poolformer
1.0.0
Nuestro trabajo de seguimiento "MetaFormer Base Baslines for Vision" (Código: Metaformer) presenta más líneas de base de Metaformer, incluida
Esta es una implementación de Pytorch de Foolformer propuesta por nuestro artículo "Metaformer es en realidad lo que necesita para la visión" (CVPR 2022 Oral).
Nota : En lugar de diseñar un mezclador de token complicado para lograr el rendimiento de SOTA, el objetivo de este trabajo es demostrar la competencia de los modelos de transformadores proviene en gran medida del metraformador de arquitectura general. La agrupación/formador de piscinas son solo las herramientas para respaldar nuestro reclamo.
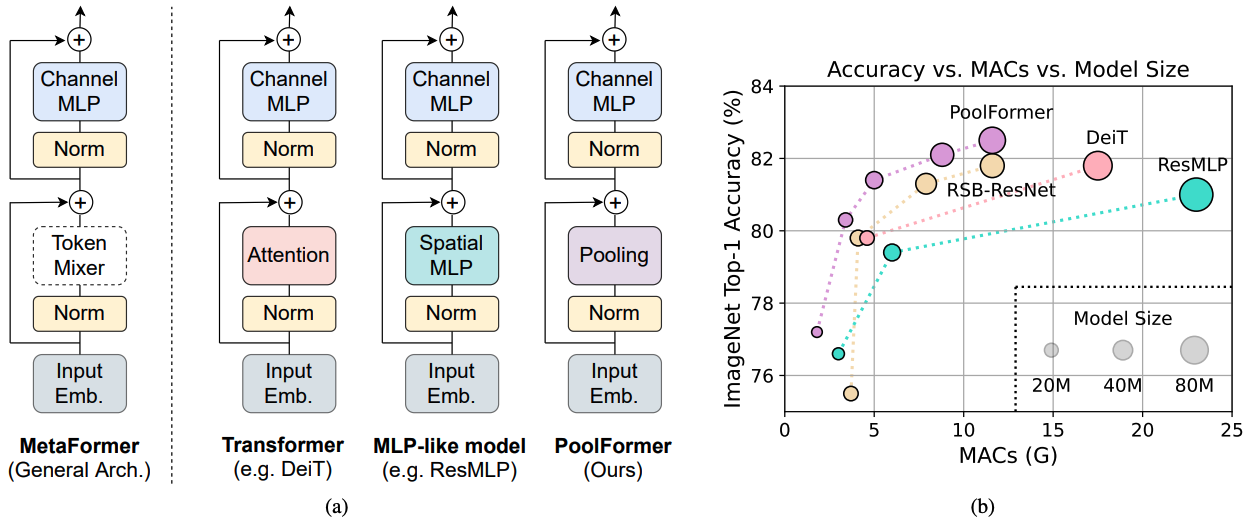 Figura 1: Metaformer y rendimiento de los modelos basados en metaformador en el conjunto de validación de ImageNet-1K. Argumentamos que la competencia de los modelos tipo Transformer/MLP proviene principalmente del metaformador de arquitectura general en lugar de los mezcladores de token específicos equipados. Para demostrar esto, explotamos a un operador no paramétrico vergonzosamente simple, agrupación, para realizar una mezcla de token extremadamente básica. Sorprendentemente, el modelo de grupo resultado supera constantemente el DEIT y el resmlp como se muestra en (b), lo que admite bien que MetaFormer es en realidad lo que necesitamos para lograr un rendimiento competitivo. RSB-Resnet en (b) significa que los resultados son de "resnet hueles hacia atrás", donde resnet está entrenado con un procedimiento de entrenamiento mejorado para 300 épocas.
Figura 1: Metaformer y rendimiento de los modelos basados en metaformador en el conjunto de validación de ImageNet-1K. Argumentamos que la competencia de los modelos tipo Transformer/MLP proviene principalmente del metaformador de arquitectura general en lugar de los mezcladores de token específicos equipados. Para demostrar esto, explotamos a un operador no paramétrico vergonzosamente simple, agrupación, para realizar una mezcla de token extremadamente básica. Sorprendentemente, el modelo de grupo resultado supera constantemente el DEIT y el resmlp como se muestra en (b), lo que admite bien que MetaFormer es en realidad lo que necesitamos para lograr un rendimiento competitivo. RSB-Resnet en (b) significa que los resultados son de "resnet hueles hacia atrás", donde resnet está entrenado con un procedimiento de entrenamiento mejorado para 300 épocas.
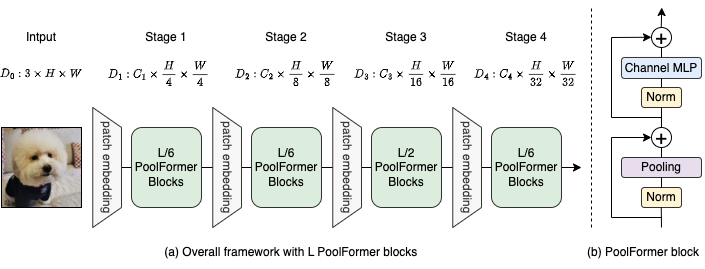
Figura 2: (a) El marco general de Poolformer. (b) La arquitectura del bloque de Foolformer. En comparación con el bloque de transformador, reemplaza la atención con un operador no paramétrico extremadamente simple, agrupación, para realizar solo una mezcla de token básico.
