DDSP SVC
ved DDSP Cascade Diffusion Model
اللغة: اللغة الإنجليزية简体中文 한국어 (عفا عليها الزمن)
(1) المعالجة المسبقة :
python preprocess.py -c configs/reflow.yaml(2) التدريب :
python train_reflow.py -c configs/reflow.yaml(3) الاستدلال غير الحقيقي :
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > "infer_step" هو عدد خطوات أخذ العينات لفصوص التدفق المصححة ، "الطريقة" هي "Euler" أو "RK4" ، "T_START" هي النقطة الزمنية للفرد ، والتي تحتاج إلى أن تكون أكبر من أو تساوي t_start في ملف التكوين ، ويُنصح بالحفاظ عليه متساويًا (الافتراضي هو 0.7)
إن تثبيت التبعيات ، وإعداد البيانات ، وتكوين المشفر الذي تم تدريبه مسبقًا (Hubert أو ContentVec) ، ومستخرج الملعب (RMVPE) و Vocoder (NSF-Hifigan) هو نفس تدريب نموذج DDSP الخالص (انظر القسم أدناه).
نحن نقدم نموذجًا تم تدريبه مسبقًا في صفحة الإصدار.
انقل model_0.pt إلى مجلد تصدير النموذج المحدد بواسطة المعلمة "expdir" في diffusion-fast.yaml .
(1) المعالجة المسبقة :
python preprocess.py -c configs/diffusion-fast.yaml(2) تدريب نموذج تتالي (تدريب نموذج واحد فقط) :
python train_diff.py -c configs/diffusion-fast.yaml(3) الاستدلال غير الحقيقي :
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > يحتوي نموذج الإصدار 5.0 على نموذج DDSP مدمج ، لذلك فإن تحديد نموذج DDSP الخارجي باستخدام -ddsp غير ضروري. الخيارات الأخرى لها نفس المعنى مثل نموذج الإصدار 3.0 ، ولكن يجب أن تكون "KSTEP" أقل من أو تساوي k_step_max في ملف التكوين ، يوصى بإبقائه متساوًا (الافتراضي هو 100)
(4) واجهة المستخدم الرسومية في الوقت الحقيقي :
python gui_diff.pyملاحظة: تحتاج إلى تحميل نموذج الإصدار 5.0 على الجانب الأيمن من واجهة المستخدم الرسومية
إن تثبيت التبعيات ، وإعداد البيانات ، وتكوين المشفر الذي تم تدريبه مسبقًا (Hubert أو ContentVec) ، ومستخرج الملعب (RMVPE) و Vocoder (NSF-Hifigan) هو نفس تدريب نموذج DDSP الخالص (انظر القسم أدناه).
نحن نقدم نموذجًا مسبقًا هنا: https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/pre-trocrained-model/model_pt (باستخدام "contentVEC768L12".
انقل model_0.pt إلى مجلد تصدير النموذج المحدد بواسطة المعلمة "expdir" في diffusion-new.yaml ، وسيقوم البرنامج تلقائيًا بتحميل النموذج الذي تم تدريبه مسبقًا في هذا المجلد.
(1) المعالجة المسبقة :
python preprocess.py -c configs/diffusion-new.yaml(2) تدريب نموذج تتالي (تدريب نموذج واحد فقط) :
python train_diff.py -c configs/diffusion-new.yamlملاحظة: هناك مشكلة مؤقتة في تدريب FP16 ، لكن FP32 و BF16 يعملان بشكل طبيعي ،
(3) الاستدلال غير الحقيقي :
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > يحتوي نموذج الإصدار 4.0 على نموذج DDSP مدمج ، لذلك فإن تحديد نموذج DDSP الخارجي باستخدام -ddsp أمر غير ضروري. الخيارات الأخرى لها نفس المعنى مثل نموذج الإصدار 3.0 ، ولكن يجب أن تكون "KSTEP" أقل من أو تساوي k_step_max في ملف التكوين ، يوصى بإبقائه متساوًا (الافتراضي هو 100)
(4) واجهة المستخدم الرسومية في الوقت الحقيقي :
python gui_diff.pyملاحظة: تحتاج إلى تحميل نموذج الإصدار 4.0 على الجانب الأيمن من واجهة المستخدم الرسومية
إن تثبيت التبعيات ، وإعداد البيانات ، وتكوين التشفير المدربين مسبقًا (Hubert أو ContentVec) ، ومستخرج الملعب (RMVPE) و Vocoder (NSF-hifigan) هو نفس تدريب نموذج DDSP الخالص (انظر الفصل 1 ~ 3 أدناه).
