DDSP SVC
ved DDSP Cascade Diffusion Model
语言:英语(过时)
(1)预处理:
python preprocess.py -c configs/reflow.yaml(2)培训:
python train_reflow.py -c configs/reflow.yaml(3)非实时推理:
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > “推理_Step”是整流流ode的采样步骤的数量,“方法”是“ euler”或“ rk4”,'t_start'是ode的起点,它需要大于或等于配置文件中的t_start ,建议保持等效(默认值为0.7)
安装依赖项,数据准备,配置预训练的编码器(Hubert或ContentVec),音调提取器(RMVPE)和Vocoder(NSF-Hifigan)与培训纯DDSP模型相同(请参阅下面的部分)。
我们在发布页面中提供了预训练的模型。
将model_0.pt移动到由diffusion-fast.yaml中“ expdir”参数指定的模型导出文件夹,该程序将自动加载该文件夹中的预训练模型。
(1)预处理:
python preprocess.py -c configs/diffusion-fast.yaml(2)训练级联模型(仅训练一种型号):
python train_diff.py -c configs/diffusion-fast.yaml(3)非实时推理:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 5.0版本模型具有内置DDSP模型,因此不需要使用-ddsp指定外部DDSP模型。其他选项具有与3.0版本模型相同的含义,但是“ KSTEP”需要小于或等于配置文件中的k_step_max ,建议保持等效(默认为100)
(4)实时GUI:
python gui_diff.py注意:您需要在GUI的右侧加载5.0版型号
安装依赖项,数据准备,配置预训练的编码器(Hubert或ContentVec),音调提取器(RMVPE)和Vocoder(NSF-Hifigan)与培训纯DDSP模型相同(请参阅下面的部分)。
我们在此处提供预先训练的模型:https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/main/pre-trained-model/model/model/model_0.pt(使用contentvec768l12 encoder)
将model_0.pt移动到diffusion-new.yaml中“ expdir”参数指定的模型导出文件夹,该程序将自动加载该文件夹中的预训练模型。
(1)预处理:
python preprocess.py -c configs/diffusion-new.yaml(2)训练级联模型(仅训练一种型号):
python train_diff.py -c configs/diffusion-new.yaml注意:FP16培训存在暂时的问题,但是FP32和BF16正常工作,
(3)非实时推理:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 4.0版本模型具有内置DDSP模型,因此不需要使用-ddsp指定外部DDSP模型。其他选项具有与3.0版本模型相同的含义,但是“ KSTEP”需要小于或等于配置文件中的k_step_max ,建议保持等效(默认为100)
(4)实时GUI:
python gui_diff.py注意:您需要在GUI的右侧加载4.0版型号
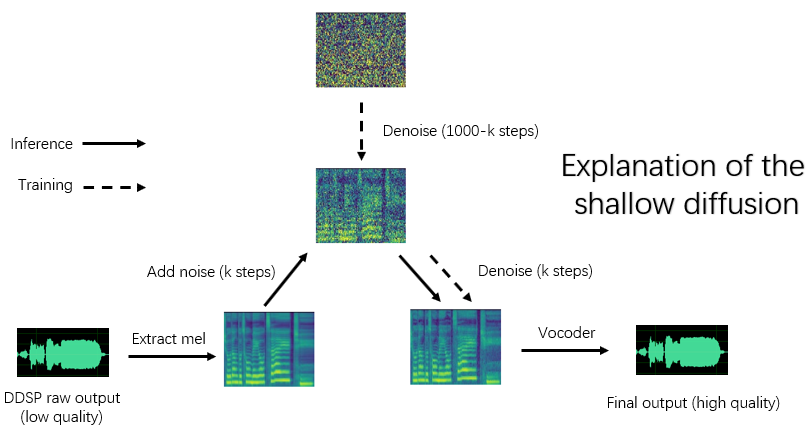
安装依赖项,数据准备,配置预训练的编码器(Hubert或ContentVec),音高提取器(RMVPE)和Vocoder(NSF-Hifigan)与培训纯的DDSP模型相同(请参阅下面的第1〜3章)。
由于扩散模型更难训练,因此我们在此处提供一些预训练的模型:
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-pre--trained-model/blob/main/main/hubertsoft_pitch_pitch_pitch_add_vctk_500k/model_0.pt
