DDSP SVC
ved DDSP Cascade Diffusion Model
言語:英語简体中文简体中文時代遅れ)
(1)前処理:
python preprocess.py -c configs/reflow.yaml(2)トレーニング:
python train_reflow.py -c configs/reflow.yaml(3)非現実的な推論:
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > 'Imber_Step'は修正フローODEのサンプリングステップの数、「メソッド」は「オイラー」または「RK4」、「T_START」はODEの開始時点であり、構成ファイルではt_start以上である必要があります。
依存関係、データの準備、事前に訓練されたエンコーダー(HubertまたはContentVec)、ピッチ抽出器(RMVPE)、ボコーダー(NSF-Hifigan)の設定は、純粋なDDSPモデルのトレーニングと同じです(以下のセクションを参照)。
リリースページで事前に訓練されたモデルを提供します。
model_0.pt diffusion-fast.yamlの「expdir」パラメーターで指定されたモデルエクスポートフォルダーに移動すると、プログラムはそのフォルダーに事前に訓練されたモデルを自動的にロードします。
(1)前処理:
python preprocess.py -c configs/diffusion-fast.yaml(2)カスケードモデルのトレーニング(1つのモデルのみを訓練する):
python train_diff.py -c configs/diffusion-fast.yaml(3)非現実的な推論:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 5.0バージョンモデルには組み込みのDDSPモデルがあるため、 -ddspを使用して外部DDSPモデルを指定するのは不要です。他のオプションは3.0バージョンモデルと同じ意味を持っていますが、「kStep」は構成ファイルのk_step_maxよりも低い必要があります。
(4)リアルタイムGUI:
python gui_diff.py注:GUIの右側にバージョン5.0モデルをロードする必要があります
依存関係、データの準備、事前に訓練されたエンコーダー(HubertまたはContentVec)、ピッチ抽出器(RMVPE)、ボコーダー(NSF-Hifigan)の設定は、純粋なDDSPモデルのトレーニングと同じです(以下のセクションを参照)。
事前に訓練されたモデルをここで提供します:https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/pre-trained-model/model_0.pt( 'contentvec768l12' encoderを使用)
model_0.pt diffusion-new.yamlの「expdir」パラメーターで指定されたモデルエクスポートフォルダーに移動すると、プログラムはそのフォルダーに事前に訓練されたモデルを自動的にロードします。
(1)前処理:
python preprocess.py -c configs/diffusion-new.yaml(2)カスケードモデルのトレーニング(1つのモデルのみを訓練する):
python train_diff.py -c configs/diffusion-new.yaml注:FP16トレーニングには一時的な問題がありますが、FP32とBF16は正常に機能しています。
(3)非現実的な推論:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 4.0バージョンモデルには組み込みのDDSPモデルがあるため、 -ddspを使用して外部DDSPモデルを指定するのは不要です。他のオプションは3.0バージョンモデルと同じ意味を持っていますが、「kStep」は構成ファイルのk_step_maxよりも低い必要があります。
(4)リアルタイムGUI:
python gui_diff.py注:GUIの右側にバージョン4.0モデルをロードする必要があります
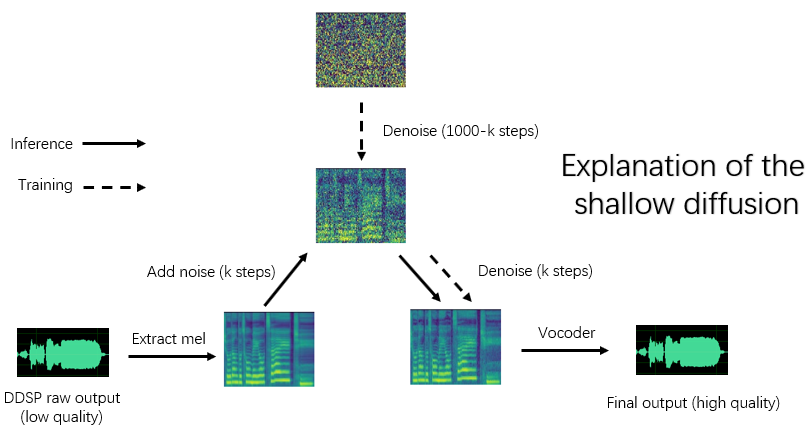
依存関係、データの準備、事前に訓練されたエンコーダー(HubertまたはContentVec)、ピッチ抽出器(RMVPE)、ボコーダー(NSF-Hifigan)の設定は、純粋なDDSPモデルのトレーニングと同じです(以下の第1章〜3を参照)。
拡散モデルはトレーニングがより困難であるため、ここで事前に訓練されたモデルを提供します。
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt( 'hubertsoft' encoderer)
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/fix_pitch_add_vctk_600k/model_0.pt( 'contentvec768l12' encoderを使用)
diffusion.yamlの「expdir」パラメーターで指定されたモデルエクスポートフォルダーにmodel_0.ptを移動すると、プログラムはそのフォルダーに事前に訓練されたモデルを自動的にロードします。
(1)前処理:
python preprocess.py -c configs/diffusion.yamlこの前処理は、Preprocessingを2回前に処理することなくDDSPモデルをトレーニングするためにも使用できますが、YAMLファイルの「データ」タグの下のパラメーターが一貫していることを確認する必要があります。
