DDSP SVC
ved DDSP Cascade Diffusion Model
언어 : 영어 한국어简体中文 简体中文 简体中文 (구식)
(1) 전처리 :
python preprocess.py -c configs/reflow.yaml(2) 훈련 :
python train_reflow.py -c configs/reflow.yaml(3) 비실한 시간 추론 :
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > 'intre_step'은 정류-흐름 ODE에 대한 샘플링 단계 수입니다. '메소드'는 'euler'또는 'rk4', 't_start'는 ODE의 시작 시점입니다. 구성 파일에서 t_start 보다 크거나 동일해야합니다.
종속성, 데이터 준비, 미리 훈련 된 인코더 (Hubert 또는 ContentVec), 피치 추출기 (RMVPE) 및 보코더 (NSF-Hifigan) 설치는 순수한 DDSP 모델을 훈련하는 것과 동일합니다 (아래 섹션 참조).
릴리스 페이지에서 미리 훈련 된 모델을 제공합니다.
model_0.pt 를 diffusion-fast.yaml 의 'expdir'매개 변수로 지정된 모델 내보내기 폴더로 이동하면 프로그램이 해당 폴더에 미리 훈련 된 모델을 자동으로로드합니다.
(1) 전처리 :
python preprocess.py -c configs/diffusion-fast.yaml(2) 캐스케이드 모델 훈련 (하나의 모델 만 기차) :
python train_diff.py -c configs/diffusion-fast.yaml(3) 비실한 시간 추론 :
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 5.0 버전 모델에는 내장 DDSP 모델이 있으므로 -ddsp 사용하여 외부 DDSP 모델을 지정하는 것은 불필요합니다. 다른 옵션은 3.0 버전 모델과 동일한 의미를 지니고 있지만 구성 파일에서 'KSTEP'는 k_step_max 보다 작거나 동일해야하므로 동일하게 유지하는 것이 좋습니다 (기본값은 100입니다).
(4) 실시간 GUI :
python gui_diff.py참고 : GUI의 오른쪽에 버전 5.0 모델을로드해야합니다.
종속성, 데이터 준비, 미리 훈련 된 인코더 (Hubert 또는 ContentVec), 피치 추출기 (RMVPE) 및 보코더 (NSF-Hifigan) 설치는 순수한 DDSP 모델을 훈련하는 것과 동일합니다 (아래 섹션 참조).
우리는 여기에 미리 훈련 된 모델을 제공합니다 : https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/pre-trained-model/model_0.pt ( 'contentVec768L12'인코더 사용).
model_0.pt 를 diffusion-new.yaml 의 'Expdir'매개 변수로 지정된 모델 내보내기 폴더로 이동하면 프로그램이 해당 폴더에 미리 훈련 된 모델을 자동으로로드합니다.
(1) 전처리 :
python preprocess.py -c configs/diffusion-new.yaml(2) 캐스케이드 모델 훈련 (하나의 모델 만 기차) :
python train_diff.py -c configs/diffusion-new.yaml참고 : FP16 교육에는 일시적인 문제가 있지만 FP32와 BF16은 정상적으로 작동하고 있습니다.
(3) 비실한 시간 추론 :
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 4.0 버전 모델에는 내장 DDSP 모델이 있으므로 -ddsp 사용하여 외부 DDSP 모델을 지정하는 것은 불필요합니다. 다른 옵션은 3.0 버전 모델과 동일한 의미를 지니고 있지만 구성 파일에서 'KSTEP'는 k_step_max 보다 작거나 동일해야하므로 동일하게 유지하는 것이 좋습니다 (기본값은 100입니다).
(4) 실시간 GUI :
python gui_diff.py참고 : GUI의 오른쪽에 버전 4.0 모델을로드해야합니다.