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-pre--trained-model/blob/main/main/fix_pitch_pitch_add_vctk_600k/model_0.pt
将model_0.pt移动到diffusion.yaml中“ expdir”参数指定的模型导出文件夹,该程序将自动将预训练的模型加载到该文件夹中。
(1)预处理:
python preprocess.py -c configs/diffusion.yaml此预处理也可以用于训练DDSP模型而无需预处理两次,但是您需要确保YAML文件中“数据”标签下的参数一致。
(2)训练扩散模型:
python train_diff.py -c configs/diffusion.yaml(3)训练DDSP模型:
python train.py -c configs/combsub.yaml如上所述,不需要重新处理,但是请检查combsub.yaml和diffusion.yaml匹配的参数。扬声器“ N_SPK”的数量可能是不一致的,但是尝试使用相同的ID代表同一扬声器(这使推断更容易)。
(4)非实时推理:
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > “加速”是加速度速度,“方法”是“ ddim”,“ pndm”,“ dpm-solver”或“ unipc”,“ kStep”是浅扩散步骤的数量,“ diffid”是扩散模型的扬声器ID,而其他参数则与main.py相同。
合理的“ KSTEP”约为100〜300。当“加速”超过20时,可能会发现声音质量的丧失。
如果在培训期间使用相同的ID代表同一说话者,则“ -diffid”可以为空,否则需要指定“ -diffid”选项。
如果“ -DDSP”为空,则使用纯扩散模型,此时,使用输入源的MEL进行浅扩散,如果进一步的“ -kstep”是空的,则进行全深度高斯扩散。
该程序将自动检查DDSP模型的参数和扩散模型是否匹配(采样率,跳尺寸和编码器),如果它们不匹配,它将忽略加载DDSP模型并输入高斯扩散模式。
(5)实时GUI:
python gui_diff.pyDDSP-SVC是一个新的开源唱歌语音转换项目,致力于开发免费的AI语音更换软件,可以在个人计算机上普及。
与著名的SO-VITS-SVC相比,其培训和合成对计算机硬件的要求要低得多,并且可以通过数量级缩短培训时间,该数量级接近RVC的训练速度。
此外,在更改实时语音时,该项目的硬件资源消耗明显低于SO-VITS-SVC,但可能略高于最新版本的RVC。
尽管DDSP的原始合成质量不是理想的(在训练时可以在张量中听到原始输出),但是在使用预训练的基于Vocoder的增强器(旧版本)或具有浅水扩散模型(新版本)提高声音质量之后,对于某些数据集,它可以达到综合质量,而不是Sovits-SVC和RVC。
旧版本模型仍然兼容,以下章节是旧版本的说明。新版本的某些操作是相同的,请参见前几章。
免责声明:请确保仅使用合法获得的授权数据培训DDSP-SVC模型,并且不要使用这些模型和它们合成的任何音频出于非法目的。该存储库的作者对使用这些模型检查点和音频引起的任何侵权,欺诈和其他非法行为概不负责。
更新日志:我懒得翻译,请参阅中文版本。
我们建议首先从官方网站安装Pytorch,然后运行:
pip install -r requirements.txt注意:我仅使用Python 3.8(Windows) + Torch 1.9.1 + Torchaudio 0.6.0测试代码
更新:Python 3.8(Windows) + CUDA 11.8 + TORCH 2.0.0 + TORCHAUDIO 2.0.1工作,培训速度更快。
(1)下载预先训练的ContentVec编码器,并将其放在pretrain/contentvec文件夹下。
(2)下载预先培训的Hubertsoft编码器,然后将其放在pretrain/hubert文件夹下,然后同时修改配置文件。
下载并解开预先训练的NSF-Hifigan Vocoder
或使用https://github.com/openvpi/singingvocoders项目来微调声码器以提高声音质量。
然后重命名检查点文件,然后将其放置在配置文件中的“ vocoder.ckpt”参数指定的位置。默认值是pretrain/nsf_hifigan/model 。