نظرًا لأن نموذج الانتشار أكثر صعوبة في التدريب ، فإننا نقدم بعض النماذج المدربة مسبقًا هنا:
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trocrained-trained-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_pt (باستخدام "الترميز" هوبرتسوفت)
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trocrained-model/blob/main/fix_pitch_add_vctk_600k/model_pt (باستخدام "contentVec768L12" encoder)
انقل model_0.pt إلى مجلد تصدير النموذج المحدد بواسطة المعلمة "expdir" في diffusion.yaml ، وسيقوم البرنامج تلقائيًا بتحميل النماذج المدربة مسبقًا في هذا المجلد.
(1) المعالجة المسبقة :
python preprocess.py -c configs/diffusion.yamlيمكن أيضًا استخدام هذه المعالجة المسبقة لتدريب نموذج DDSP دون المعالجة المسبقة مرتين ، ولكن تحتاج إلى التأكد من أن المعلمات ضمن علامة "البيانات" في ملفات YAML متسقة.
(2) تدريب نموذج الانتشار :
python train_diff.py -c configs/diffusion.yaml(3) تدريب نموذج DDSP :
python train.py -c configs/combsub.yaml كما ذكر أعلاه ، فإن إعادة المعالجة غير مطلوبة ، ولكن يرجى التحقق مما إذا كانت معلمات combsub.yaml و diffusion.yaml تطابق. يمكن أن يكون عدد مكبرات الصوت "N_SPK" غير متسق ، ولكن حاول استخدام نفس المعرف لتمثيل نفس السماعة (هذا يجعل الاستدلال أسهل).
(4) الاستدلال غير الحقيقي :
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > "Speedup" هي سرعة التسارع ، "الطريقة" هي "DDIM" ، "PNDM" ، "DPM-Solver" أو "unipc" ، "KSTEP" هو عدد خطوات الاختلاف الضحلة ، "Diffid" هو معرف السماعة لنموذج الانتشار ، والمعلمات الأخرى لها نفس المعنى main.py .
"kstep" معقول حوالي 100 ~ 300. قد يكون هناك خسارة ملحوظة لجودة الصوت عندما تتجاوز "الإسراع" 20.
إذا تم استخدام المعرف نفسه لتمثيل نفس المتحدث أثناء التدريب ، فيمكن أن يكون-Diffid "فارغًا ، وإلا يجب تحديد خيار" diffid ".
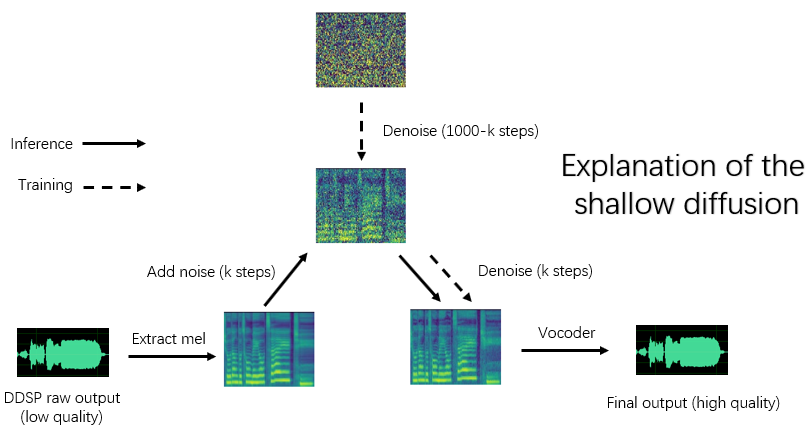
إذا كان "-DDSP" فارغًا ، فسيتم استخدام نموذج الانتشار النقي ، في هذا الوقت ، يتم إجراء الانتشار الضحل مع MEL لمصدر الإدخال ، وإذا كان أكثر "-kstep" فارغًا ، يتم إجراء الانتشار الغاوسي الكامل.
سيقوم البرنامج تلقائيًا بالتحقق مما إذا كانت معلمات نموذج DDSP ومطابقة نموذج الانتشار (معدل أخذ العينات ، وحجم القفز والتشفير) ، وإذا كانت غير متطابقة ، فسيتجاهل تحميل نموذج DDSP وإدخال وضع الانتشار Gaussian.
(5) واجهة المستخدم الرسومية في الوقت الحقيقي :
python gui_diff.pyDDSP-SVC هو مشروع جديد لتحويل الصوت مفتوح المصدر الغناء مخصص لتطوير برنامج مغير صوت AI المجاني الذي يمكن أن يتم تعميمه على أجهزة الكمبيوتر الشخصية.
بالمقارنة مع SO-SITS-SVC الشهيرة ، فإن التدريب والتوليف لها متطلبات أقل بكثير لأجهزة الكمبيوتر ، ويمكن تقصير وقت التدريب حسب أوامر الحجم ، والتي تقترب من سرعة التدريب في RVC.