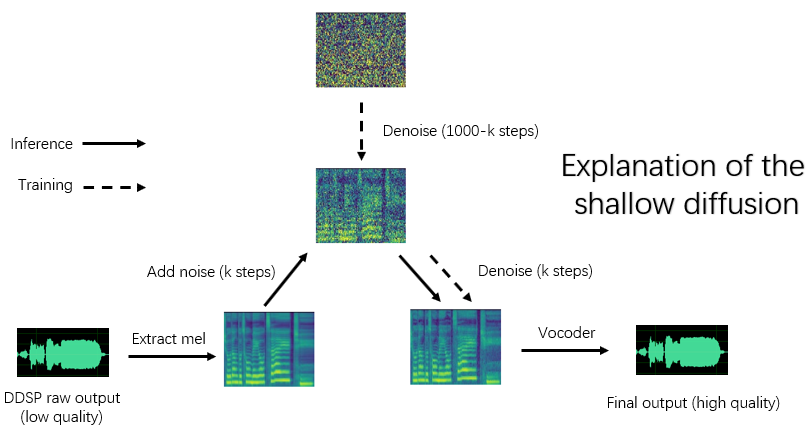
종속성, 데이터 준비, 미리 훈련 된 인코더 (Hubert 또는 ContentVec), 피치 추출기 (RMVPE) 및 보코더 (NSF-Hifigan)를 구성하는 것은 순수한 DDSSP 모델을 훈련하는 것과 동일합니다 (아래 1 장 ~ 3 장 참조).
확산 모델은 훈련하기가 더 어렵 기 때문에 여기에 미리 훈련 된 모델을 제공합니다.
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt ( 'Hubertsoft'Encoder 사용)
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/fix_pitch_add_vctk_600k/model_0.pt ( 'contentVec768L12'Encoder 사용)
diffusion.yaml 의 'expdir'매개 변수로 지정된 모델 내보내기 폴더로 model_0.pt 이동하면 해당 폴더에 미리 훈련 된 모델을 자동으로로드합니다.
(1) 전처리 :
python preprocess.py -c configs/diffusion.yaml이 전처리는 또한 전처리하지 않고 DDSP 모델을 훈련시키는 데 사용될 수 있지만 Yaml 파일의 '데이터'태그 아래 매개 변수가 일관되도록해야합니다.
(2) 확산 모델 훈련 :
python train_diff.py -c configs/diffusion.yaml(3) DDSP 모델 훈련 :
python train.py -c configs/combsub.yaml 위에서 언급했듯이 재 처리 필요는 없지만 combsub.yaml 및 diffusion.yaml 의 매개 변수가 있는지 확인하십시오. 스피커 'N_SPK'의 수는 일관성이 없지만 동일한 ID를 사용하여 동일한 스피커를 나타냅니다 (이를 통해 추론이 더 쉬워집니다).
(4) 비실한 시간 추론 :
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 'SpeedUp'은 가속 속도, '메소드'는 'ddim', 'pndm', 'dpm-solver'또는 'unipc', 'kstep'은 얕은 확산 단계의 수, 'diffid'는 확산 모델의 스피커 ID이며 다른 매개 변수는 main.py 와 동일한 의미를 갖습니다.
합리적인 'kstep'은 약 100 ~ 300입니다. '속도 업'이 20을 초과 할 때 음질의 손실이 인식 될 수 있습니다.
훈련 중에 동일한 ID가 동일한 스피커를 나타내는 데 사용 된 경우 '-diffid'를 비울 수 있습니다. 그렇지 않으면 '-diffid'옵션을 지정해야합니다.
'-ddsp'가 비어 있으면 순수한 확산 모델이 사용됩니다.이 시점에서는 입력 소스의 Mel과 함께 얕은 확산이 수행되며, 더 이상 '-kstep'이 비어있는 경우 가우시안 확산이 수행됩니다.
이 프로그램은 DDDSP 모델의 매개 변수와 확산 모델 일치 (샘플링 속도, 홉 크기 및 인코더)가 자동으로 확인되며 일치하지 않으면 DDSP 모델로드를 무시하고 가우스 확산 모드를 입력합니다.
(5) 실시간 GUI :
python gui_diff.pyDDSP-SVC는 개인용 컴퓨터에서 대중화 될 수있는 무료 AI Voice Changer 소프트웨어 개발에 전념하는 새로운 오픈 소스 노래 음성 변환 프로젝트입니다.
유명한 SO-VITS-SVC와 비교할 때 교육 및 합성은 컴퓨터 하드웨어에 대한 요구 사항이 훨씬 낮으며 교육 시간은 RVC의 교육 속도에 가까운 규모로 단축 될 수 있습니다.