VOCODER的“ config.json”需要在同一目录中,例如pretrain/nsf_hifigan/config.json 。
下载预先训练的RMVPE提取器,然后将其解压缩到pretrain/文件夹中。
将所有培训数据集(.WAV格式剪辑)放在以下目录中: data/train/audio 。将所有验证数据集(.WAV格式剪辑)放在以下目录中: data/val/audio 。你也可以运行
python draw.py为了帮助您选择验证数据(您可以调整draw.py中的参数以修改提取的文件和其他参数的数量)
然后运行
python preprocess.py -c configs/combsub.yaml用于梳子剥夺合成器的模型(建议)或运行
python preprocess.py -c configs/sins.yaml用于正弦曲线添加合成器的模型。
有关训练扩散模型,请参见上面的第3.0、4.0或5.0节。
您可以在预处理之前修改配置文件config/<model_name>.yaml 。默认配置适用于使用GTX-1660图形卡训练44.1KHz高采样率合成器。
注意1:请保持所有音频夹的采样率与YAML配置文件中的采样率一致!如果不一致,则可以安全执行该程序,但是在培训过程中的重新采样将非常慢。
注2:建议将用于训练数据集的音频剪辑总数约为1000,尤其是可以将长音频剪辑切成短段,这将加快训练的速度,但是所有音频剪辑的持续时间不应少于2秒。如果音频剪辑太多,则需要一个大型内置内存或将“ Cache_all_data”选项设置为“配置文件”中的false。
注3:建议使用验证数据集的音频片段总数约为10,请不要放太多,或者进行验证非常慢。
注意4:如果您的数据集质量不是很高,请将“ F0_Extractor”设置为配置文件中的“ rmvpe”。
注5:现在支持多演讲者培训。配置文件中的“ N_SPK”参数控制它是否是多扬声器模型。如果您想训练多演讲者的模型,则需要使用不大于“ N_SPK”的正整数命名来表示说话者ID,则目录结构如下:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...如果'n_spk'= 1,则仍然支持单个扬声器模型的目录结构,如下所示:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yaml训练其他模型的命令行相似。
您可以安全地中断训练,然后运行相同的命令行将恢复培训。
如果首先中断训练,也可以对模型进行填充,然后重新启动新数据集或更改训练参数(batchsize,lr等),然后运行相同的命令行。
# check the training status using tensorboard
tensorboard --logdir=exp第一次验证后,在张板中可见测试音频样品。
注意:张板中的测试音频样品是DDSP-SVC型号的原始输出,并未通过增强器增强。如果您想在使用增强剂(可能具有更高质量)后测试合成效应,请使用下一章中描述的方法。
(建议)使用基于VOCODER的增强器来增强输出:
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >DDSP的原始输出:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e false有关F0提取器和响应的其他选项,请参见:
python main.py -h(更新)现在支持混音说明器。您可以使用“ -mix”选项来设计自己的人声音色,以下是一个示例:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0使用以下命令开始简单的GUI:
python gui.py前端使用的技术,例如滑动窗口,横向插图,基于Sola的剪接和上下文语义参考,它们可以在低潜伏期和资源职业的非真实时间合成的附近实现声音质量。
更新:现在添加了基于相位Vocoder的剪接算法,但是在大多数情况下,Sola算法已经具有足够高的剪接声音质量,因此默认情况下将其关闭。如果您要追求极端低延迟的实时声音质量,则可以考虑将其打开并仔细调整参数,并且声音质量可能会更高。但是,大量测试发现,如果交叉效率时间长于0.1秒,则相位声码器将导致声音质量显着降解。
DDSP
PC-DDSP
软vc
ContentVec
diffsinger(OpenVPI版本)
DIFF-SVC
扩散-SVC