(2)拡散モデルをトレーニングする:
python train_diff.py -c configs/diffusion.yaml(3)DDSPモデルのトレーニング:
python train.py -c configs/combsub.yaml上記のように、再プロセスは必要ありませんが、 combsub.yamlとdiffusion.yamlのパラメーターが一致するかどうかを確認してください。スピーカーの数は一貫性がない場合がありますが、同じスピーカーを表すために同じIDを使用してみてください(これにより、推論が簡単になります)。
(4)非現実的な推論:
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 「スピードアップ」は加速速度であり、「メソッド」は「DDIM」、「PNDM」、「DPM-SOLVER」、または「UNIPC」、「KSTEP」は浅い拡散ステップの数、「拡散モデルのスピーカーID」であり、その他のパラメーターはmain.pyと同じ意味を持っています。
合理的な「KSTEP」は約100〜300です。 「スピードアップ」が20を超えると、音質の損失が認識される場合があります。
同じIDがトレーニング中に同じスピーカーを表すために使用されている場合、「-diffid」は空になる可能性があります。そうしないと、「-diffid」オプションを指定する必要があります。
'-ddsp'が空の場合、純粋な拡散モデルが使用されます。現時点では、入力ソースのMELで浅い拡散が実行され、さらに「kStep」が空である場合、完全なガウス拡散が実行されます。
プログラムは、DDSPモデルのパラメーターと拡散モデルの一致(サンプリングレート、ホップサイズ、エンコーダ)のかどうかを自動的に確認し、一致しない場合、DDSPモデルのロードを無視してガウス拡散モードに入ります。
(5)リアルタイムGUI:
python gui_diff.pyDDSP-SVCは、パーソナルコンピューターで普及できる無料のAI音声チェンジャーソフトウェアの開発専用の新しいオープンソースの歌声変換プロジェクトです。
有名なSO-Vits-SVCと比較して、そのトレーニングと合成はコンピューターハードウェアの要件がはるかに低く、トレーニング時間はRVCのトレーニング速度に近い桁違いに短縮できます。
さらに、リアルタイムの音声変更を実行する場合、このプロジェクトのハードウェアリソース消費量は、SO-Vits-SVCのハードウェアリソース消費量よりも大幅に低くなりますが、おそらくRVCの最新バージョンよりもわずかに高くなります。
DDSPの元の合成品質は理想的ではありません(トレーニング中にテンソルボードで元の出力を聞くことができます)が、事前に訓練されたボコーダーベースのエンハンサー(古いバージョン)または浅い拡散モデル(新しいバージョン)で音質を向上させた後、一部のデータセットでは、ソビットSVCおよびRVC以下で合成品質を実現できます。
古いバージョンモデルはまだ互換性があり、次の章は古いバージョンの指示です。新しいバージョンの一部の操作は同じです。前の章を参照してください。
免責事項:法的に取得された承認されたデータを使用してDDSP-SVCモデルのみをトレーニングするようにしてください。これらのモデルや違法な目的で合成するオーディオは使用しないようにしてください。このリポジトリの著者は、これらのモデルチェックポイントとオーディオの使用によって引き起こされる侵害、詐欺、その他の違法行為について責任を負いません。
更新ログ:翻訳するにはあまりにも怠惰です。中国語版のreadmeをご覧ください。
公式ウェブサイトからPytorchを最初にインストールしてから実行することをお勧めします。
pip install -r requirements.txt注:Python 3.8(Windows) + Torch 1.9.1 + Torchaudio 0.6.0を使用してコードのみをテストします。
更新:Python 3.8(Windows) + Cuda 11.8 + Torch 2.0.0 + Torchaudio 2.0.1の動作が高くなります。
(1)事前に訓練されたContentVecエンコーダーをダウンロードし、 pretrain/contentvecフォルダーの下に置きます。
(2)事前に訓練されたHubertSoftエンコーダーをダウンロードして、それをpretrain/hubertフォルダーの下に配置し、同時に構成ファイルを変更します。
事前に訓練されたNSF-Hifiganボコーダーをダウンロードして解凍します
または、https://github.com/openvpi/singingvocodersプロジェクトを使用して、音質の高いようにボコーダーを微調整します。
次に、チェックポイントファイルの名前を変更し、構成ファイルの「vocoder.ckpt」パラメーターで指定された場所に配置します。デフォルト値はpretrain/nsf_hifigan/modelです。
ボコーダーの「config.json」は、たとえばpretrain/nsf_hifigan/config.jsonなど、同じディレクトリにある必要があります。
事前に訓練されたRMVPE抽出器をダウンロードして、それをpretrain/フォルダーに解凍します。
すべてのトレーニングデータセット(.WAV形式のオーディオクリップ)を以下のディレクトリ: data/train/audioに入れます。すべての検証データセット(.WAV形式のオーディオクリップ)を以下のディレクトリ: data/val/audioに配置します。実行することもできます
