DDSP SVC
ved DDSP Cascade Diffusion Model
Langue: anglais简体中文 한국어 (obsolète)
(1) Prétraitement:
python preprocess.py -c configs/reflow.yaml(2) Formation :
python train_reflow.py -c configs/reflow.yaml(3) Inférence non réel:
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > «Infer_step» est le nombre d'étapes d'échantillonnage pour ODE-flow rectifié, «Method» est «Euler» ou «RK4», «T_Start» est le point de début de l'ODE, qui doit être supérieur à celle ou égale à t_start dans le fichier de configuration, il est recommandé de le maintenir égal (la valeur de défaut est 0,7)
L'installation des dépendances, la préparation des données, la configuration du codeur pré-formé (Hubert ou ContentVec), de l'extracteur de pitch (RMVPE) et du vocodeur (NSF-HIFIGAN) sont les mêmes que la formation d'un modèle DDSP pur (voir la section ci-dessous).
Nous fournissons un modèle pré-formé dans la page de version.
Déplacez le model_0.pt vers le dossier d'exportation du modèle spécifié par le paramètre 'EXPDIR' dans diffusion-fast.yaml , et le programme chargera automatiquement le modèle pré-formé dans ce dossier.
(1) Prétraitement:
python preprocess.py -c configs/diffusion-fast.yaml(2) Former un modèle en cascade (seulement entraîner un modèle):
python train_diff.py -c configs/diffusion-fast.yaml(3) Inférence non réel:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > Le modèle de version 5.0 dispose d'un modèle DDSP intégré, donc la spécification d'un modèle DDSP externe utilisant -ddsp n'est pas nécessaire. Les autres options ont la même signification que le modèle de version 3.0, mais «Kstep» doit être inférieur ou égal à k_step_max dans le fichier de configuration, il est recommandé de le maintenir égal (la valeur par défaut est 100)
(4) GUI en temps réel:
python gui_diff.pyRemarque: vous devez charger le modèle de version 5.0 sur le côté droit de l'interface graphique
L'installation des dépendances, la préparation des données, la configuration du codeur pré-formé (Hubert ou ContentVec), de l'extracteur de pitch (RMVPE) et du vocodeur (NSF-HIFIGAN) sont les mêmes que la formation d'un modèle DDSP pur (voir la section ci-dessous).
Nous fournissons un modèle pré-entraîné ici: https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolol/main/pre--trainen-model/Model_0.pt (en utilisant 'Contentvec768L12' Encodeur)
Déplacez le model_0.pt vers le dossier d'exportation du modèle spécifié par le paramètre 'EXPDIR' dans diffusion-new.yaml , et le programme chargera automatiquement le modèle pré-formé dans ce dossier.
(1) Prétraitement:
python preprocess.py -c configs/diffusion-new.yaml(2) Former un modèle en cascade (seulement entraîner un modèle):
python train_diff.py -c configs/diffusion-new.yamlRemarque: il y a un problème temporaire avec la formation FP16, mais FP32 et BF16 fonctionnent normalement,
(3) Inférence non réel:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > Le modèle de version 4.0 dispose d'un modèle DDSP intégré, donc la spécification d'un modèle DDSP externe utilisant -ddsp n'est pas nécessaire. Les autres options ont la même signification que le modèle de version 3.0, mais «Kstep» doit être inférieur ou égal à k_step_max dans le fichier de configuration, il est recommandé de le maintenir égal (la valeur par défaut est 100)
(4) GUI en temps réel:
python gui_diff.pyRemarque: vous devez charger le modèle de version 4.0 sur le côté droit de l'interface graphique
L'installation des dépendances, la préparation des données, la configuration de l'encodeur pré-formé (Hubert ou ContentVec), de l'extracteur de pitch (RMVPE) et du vocodeur (NSF-HIFIGAN) sont les mêmes que la formation d'un modèle DDSP pur (voir chapitre 1 ~ 3 ci-dessous).
