
| Poolformer_S36 | 31 м | 224 | 5,0 г | 81.4 | здесь |
| Poolformer_m36 | 56 м | 224 | 8,8 г | 82.1 | здесь |
| Poolformer_m48 | 73 м | 224 | 11,6 г | 82,5 | здесь |
Все предварительные модели также могут быть загружены Baidu Yun (пароль: ESAC). * Для удобного сравнения с будущими моделями мы обновляем номера Mac, подсчитанных библиотекой FVCore (пример кода), которые также сообщаются в новой версии ARXIV.
Интегрируется в пространства для объятий? Использование Gradio. Попробуйте демонстрацию веб -сайта:
Мы также предоставляем ноутбук Colab, которая выполняет шаги для выполнения вывода с Poolformer:
Чтобы оценить наши модели Poolformer, запустите:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint Мы показываем, как обучать Poolformers на 8 графических процессоров. Соотношение между скоростью обучения и размером партии-LR = BS/1024*1E-3. Для удобства, если предположить, что размер партии составляет 1024, то скорость обучения установлен как 1E-3 (для размера партии 1024, устанавливая скорость обучения, так как 2E-3 иногда видит лучшую производительность).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp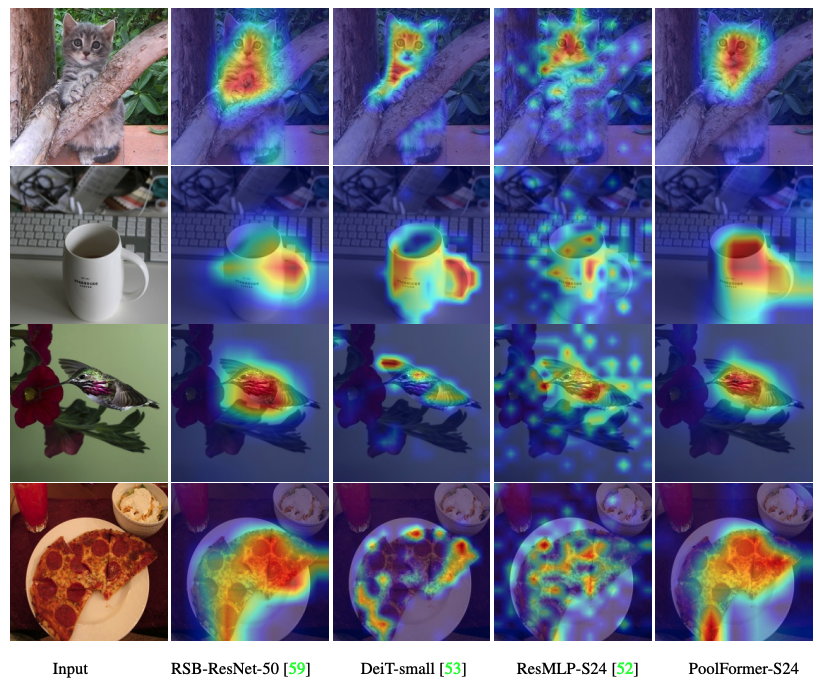
Код для визуализации карт активации Grad-Cam Poolfomer, DEIT, RESMLP, Resnet и SWIN здесь.
Наша реализация в основном основана на следующих кодовых базах. Мы благодарим авторов за их замечательные работы.
Pytorch-Image-Models, MMDetection, MMSegmation.
Кроме того, Weihao Yu хотел бы поблагодарить программу TPU Research Cloud (TRC) за поддержку частичных вычислительных ресурсов.


