poolformer
1.0.0
งานติดตามผลของเรา
นี่คือการใช้งาน Pytorch ของ Poolformer ที่เสนอโดยเอกสารของเรา "Metaformer เป็นสิ่งที่คุณต้องการสำหรับการมองเห็น" (CVPR 2022 ORAL)
หมายเหตุ : แทนที่จะออกแบบเครื่องผสมโทเค็นที่ซับซ้อนเพื่อให้ได้ประสิทธิภาพของ SOTA เป้าหมายของงานนี้คือการแสดงให้เห็นถึงความสามารถของโมเดลหม้อแปลงส่วนใหญ่เกิดจากสถาปัตยกรรมทั่วไป Metaformer การรวม/poolformer เป็นเพียงเครื่องมือในการสนับสนุนการเรียกร้องของเรา
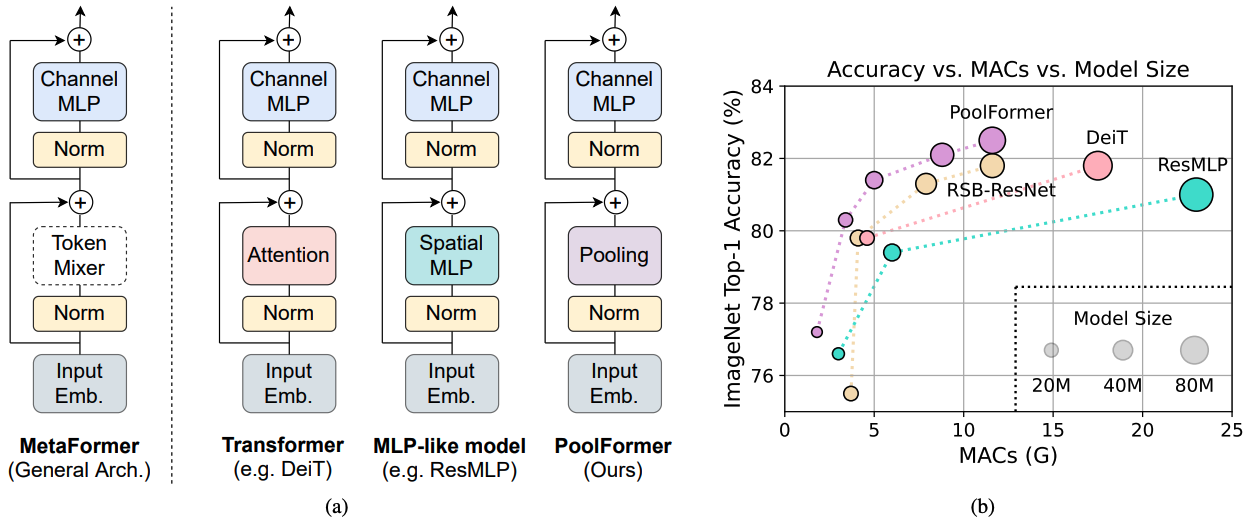 รูปที่ 1: Metaformer และประสิทธิภาพของโมเดล Metaformer บนชุดการตรวจสอบ Imagenet-1K เรายืนยันว่าความสามารถของโมเดลที่มีลักษณะคล้ายหม้อแปลง/MLP ส่วนใหญ่เกิดจากสถาปัตยกรรมทั่วไป Metaformer แทนที่จะเป็นเครื่องผสมโทเค็นเฉพาะที่ติดตั้ง เพื่อแสดงให้เห็นถึงสิ่งนี้เราใช้ประโยชน์จากผู้ประกอบการที่ไม่ใช่พารามิเตอร์ที่น่าอายอย่างง่าย ๆ รวมเข้าด้วยกันเพื่อดำเนินการผสมโทเค็นขั้นพื้นฐานอย่างมาก น่าแปลกที่โมเดล poolformer ที่เกิดขึ้นนั้นมีประสิทธิภาพสูงกว่า DEIT และ RESMLP อย่างต่อเนื่องดังที่แสดงใน (B) ซึ่งรองรับ Metaformer เป็นสิ่งที่เราต้องการเพื่อให้ได้ประสิทธิภาพการแข่งขัน RSB-RESNET ใน (b) หมายถึงผลลัพธ์มาจาก“ Resnet Strikes Back” ซึ่ง RESNET ได้รับการฝึกฝนด้วยขั้นตอนการฝึกอบรมที่ดีขึ้นสำหรับ 300 Epochs
รูปที่ 1: Metaformer และประสิทธิภาพของโมเดล Metaformer บนชุดการตรวจสอบ Imagenet-1K เรายืนยันว่าความสามารถของโมเดลที่มีลักษณะคล้ายหม้อแปลง/MLP ส่วนใหญ่เกิดจากสถาปัตยกรรมทั่วไป Metaformer แทนที่จะเป็นเครื่องผสมโทเค็นเฉพาะที่ติดตั้ง เพื่อแสดงให้เห็นถึงสิ่งนี้เราใช้ประโยชน์จากผู้ประกอบการที่ไม่ใช่พารามิเตอร์ที่น่าอายอย่างง่าย ๆ รวมเข้าด้วยกันเพื่อดำเนินการผสมโทเค็นขั้นพื้นฐานอย่างมาก น่าแปลกที่โมเดล poolformer ที่เกิดขึ้นนั้นมีประสิทธิภาพสูงกว่า DEIT และ RESMLP อย่างต่อเนื่องดังที่แสดงใน (B) ซึ่งรองรับ Metaformer เป็นสิ่งที่เราต้องการเพื่อให้ได้ประสิทธิภาพการแข่งขัน RSB-RESNET ใน (b) หมายถึงผลลัพธ์มาจาก“ Resnet Strikes Back” ซึ่ง RESNET ได้รับการฝึกฝนด้วยขั้นตอนการฝึกอบรมที่ดีขึ้นสำหรับ 300 Epochs
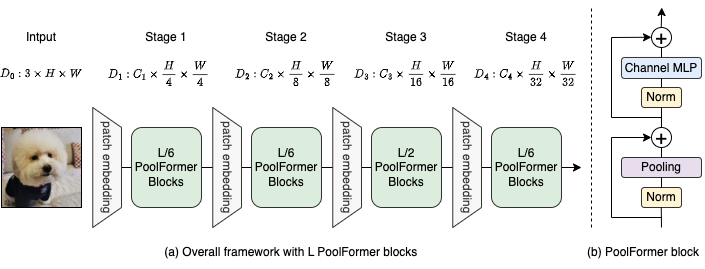
รูปที่ 2: (a) กรอบโดยรวมของ poolformer (b) สถาปัตยกรรมของ boolformer block เมื่อเทียบกับบล็อกหม้อแปลงมันแทนที่ความสนใจด้วยผู้ให้บริการที่ไม่ใช่พารามิเตอร์ที่ง่ายมากการรวมเข้าด้วยกันเพื่อดำเนินการผสมโทเค็นขั้นพื้นฐานเท่านั้น
@inproceedings{yu2022metaformer,
title={Metaformer is actually what you need for vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10819--10829},
year={2022}
}
การตรวจจับและการแบ่งส่วนอินสแตนซ์บน coco configs และรุ่นที่ผ่านการฝึกอบรมอยู่ที่นี่
การแบ่งส่วนความหมายในการกำหนดค่า ADE20K และรุ่นที่ผ่านการฝึกอบรมอยู่ที่นี่
รหัสเพื่อให้เห็นภาพแผนที่การเปิดใช้งาน Grad-CAM ของ PoolFomer, DEIT, ResMLP, Resnet และ Swin อยู่ที่นี่
รหัสในการวัด MACs อยู่ที่นี่
TORCH> = 1.7.0; Torchvision> = 0.8.0; Pyyaml; Apex-amp (ถ้าคุณต้องการใช้ FP16); TIMM ( pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a )
การเตรียมข้อมูล: ImageNet ด้วยโครงสร้างโฟลเดอร์ต่อไปนี้คุณสามารถแยก ImageNet ด้วยสคริปต์นี้
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| แบบอย่าง | #params | ความละเอียดของภาพ | #macs* | Top1 ACC | การดาวน์โหลด |
|---|---|---|---|---|---|