Parce que le modèle de diffusion est plus difficile à entraîner, nous fournissons ici des modèles pré-formés:
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trainen--model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt (en utilisant 'Hubertsoft' Encoder)
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre--trainen--model/blob/main/fix_pitch_add_vctk_600k/Model_0.pt (Utilisation 'Contentvec768l12' Encoder)
Déplacez le model_0.pt vers le dossier d'exportation du modèle spécifié par le paramètre 'EXPDIR' dans diffusion.yaml , et le programme chargera automatiquement les modèles pré-formés dans ce dossier.
(1) Prétraitement:
python preprocess.py -c configs/diffusion.yamlCe prétraitement peut également être utilisé pour former le modèle DDSP sans prétraitement deux fois, mais vous devez vous assurer que les paramètres sous la balise `` Data '' dans les fichiers YAML sont cohérents.
(2) Former un modèle de diffusion:
python train_diff.py -c configs/diffusion.yaml(3) Former un modèle DDSP:
python train.py -c configs/combsub.yaml Comme mentionné ci-dessus, le re-procédé n'est pas requis, mais veuillez vérifier si les paramètres de combsub.yaml et diffusion.yaml correspondent. Le nombre de locuteurs 'n_spk' peut être incohérent, mais essayez d'utiliser le même ID pour représenter le même haut-parleur (cela facilite l'inférence).
(4) Inférence non réel:
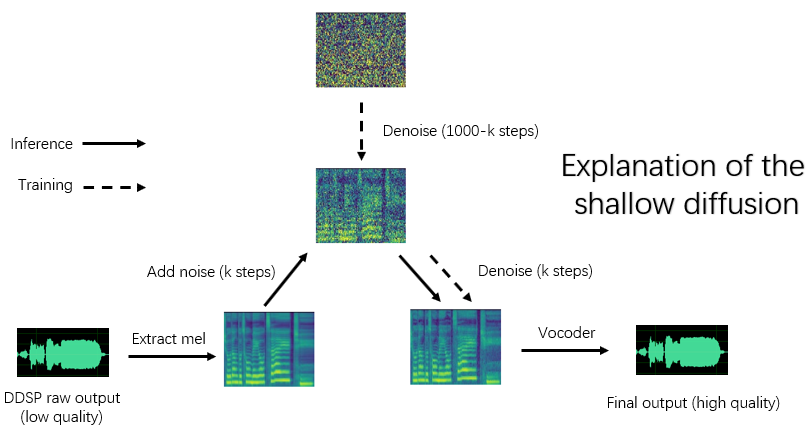
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > `` Speetup '' est la vitesse d'accélération, 'Method' est 'ddim', 'pndm', 'dpm-solver' ou 'unipc', 'kstep' est le nombre d'étapes de diffusion superficielles, 'diffid' est l'ID de haut-parleur du modèle de diffusion, et d'autres paramètres ont la même signification que main.py
Un «Kstep» raisonnable est d'environ 100 à 300. Il peut y avoir une perte perçue de qualité sonore lorsque «accélérer» dépasse 20.
Si le même ID a été utilisé pour représenter le même haut-parleur pendant la formation, «-diffid» peut être vide, sinon l'option «-diffid» doit être spécifiée.
Si «-ddsp» est vide, le modèle de diffusion pur est utilisé, à ce moment, la diffusion peu profonde est effectuée avec la MEL de la source d'entrée, et si un «-kstep» plus vide est vide, une diffusion gaussienne pleine profondeur est effectuée.
Le programme vérifiera automatiquement si les paramètres du modèle DDSP et du modèle de diffusion correspondent (taux d'échantillonnage, taille du houblon et encodeur), et s'ils ne correspondent pas, il ignorera le chargement du modèle DDSP et entrera en mode diffusion gaussien.
(5) GUI en temps réel:
python gui_diff.pyDDSP-SVC est un nouveau projet de conversion vocale chantant open source dédié au développement de logiciels de changeur vocal IA gratuit qui peuvent être popularisés sur des ordinateurs personnels.
