poolformer
1.0.0
Unsere Follow-up-Arbeit "Metaformer Baselines for Vision" (Code: Metaformer) führt mehr Metaformer Baselines einschließlich der
Dies ist eine Pytorch -Implementierung von Poolformer, die von unserem Artikel "Metaformer ist tatsächlich das, was Sie für Sehvermögen benötigen" (CVPR 2022 Oral) vorgeschlagen.
HINWEIS : Anstatt komplizierten Tokenmixer zu entwerfen, um die SOTA -Leistung zu erzielen, ist das Ziel dieser Arbeit die Kompetenz von Transformatormodellen weitgehend aus dem allgemeinen Architektur -Metaformer. Pooling/Poolformer sind nur die Werkzeuge, um unseren Anspruch zu unterstützen.
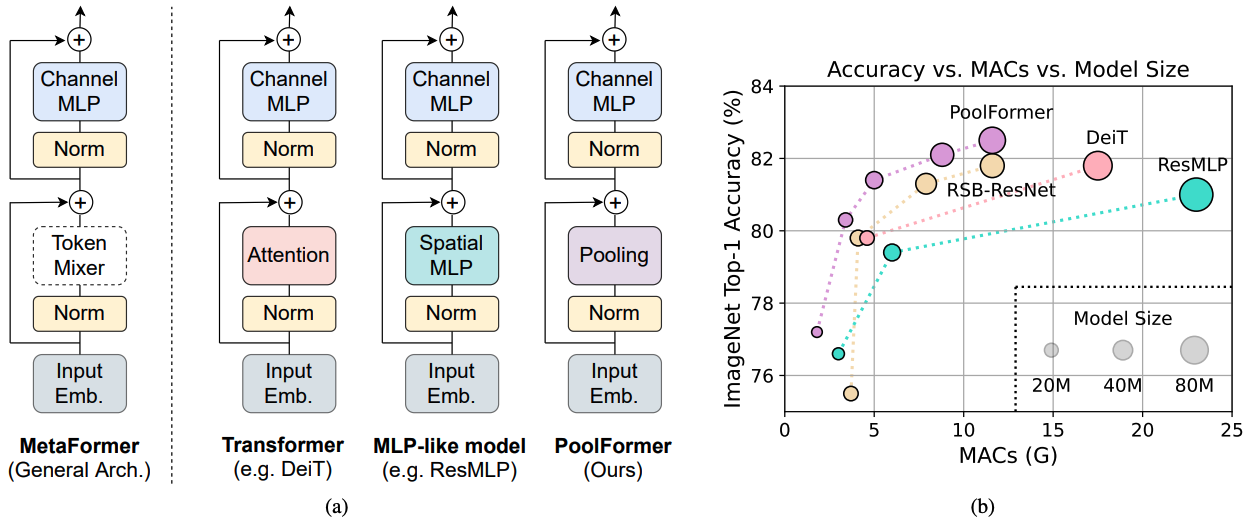 Abbildung 1: Metaformer und Leistung von Metaformer-basierten Modellen im Validierungssatz im Bildnetier-1K. Wir argumentieren, dass die Kompetenz von Transformator/MLP-ähnlichen Modellen hauptsächlich aus dem allgemeinen Architektur-Metaformer anstelle der ausgestatteten spezifischen Token-Mixer zurückzuführen ist. Um dies zu demonstrieren, nutzen wir einen peinlich einfachen, nicht parametrischen Bediener, der bündelt, um ein extrem einfaches Token-Mischen durchzuführen. Überraschenderweise übertrifft das entstandene Modellpoolformer die Deit und RESMLP durchweg, wie in (b) gezeigt, was gut unterstützt, dass Metaformer tatsächlich das ist, was wir benötigen, um eine Wettbewerbsleistung zu erzielen. RSB-RESNET in (b) bedeutet, dass die Ergebnisse von „Resnet Strikes Back“ stammen, bei denen ResNet für 300 Epochen mit verbessertem Trainingsverfahren geschult wird.
Abbildung 1: Metaformer und Leistung von Metaformer-basierten Modellen im Validierungssatz im Bildnetier-1K. Wir argumentieren, dass die Kompetenz von Transformator/MLP-ähnlichen Modellen hauptsächlich aus dem allgemeinen Architektur-Metaformer anstelle der ausgestatteten spezifischen Token-Mixer zurückzuführen ist. Um dies zu demonstrieren, nutzen wir einen peinlich einfachen, nicht parametrischen Bediener, der bündelt, um ein extrem einfaches Token-Mischen durchzuführen. Überraschenderweise übertrifft das entstandene Modellpoolformer die Deit und RESMLP durchweg, wie in (b) gezeigt, was gut unterstützt, dass Metaformer tatsächlich das ist, was wir benötigen, um eine Wettbewerbsleistung zu erzielen. RSB-RESNET in (b) bedeutet, dass die Ergebnisse von „Resnet Strikes Back“ stammen, bei denen ResNet für 300 Epochen mit verbessertem Trainingsverfahren geschult wird.