또한 실시간 음성 변경을 수행 할 때이 프로젝트의 하드웨어 리소스 소비는 So-Vits-SVC의 하드웨어 리소스 소비보다 훨씬 낮지 만 최신 버전의 RVC보다 약간 높습니다.
DDSP의 원래 합성 품질이 이상적이지는 않지만 (원래 출력은 훈련하는 동안 원래 출력을들을 수 있음), 미리 훈련 된 보코더 기반 인핸서 (구 버전) 또는 일부 데이터 세트의 얕은 확산 모델 (새 버전)으로 음질을 향상시킨 후 Sovits-SVC 및 RVC보다 합성 품질을 달성 할 수 있습니다.
이전 버전 모델은 여전히 호환되며 다음 장은 이전 버전의 지침입니다. 새 버전의 일부 작업은 동일합니다. 이전 장을 참조하십시오.
면책 조항 : 법적으로 얻은 승인 된 데이터 로 DDSP-SVC 모델 만 훈련하고 불법적 인 목적으로 합성하는 이러한 모델과 오디오를 사용하지 마십시오. 이 저장소의 저자는 이러한 모델 체크 포인트 및 오디오를 사용하여 발생하는 침해, 사기 및 기타 불법 행위에 대해 책임을지지 않습니다.
업데이트 로그 : 번역하기에는 너무 게으르고 중국어 버전 readme를 참조하십시오.
먼저 공식 웹 사이트에서 Pytorch를 설치 한 다음 실행하는 것이 좋습니다.
pip install -r requirements.txt참고 : Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0을 사용하여 코드를 테스트합니다. 너무 새롭거나 오래된 종속성이 작동하지 않을 수 있습니다.
업데이트 : Python 3.8 (Wind
(1) 사전 훈련 된 ContentVec 인코더를 다운로드하여 pretrain/contentvec 폴더에 넣습니다.
(2) 미리 훈련 된 Hubertsoft 인코더를 다운로드하여 pretrain/hubert 폴더 아래에 넣은 다음 구성 파일을 동시에 수정하십시오.
미리 훈련 된 NSF-Hifigan 보코더를 다운로드하여 압축 해제하십시오
또는 더 높은 음질을 위해 https://github.com/openvpi/singingvocoders 프로젝트를 사용하여 보코더를 미세 조정하십시오.
그런 다음 Checkpoint 파일의 이름을 바꾸고 구성 파일에 'vocoder.ckpt'매개 변수로 지정된 위치에 배치하십시오. 기본값은 pretrain/nsf_hifigan/model 입니다.
보코더의 'config.json'은 동일한 디렉토리 (예 : pretrain/nsf_hifigan/config.json 에 있어야합니다.
미리 훈련 된 RMVPE 추출기를 다운로드하여 pretrain/ 폴더로 압축 해제하십시오.
모든 교육 데이터 세트 (.wav 형식 오디오 클립)를 아래 디렉토리 : data/train/audio 에 넣습니다. 아래 디렉토리에 모든 유효성 검사 데이터 세트 (.wav 형식 오디오 클립)를 넣으십시오 : data/val/audio . 당신은 또한 실행할 수 있습니다
python draw.py 유효성 검사 데이터를 선택할 수 있도록 (추출 된 파일 및 기타 매개 변수 수를 수정하기 위해 draw.py 에서 매개 변수를 조정할 수 있음)
그런 다음 실행하십시오
python preprocess.py -c configs/combsub.yaml콤 송투 잠술 신디사이저 ( 추천 ) 또는 실행 모델의 경우
python preprocess.py -c configs/sins.yamlSinusoids 첨가제 신시사이저 모델의 경우.
확산 모델을 훈련하려면 위의 섹션 3.0, 4.0 또는 5.0을 참조하십시오.
전처리하기 전에 구성 파일 config/<model_name>.yaml 수정할 수 있습니다. 기본 구성은 GTX-1660 그래픽 카드로 44.1kHz 높은 샘플링 속도 신시사이저를 교육하는 데 적합합니다.
참고 1 : Yaml 구성 파일의 샘플링 속도와 일치하는 모든 오디오 클립의 샘플링 속도를 유지하십시오! 일관되지 않으면 프로그램을 안전하게 실행할 수 있지만 교육 과정에서 리샘플링은 매우 느립니다.