| poolformer_s12 | 12m | 224 | 1.8 กรัม | 77.2 | ที่นี่ |
| poolformer_s24 | 21m | 224 | 3.4 กรัม | 80.3 | ที่นี่ |
| poolformer_s36 | 31m | 224 | 5.0g | 81.4 | ที่นี่ |
| poolformer_m36 | 56m | 224 | 8.8 กรัม | 82.1 | ที่นี่ |
| poolformer_m48 | 73m | 224 | 11.6g | 82.5 | ที่นี่ |
Baidu Yun (รหัสผ่าน: ESAC) * เพื่อการเปรียบเทียบที่สะดวกกับโมเดลในอนาคตเราจะอัปเดตจำนวน MAC ที่นับโดยไลบรารี FVCore (รหัสตัวอย่าง) ซึ่งมีการรายงานในเวอร์ชัน ARXIV ใหม่
รวมเข้ากับช่องว่าง HuggingFace? ใช้ Gradio ลองใช้การสาธิตเว็บ:
นอกจากนี้เรายังมีโน้ตบุ๊ก colab ซึ่งดำเนินการตามขั้นตอนในการดำเนินการอนุมานกับ Poolformer:
เพื่อประเมินโมเดล poolformer ของเรา Run:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL -b 128
--pretrained # or --checkpoint /path/to/checkpoint เราแสดงวิธีการฝึกอบรมนักพูลใน 8 GPU ความสัมพันธ์ระหว่างอัตราการเรียนรู้และขนาดแบทช์คือ LR = BS/1024*1E-3 เพื่อความสะดวกสมมติว่าขนาดแบทช์คือ 1024 จากนั้นอัตราการเรียนรู้จะถูกตั้งค่าเป็น 1E-3 (สำหรับขนาดแบทช์ 1024 การตั้งค่าอัตราการเรียนรู้เป็น 2E-3 บางครั้งเห็นประสิทธิภาพที่ดีขึ้น)
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp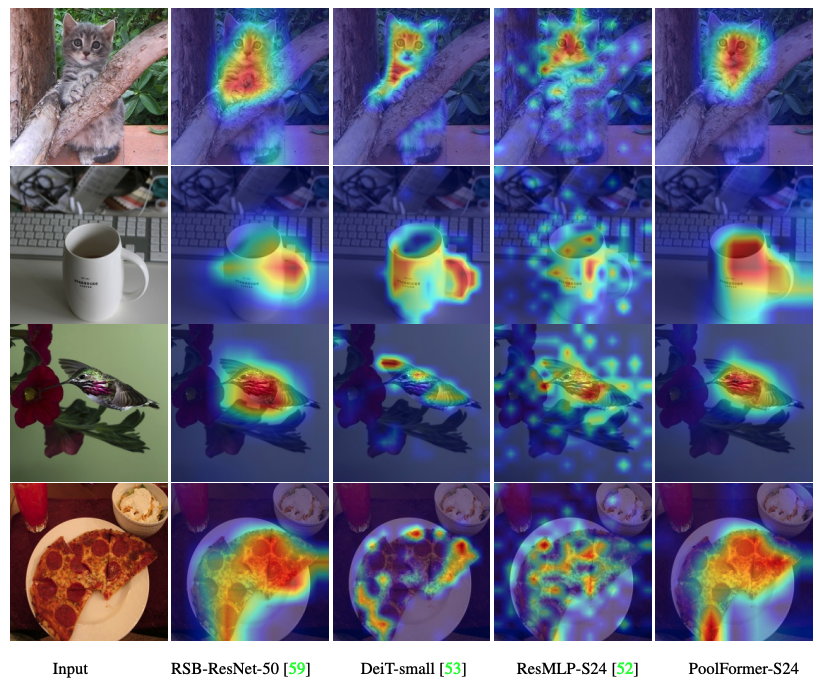
รหัสเพื่อให้เห็นภาพแผนที่การเปิดใช้งาน Grad-CAM ของ PoolFomer, DEIT, ResMLP, Resnet และ Swin อยู่ที่นี่
การใช้งานของเราส่วนใหญ่ขึ้นอยู่กับรหัสฐานต่อไปนี้ เราขอขอบคุณผู้เขียนสำหรับผลงานที่ยอดเยี่ยมของพวกเขา
pytorch-image-models, mmdetection, mmsegentation
นอกจากนี้ Weihao Yu ขอขอบคุณโปรแกรม TPU Research Cloud (TRC) สำหรับการสนับสนุนทรัพยากรการคำนวณบางส่วน