بالإضافة إلى ذلك ، عند إجراء تغيير الصوت في الوقت الفعلي ، يكون استهلاك موارد الأجهزة لهذا المشروع أقل بكثير من الاستهلاك SO-SITS-SVC , ولكن ربما أعلى قليلاً من أحدث إصدار من RVC.
على الرغم من أن جودة التوليف الأصلية لـ DDSP ليست مثالية (يمكن سماع الناتج الأصلي في Tensorboard أثناء التدريب) ، أو بعد تعزيز جودة الصوت مع محسن مستند إلى Vocoder (الإصدار القديم) أو مع نموذج اختلاف ضحل (إصدار جديد) ، أو لبعض مجموعات البيانات ، يمكن أن يحقق جودة التوليف لا يقل عن Sovits-SVC و RVC.
لا تزال نماذج الإصدار القديمة متوافقة ، فالفصول التالية هي إرشادات الإصدار القديم. بعض عمليات الإصدار الجديد هي نفسها ، انظر الفصول السابقة.
إخلاء المسئولية: يرجى التأكد من تدريب نماذج DDSP-SVC فقط مع البيانات المعتمدة التي تم الحصول عليها قانونًا ، ولا تستخدم هذه النماذج وأي صوت يتجمعها لأغراض غير قانونية. مؤلف هذا المستودع ليس مسؤولاً عن أي انتهاك ، والاحتيال وغيرها من الأعمال غير القانونية الناجمة عن استخدام نقاط التفتيش هذه والصوت النموذجي.
سجل التحديث: أنا كسول جدًا للترجمة ، يرجى الاطلاع على الإصدار الصيني ReadMe.
نوصي أولاً بتثبيت Pytorch من الموقع الرسمي ، ثم تشغيل:
pip install -r requirements.txtملاحظة: أنا فقط أختبر الرمز باستخدام Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0 ، قد لا تعمل التبعيات الجديدة أو القديمة جدًا
تحديث: Python 3.8 (Windows) + CUDA 11.8 + Torch 2.0.0 + Torchaudio 2.0.1 أعمال ، والتدريب أسرع.
(1) قم بتنزيل برنامج تشفير ContentVec الذي تم تدريبه مسبقًا ووضعه تحت مجلد pretrain/contentvec .
(2) قم بتنزيل برنامج Hubertsoft Encoder الذي تم تدريبه مسبقًا ووضعه ضمن مجلد pretrain/hubert ، ثم قم بتعديل ملف التكوين في نفس الوقت.
قم بتنزيل وفك ضغط Vocoder NSF-Hifigan المدربين مسبقًا
أو استخدم مشروع https://github.com/openvpi/SingingVocoders لضبط المبركات للحصول على جودة صوت أعلى.
ثم أعد تسمية ملف نقطة التفتيش ووضعه في الموقع المحدد بواسطة معلمة "vocoder.ckpt" في ملف التكوين. القيمة الافتراضية هي pretrain/nsf_hifigan/model .
يجب أن يكون "config.json" من Vocoder في نفس الدليل ، على سبيل المثال ، pretrain/nsf_hifigan/config.json .
قم بتنزيل مستخرج RMVPE الذي تم تدريبه مسبقًا وفك ضغطه في pretrain/ المجلد.
ضع جميع مجموعة بيانات التدريب (.WAV Format Audio Clips) في الدليل أدناه: data/train/audio . ضع جميع مجموعة بيانات التحقق من الصحة ( data/val/audio يمكنك أيضا الجري
python draw.py لمساعدتك في تحديد بيانات التحقق من الصحة (يمكنك ضبط المعلمات في draw.py لتعديل عدد الملفات المستخرجة والمعلمات الأخرى)
ثم ركض
python preprocess.py -c configs/combsub.yamlبالنسبة لنموذج Combtooth Sunthesizer ( التوصية ) ، أو تشغيله
python preprocess.py -c configs/sins.yamlلنموذج من الجيوب الأنفية المضافة المضافة.
لتدريب نموذج الانتشار ، انظر القسم 3.0 أو 4.0 أو 5.0 أعلاه.
يمكنك تعديل تكوين ملف config/<model_name>.yaml قبل المعالجة المسبقة. التكوين الافتراضي مناسب لتدريب 44.1 كيلو هرتز ترتفع معدل أخذ العينات مع بطاقة رسومات GTX-1660.
ملاحظة 1: يرجى الاحتفاظ بمعدل أخذ العينات لجميع مقاطع الصوت بما يتوافق مع معدل أخذ العينات في ملف تكوين YAML! إذا لم يكن الأمر ثابتًا ، فيمكن تنفيذ البرنامج بأمان ، ولكن إعادة التشكيل أثناء عملية التدريب ستكون بطيئة للغاية.