참고 2 : 훈련 데이터 세트를위한 오디오 클립의 총 수는 약 1000이 권장되며, 특히 긴 오디오 클립은 짧은 세그먼트로자를 수있어 훈련 속도를 높일 수 있지만 모든 오디오 클립의 지속 시간은 2 초 이상이어야합니다. 오디오 클립이 너무 많으면 큰 내부 메모리가 필요하거나 구성 파일에서 'cache_all_data'옵션을 False로 설정해야합니다.
참고 3 : 유효성 검사 데이터 세트를위한 오디오 클립의 총 수는 약 10이 권장됩니다. 너무 많이 넣지 마십시오. 유효성 검사를 수행하는 데는 매우 느립니다.
참고 4 : 데이터 세트가 품질이 높지 않은 경우 구성 파일에서 'F0_Extractor'를 'RMVPE'로 설정하십시오.
참고 5 : 다중 스피커 교육이 지원됩니다. 구성 파일의 'N_SPK'매개 변수는 멀티 스피커 모델인지 여부를 제어합니다. 멀티 스피커 모델을 훈련 시키려면 스피커 ID를 나타 내기 위해 'N_SPK'보다 긍정적 인 정수 로 오디오 폴더를 명명해야합니다. 디렉토리 구조는 다음과 같습니다.
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...'n_spk'= 1 인 경우 단일 스피커 모델의 디렉토리 구조는 여전히 지원됩니다.
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yaml다른 모델을 훈련하기위한 명령 줄은 비슷합니다.
교육을 안전하게 방해 할 수 있으며 동일한 명령 줄을 실행하면 교육이 재개됩니다.
교육을 먼저 방해하는 경우 모델을 정합 한 다음 새 데이터 세트를 다시 대변하거나 교육 매개 변수 (Batchsize, LR 등)를 변경 한 다음 동일한 명령 줄을 실행할 수도 있습니다.
# check the training status using tensorboard
tensorboard --logdir=exp테스트 오디오 샘플은 첫 번째 유효성 검사 후 텐서 보드에서 볼 수 있습니다.
참고 : Tensorboard의 테스트 오디오 샘플은 인핸서에 의해 향상되지 않은 DDSP-SVC 모델의 원래 출력입니다. 인ancer (품질이 높을 수 있음)를 사용한 후 합성 효과를 테스트하려면 다음 장에 설명 된 방법을 사용하십시오.
( 권장 ) 사전 배치 된 보코더 기반 인핸서를 사용하여 출력을 향상시킵니다.
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >DDSP의 원시 출력 :
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseF0 추출기 및 응답 threhold에 대한 기타 옵션은 다음을 참조하십시오.
python main.py -h(업데이트) 믹스 스피커가 이제 지원되었습니다. "-mix"옵션을 사용하여 자신의 보컬 음색을 설계 할 수 있습니다. 아래는 예입니다.
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0다음 명령으로 간단한 GUI를 시작하십시오.
python gui.py프론트 엔드는 슬라이딩 윈도우, 크로스 페이딩, 솔라 기반 스 플라이 싱 및 상황에 맞는 의미 론적 참조와 같은 기술을 사용하여 낮은 대기 시간 및 자원 점령으로 비실한 시간 합성에 가까운 음질을 달성 할 수 있습니다.
업데이트 : 위상 보코더를 기반으로 한 스 플라이 싱 알고리즘이 추가되었지만 대부분의 경우 SOLA 알고리즘은 이미 충분히 높은 스 플라이 싱 음질을 가지고 있으므로 기본적으로 꺼져 있습니다. 극도로 저렴한 실시간 실시간 음질을 추구하는 경우 매개 변수를 조심스럽게 켜고 조정하는 것을 고려할 수 있으며 음질이 더 높아질 가능성이 있습니다. 그러나 많은 수의 테스트에 따르면 크로스 페이드 시간이 0.1 초 미만이면 위상 보코더는 음질이 상당한 저하를 일으킬 것입니다.
DDSP
PC-DDSP
소프트 VC
ContentVec
Diffsinger (OpenVPI 버전)
diff-svc
확산 -SVC