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
La detección y la segmentación de instancias en las configuraciones de Coco y los modelos entrenados están aquí.
La segmentación semántica en las configuraciones ADE20K y los modelos capacitados están aquí.
El código para visualizar los mapas de activación de graduación de graduación de Poolfomer, DEIT, Resmlp, ResNet y Swin están aquí.
El código para medir las Mac está aquí.
antorcha> = 1.7.0; TorchVision> = 0.8.0; pyyaml; APEX-AMP (si desea usar FP16); TIMM ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
Preparación de datos: Imagenet Con la siguiente estructura de carpetas, puede extraer Imagenet por este script.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| Modelo | #Params | Resolución de imágenes | #Macs* | Top1 ACC | Descargar |
|---|---|---|---|---|---|
| PoolFormer_S12 | 12m | 224 | 1.8g | 77.2 | aquí |
| Poolformer_S24 | 21m | 224 | 3.4g | 80.3 | aquí |
| PoolFormer_S36 | 31m | 224 | 5.0g | 81.4 | aquí |
| PoolFormer_M36 | 56m | 224 | 8.8g | 82.1 | aquí |
| PoolFormer_M48 | 73m | 224 | 11.6g | 82.5 | aquí |
Baidu Yun (contraseña: ESAC). * Para una comparación conveniente con modelos futuros, actualizamos los números de Mac contados por la biblioteca FVCore (código de ejemplo) que también se informan en la nueva versión ARXIV.
Integrado en los espacios de la cara de abrazo? Usando Gradio. Prueba la demostración web:
También proporcionamos un cuaderno Colab que ejecuta los pasos para realizar una inferencia con Poolformer:
Para evaluar nuestros modelos de Foolformer, ejecute:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint Mostramos cómo entrenar a los formadores de piscinas en 8 GPU. La relación entre la tasa de aprendizaje y el tamaño del lote es LR = BS/1024*1E-3. Por conveniencia, suponiendo que el tamaño del lote sea 1024, entonces la tasa de aprendizaje se establece como 1E-3 (para el tamaño del lote de 1024, estableciendo la tasa de aprendizaje como 2E-3 a veces ve un mejor rendimiento).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp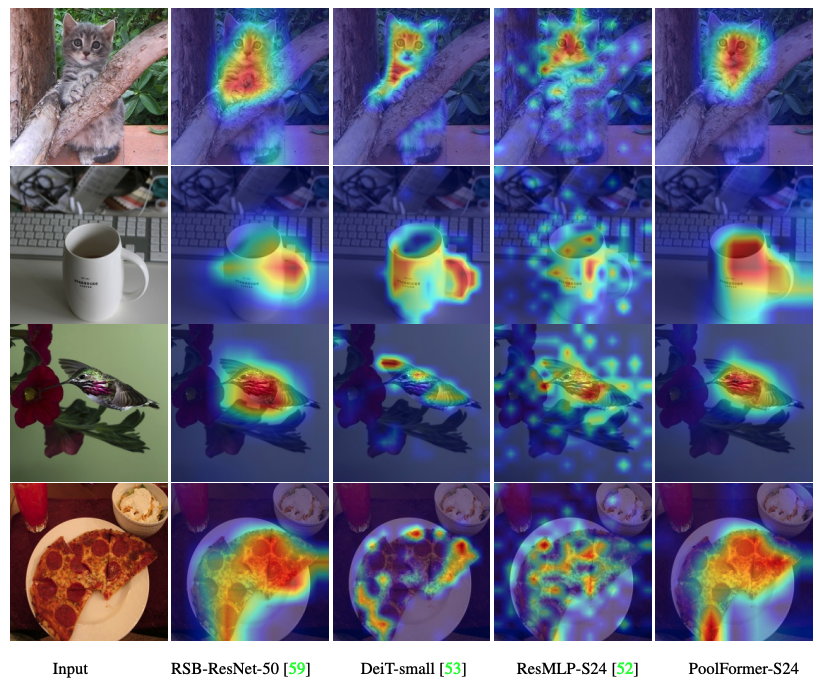
El código para visualizar los mapas de activación de graduación de graduación de Poolfomer, DEIT, Resmlp, ResNet y Swin están aquí.
Nuestra implementación se basa principalmente en las siguientes bases de código. Agradecemos a los autores agradecidos por sus maravillosas obras.
Pytorch-Image-Models, MMDetection, MMSegmentation.
Además, Weihao Yu desea agradecer al programa TPU Research Cloud (TRC) por el apoyo de recursos computacionales parciales.