ملاحظة 2: يوصى بتقليص عدد مقاطع بيانات الصوت الإجمالية لمجموعة بيانات التدريب حوالي 1000 ، وخاصة مقطع الصوت الطويل إلى شرائح قصيرة ، مما سيؤدي إلى تسريع التدريب ، ولكن لا ينبغي أن تكون مدة جميع مقاطع الصوت أقل من ثانيتين. إذا كان هناك الكثير من مقاطع الصوت ، فأنت بحاجة إلى ذاكرة داخلية كبيرة أو قم بتعيين خيار "cache_all_data" إلى خطأ في ملف التكوين.
الملاحظة 3: يوصى بعدد إجمالي مقاطع الصوت لمجموعة بيانات التحقق من الصحة إلى حوالي 10 ، يرجى عدم وضع الكثير أو سيكون بطيئًا للغاية في القيام بالتحقق من الصحة.
ملاحظة 4: إذا لم تكن مجموعة البيانات الخاصة بك عالية الجودة ، فقم بتعيين "F0_Extractor" على "RMVPE" في ملف التكوين.
الملاحظة 5: تم دعم التدريب متعدد الحواف الآن. تتعلق المعلمة "N_SPK" في Configuration File Controlly ما إذا كان نموذجًا متعدد النطاقات. إذا كنت ترغب في تدريب طراز متعدد المتحدثين ، فيجب تسمية مجلدات الصوت مع الأعداد الصحيحة الإيجابية التي لا تزيد عن "N_SPK" لتمثيل معرفات السماعة ، فإن بنية الدليل كما هو:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...إذا كانت "n_spk" = 1 ، فإن بنية الدليل لنموذج السماعات الفردية لا تزال مدعومة ، وهو ما يلي:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yamlخط الأوامر لتدريب النماذج الأخرى مشابه.
يمكنك مقاطعة التدريب بأمان ، ثم تشغيل سطر الأوامر نفسه سيستأنف التدريب.
يمكنك أيضًا FinEtune النموذج إذا قمت بتقاطع التدريب أولاً ، ثم إعادة معالجة مجموعة البيانات الجديدة أو تغيير معلمات التدريب (BatchSize ، LR إلخ) ثم تشغيل سطر الأوامر نفسه.
# check the training status using tensorboard
tensorboard --logdir=expستكون عينات الصوت مرئية في Tensorboard بعد التحقق الأول.
ملاحظة: إن عينات الصوت الاختبار في Tensorboard هي المخرجات الأصلية لنموذج DDSP-SVC الخاص بك والتي لا يتم تعزيزها بواسطة محسن. إذا كنت ترغب في اختبار التأثير الاصطناعي بعد استخدام المحسن (الذي قد يكون له جودة أعلى) ، فيرجى استخدام الطريقة الموضحة في الفصل التالي.
( نوصي ) تعزيز الإخراج باستخدام المحسن المستند إلى Vocoder المسبق:
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >الإخراج الخام من DDSP:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseخيارات أخرى حول مستخرج F0 والاستجابة threhold , انظر:
python main.py -h(تحديث) يتم دعم Mix-Speaker الآن. يمكنك استخدام خيار "-mix" لتصميم timbre الصوتية الخاصة بك ، أدناه مثال:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0ابدأ واجهة المستخدم الرسومية البسيطة مع الأمر التالي:
python gui.pyيستخدم الواجهة الأمامية تقنيات مثل النافذة المنزلق ، والمرجع المتقاطع ، والمرجع الدلالي القائم على SOLA ، والمرجع الدلالي السياقي ، والذي يمكن أن يحقق جودة الصوت بالقرب من التوليف غير الحقيقي مع انخفاض الكمون والموارد.
تحديث: تتم الآن إضافة خوارزمية الربط المستندة إلى مرحلة المتفرجية ، ولكن في معظم الحالات ، تتمتع خوارزمية SOLA بالفعل بجودة صوت عالية بما يكفي ، لذلك يتم إيقاف تشغيلها افتراضيًا. إذا كنت تتابع جودة الصوت في الوقت الفعلي في الوقت الفعلي ، فيمكنك التفكير في تشغيله وضبط المعلمات بعناية ، وهناك احتمال أن تكون جودة الصوت أعلى. ومع ذلك ، فقد وجد عددًا كبيرًا من الاختبارات أنه إذا كان الوقت المتقاطع أطول من 0.1 ثانية ، فسوف يتسبب Vocoder في تحلل كبير في جودة الصوت.
DDSP
PC-DDSP
Soft-VC
ContentVec
Diffsinger (إصدار OpenVPI)
Diff-SVC
الانتشار SVC