Par rapport au célèbre SO-VITS-SVC, sa formation et sa synthèse ont des exigences beaucoup plus faibles pour le matériel informatique, et le temps de formation peut être raccourci par les ordres de grandeur, qui est proche de la vitesse d'entraînement de RVC.
De plus, lors de la réalisation de voix en temps réel, la consommation de ressources matérielles de ce projet est nettement inférieure à celle de So-Vits-SVC , mais probablement légèrement supérieure à la dernière version de RVC.
Bien que la qualité de synthèse d'origine du DDSP ne soit pas idéale (la sortie d'origine peut être entendue dans Tensorboard pendant l'entraînement), après avoir amélioré la qualité sonore avec un amplificateur basé sur des vocodeur pré-formé (ancienne version) ou avec un modèle de diffusion superficiel (nouvelle version), pour certains ensembles de données, il peut atteindre la qualité de synthèse que la qualité de la synthèse que Sovits-SVC et RVC.
Les anciens modèles de versions sont toujours compatibles, les chapitres suivants sont les instructions de l'ancienne version. Certaines opérations de la nouvelle version sont les mêmes, voir les chapitres précédents.
Avertissement: veuillez vous assurer de former uniquement les modèles DDSP-SVC avec des données autorisées légalement obtenues et n'utilisez pas ces modèles et aucun audio qu'ils synthétisent à des fins illégales. L'auteur de ce référentiel n'est pas responsable de toute contrefaçon, fraude et autres actes illégaux causés par l'utilisation de ces points de contrôle et de ces modèles.
Journal de mise à jour: je suis trop paresseux pour traduire, veuillez consulter la version chinoise Readme.
Nous recommandons d'abord d'installer Pytorch sur le site officiel, puis d'exécuter:
pip install -r requirements.txtRemarque: Je ne teste que le code en utilisant Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0, trop neuves ou trop anciennes peuvent ne pas fonctionner
Mise à jour: Python 3.8 (Windows) + CUDA 11.8 + Torch 2.0.0 + Torchaudio 2.0.1 Travaux, et la formation est plus rapide.
(1) Téléchargez l'encodeur ContentVec pré-formé et placez-le dans le dossier pretrain/contentvec .
(2) Téléchargez l'encodeur Hubertsoft pré-formé et placez-le dans le dossier pretrain/hubert , puis modifiez le fichier de configuration en même temps.
Télécharger et dézip le vocodeur NSF-Hifigan pré-formé
Ou utilisez le projet https://github.com/openvpi/SingingVoDers pour affiner le vocodeur pour une qualité sonore plus élevée.
Renommez ensuite le fichier de point de contrôle et placez-le à l'emplacement spécifié par le paramètre 'vocoder.ckpt' dans le fichier de configuration. La valeur par défaut est pretrain/nsf_hifigan/model .
Le «config.json» du vocodeur doit être dans le même répertoire, par exemple, pretrain/nsf_hifigan/config.json .
Téléchargez l'extracteur RMVPE pré-formé et dézippez-le dans un dossier pretrain/ .
Mettez tout l'ensemble de données de formation (.wav format Clips audio) dans le répertoire ci-dessous: data/train/audio . Mettez tout l'ensemble de données de validation (.Wav Format Audio Clips) dans le répertoire ci-dessous: data/val/audio . Vous pouvez également courir
python draw.py Pour vous aider à sélectionner les données de validation (vous pouvez ajuster les paramètres dans draw.py pour modifier le nombre de fichiers extraits et d'autres paramètres)
Puis courez
python preprocess.py -c configs/combsub.yamlpour un modèle de synthétiseur soudés
python preprocess.py -c configs/sins.yamlPour un modèle de synthétiseur additif des sinusoïdes.
Pour la formation du modèle de diffusion, voir la section 3.0, 4.0 ou 5.0 ci-dessus.
Vous pouvez modifier le fichier de configuration config/<model_name>.yaml avant le prétraitement. La configuration par défaut convient à la formation de synthétiseur de taux d'échantillonnage élevé 44.1 kHz avec carte graphique GTX-1660.