python draw.py検証データを選択するのに役立ちます( draw.pyのパラメーターを調整して、抽出されたファイルとその他のパラメーターの数を変更できます)
その後、実行します
python preprocess.py -c configs/combsub.yamlcombtooth subtractiveシンセサイザーのモデル(推奨)または実行
python preprocess.py -c configs/sins.yamlsinusoids添加剤シンセサイザーのモデル用。
拡散モデルのトレーニングについては、上記のセクション3.0、4.0、または5.0を参照してください。
Preprocessingの前に、構成ファイルconfig/<model_name>.yamlを変更できます。デフォルトの構成は、GTX-1660グラフィックスカードを備えた44.1kHzの高サンプリングレートシンセサイザーのトレーニングに適しています。
注1:すべてのオーディオクリップのサンプリングレートを、YAML構成ファイルのサンプリングレートと一致させてください!一貫性がない場合、プログラムは安全に実行できますが、トレーニングプロセス中の再サンプリングは非常に遅くなります。
注2:トレーニングデータセットのオーディオクリップの総数は約1000であることをお勧めします。特に、長いオーディオクリップを短いセグメントにカットすることができます。オーディオクリップが多すぎる場合は、大きな内部メモリが必要であるか、構成ファイルに「cache_all_data」オプションをfalseに設定する必要があります。
注3:検証データセットのオーディオクリップの総数は約10になることをお勧めします。あまり多くを入れないでください。そうしないと、検証を行うのが非常に遅くなります。
注4:データセットが非常に高品質でない場合は、構成ファイルに「f0_extractor」を「rmvpe」に設定します。
注5:現在、マルチスピーカートレーニングがサポートされています。構成ファイルの「N_SPK」パラメーターは、マルチスピーカーモデルかどうかを制御します。マルチスピーカーモデルをトレーニングする場合は、スピーカーIDを表すために「N_SPK」以下の正の整数でオーディオフォルダーに名前を付ける必要があります。ディレクトリ構造は以下のようです。
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...'n_spk' = 1の場合、単一のスピーカーモデルのディレクトリ構造がまだサポートされています。これは以下のようです。
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yaml他のモデルをトレーニングするためのコマンドラインは似ています。
トレーニングを安全に中断し、同じコマンドラインを実行するとトレーニングを再開できます。
最初にトレーニングを中断した場合にモデルをFintuneし、次に新しいデータセットを再プロセスするか、トレーニングパラメーター(BatchSize、LRなど)を変更してから同じコマンドラインを実行することもできます。
# check the training status using tensorboard
tensorboard --logdir=expテストオーディオサンプルは、最初の検証後にテンソルボードで表示されます。
注:テンソルボードのテストオーディオサンプルは、エンハンサーによって強化されていないDDSP-SVCモデルの元の出力です。エンハンサーを使用した後に合成効果をテストしたい場合(高品質の可能性があります)、次の章で説明した方法を使用してください。
(推奨)前提条件のボコーダーベースのエンハンサーを使用して出力を強化します。
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >DDSPの生の出力:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseF0抽出装置と応答の3つについてのその他のオプション、参照してください。
python main.py -h(更新)ミックススピーカーが現在サポートされています。 「-Mix」オプションを使用して、以下の例です。
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0次のコマンドで簡単なGUIを開始します。
python gui.pyフロントエンドは、スライドウィンドウ、クロスフェード、ソラベースのスプライシング、コンテキストセマンティックリファレンスなどのテクノロジーを使用します。これらは、低レイテンシとリソースの職業を備えた非現実的な合成に近い音質を実現できます。
更新:位相ボコーダーに基づいたスプライシングアルゴリズムが追加されるようになりましたが、ほとんどの場合、Solaアルゴリズムはすでに十分なスプライシングサウンド品質を持っているため、デフォルトでオフになります。極端に低い低下のリアルタイムの音質を追求している場合は、それをオンにしてパラメーターを慎重に調整することを検討できます。音質が高くなる可能性があります。ただし、多数のテストでは、クロスフェード時間が0.1秒より長い場合、位相ボコーダーが音質に大幅な分解を引き起こすことがわかりました。
DDSP
PC-DDSP
ソフトVC
contentvec
diffsinger(openvpiバージョン)
diff-svc
拡散SVC