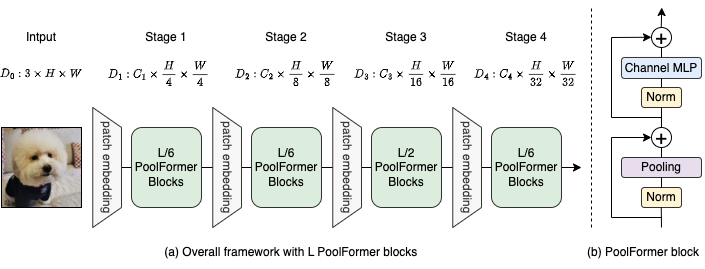
Abbildung 2: (a) Der Gesamtrahmen des Poolformers. (b) Die Architektur des Poolformer -Blocks. Im Vergleich zum Transformator-Block ersetzt es die Aufmerksamkeit durch einen extrem einfachen nicht parametrischen Bediener, der nur eine einfache Tokenmischung durchführt.
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
Erkennungs- und Instanzsegmentierung zu Coco -Konfigurationen und trainierten Modellen finden Sie hier.
Semantische Segmentierung auf ADE20K -Konfigurationen und trainierten Modellen finden Sie hier.
Der Code zur Visualisierung von Grad-CAM-Aktivierungskarten von Poolfomer, Deit, RESMLP, ResNet und Swin finden Sie hier.
Der Code zur Messung von Macs ist hier.
Fackel> = 1,7,0; Torchvision> = 0,8,0; Pyyaml; Apex-Amp (wenn Sie FP16 verwenden möchten); TIMM ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
Daten vorbereiten: ImagEnet Mit der folgenden Ordnerstruktur können Sie ImageNet durch dieses Skript extrahieren.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| Modell | #Params | Bildauflösung | #Macs* | Top1 ACC | Herunterladen |
|---|---|---|---|---|---|
| Poolformer_S12 | 12 m | 224 | 1,8g | 77,2 | Hier |
| Poolformer_S24 | 21m | 224 | 3.4g | 80.3 | Hier |
| Poolformer_S36 | 31m | 224 | 5.0g | 81.4 | Hier |
| Poolformer_m36 | 56 m | 224 | 8,8g | 82.1 | Hier |
| Poolformer_m48 | 73 m | 224 | 11.6g | 82,5 | Hier |
Alle vorbereiteten Modelle können auch von Baidu Yun (Passwort: ESAC) heruntergeladen werden. * Für einen bequemen Vergleich mit zukünftigen Modellen aktualisieren wir die Anzahl der von der FVCORE -Bibliothek (Beispielcode) gezählten Macs, die auch in der neuen Arxiv -Version gemeldet werden.
In Umarmungsflächen integriert? mit Gradio. Probieren Sie die Web -Demo aus:
Wir stellen auch ein Colab -Notizbuch zur Verfügung, in dem die Schritte ausführen, um die Inferenz mit Poolformer durchzuführen:
Um unsere Poolformer -Modelle zu bewerten, rennen Sie:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint Wir zeigen, wie man Poolformer auf 8 GPUs trainiert. Die Beziehung zwischen Lernrate und Chargengröße beträgt LR = BS/1024*1E-3. Unter der Annahme, dass die Stapelgröße 1024 beträgt, wird die Lernrate als 1E-3 festgelegt (für die Stapelgröße von 1024, wodurch die Lernrate als 2E-3 manchmal eine bessere Leistung erfolgt).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp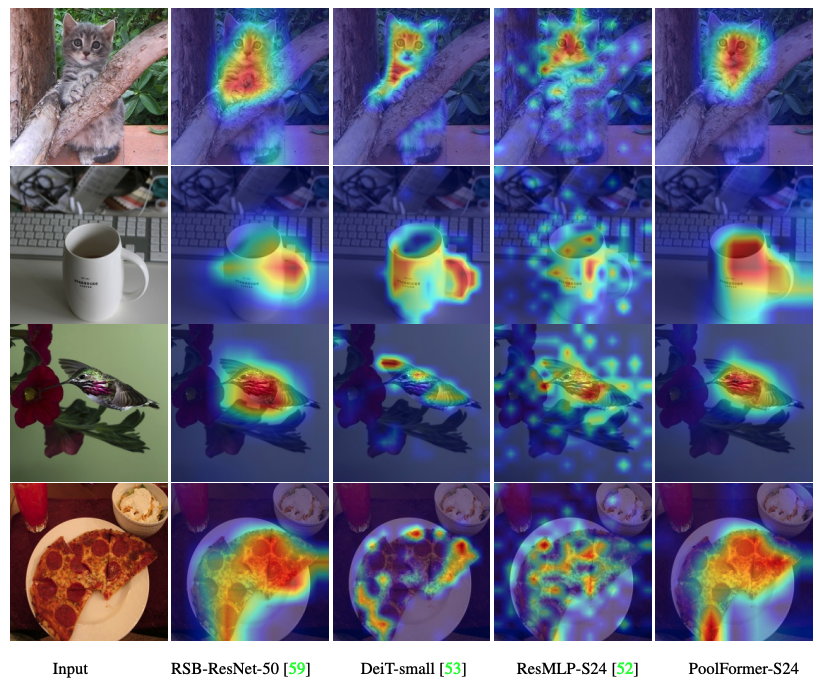
Der Code zur Visualisierung von Grad-CAM-Aktivierungskarten von Poolfomer, Deit, RESMLP, ResNet und Swin finden Sie hier.
Unsere Implementierung basiert hauptsächlich auf den folgenden Codebasen. Wir danken den Autoren dankbar für ihre wundervollen Werke.
Pytorch-Image-Modelle, mmdetektion, mmSegmentierung.
Außerdem möchte sich Weihao Yu für die Unterstützung teilweise Rechenressourcen bedanken.