Remarque 1: Veuillez conserver le taux d'échantillonnage de tous les clips audio cohérents avec le taux d'échantillonnage dans le fichier de configuration YAML! S'il n'est pas cohérent, le programme peut être exécuté en toute sécurité, mais le rééchantillonnage pendant le processus de formation sera très lent.
Remarque 2: Le nombre total des clips audio pour l'ensemble de données de formation est recommandé d'être environ 1000, en particulier le long clip audio peut être coupé en segments courts, ce qui accélérera la formation, mais la durée de tous les clips audio ne devrait pas être inférieure à 2 secondes. S'il y a trop de clips audio, vous avez besoin d'une grande mémoire interne ou définissez l'option 'Cache_all_data' sur FALSE dans le fichier de configuration.
Remarque 3: Le nombre total des clips audio pour l'ensemble de données de validation est recommandé d'être environ 10, veuillez ne pas en mettre trop ou il sera très lent de faire la validation.
Remarque 4: Si votre ensemble de données n'est pas de très haute qualité, définissez «F0_Extractor» à «RMVPE» dans le fichier de configuration.
Remarque 5: La formation multi-haut-parleurs est prise en charge maintenant. Le paramètre 'n_spk' dans le fichier de configuration contrôle s'il s'agit d'un modèle multi-haut-parleurs. Si vous souhaitez former un modèle multi-haut-parleurs , les dossiers audio doivent être nommés avec des entiers positifs pas plus que «n_spk» pour représenter les identifiants de haut-parleurs, la structure du répertoire est comme ci-dessous:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...Si 'n_spk' = 1, la structure du répertoire du modèle de haut-parleur unique est toujours prise en charge, ce qui est comme ci-dessous:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yamlLa ligne de commande pour la formation d'autres modèles est similaire.
Vous pouvez interrompre la formation en toute sécurité, puis exécuter la même ligne de commande reprendra la formation.
Vous pouvez également FineTune le modèle si vous interrompez la formation d'abord, puis re-procéder le nouvel ensemble de données ou modifier les paramètres de formation (BatchSize, LR etc.), puis exécuter la même ligne de commande.
# check the training status using tensorboard
tensorboard --logdir=expLes échantillons audio de test seront visibles dans Tensorboard après la première validation.
Remarque: Les échantillons audio de test dans Tensorboard sont les sorties d'origine de votre modèle DDSP-SVC qui n'est pas améliorée par un amplificateur. Si vous souhaitez tester l'effet synthétique après l'utilisation de l'emplacement (qui peut avoir une qualité supérieure), veuillez utiliser la méthode décrite dans le chapitre suivant.
;
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >Sortie brute du DDSP:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseAutres options sur l'extracteur F0 et la réponse à trois hold , Voir:
python main.py -h(Mise à jour) Mix-Speaker est maintenant pris en charge. Vous pouvez utiliser l'option "-mix" pour concevoir votre propre timbre vocal, ci-dessous est un exemple:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0Démarrez une interface graphique simple avec la commande suivante:
python gui.pyLe front-end utilise des technologies telles que la fenêtre coulissante, la transmission croisée, l'épissage basé sur Sola et la référence sémantique contextuelle, qui peut atteindre une qualité sonore proche de la synthèse non réel avec une faible latence et une occupation des ressources.
MISE À JOUR: Un algorithme d'épissage basé sur un vocodeur de phase est maintenant ajouté, mais dans la plupart des cas, l'algorithme SOLA a déjà une qualité sonore d'épissage suffisamment élevée, il est donc désactivé par défaut. Si vous poursuivez une qualité sonore en temps réel à faible latence extrême, vous pouvez envisager de l'allumer et de régler soigneusement les paramètres, et il est possible que la qualité sonore soit plus élevée. Cependant, un grand nombre de tests ont montré que si le temps croisé est supérieur à 0,1 seconde, le vocodeur de phase provoquera une dégradation significative de la qualité sonore.
DDSP
PC-DDSP
soft-VC
Contentvec
DiffSinger (version OpenVPI)
Diff-svc
Diffusion-svc


