DDSP SVC
ved DDSP Cascade Diffusion Model
Bahasa: Bahasa Inggris简体中文 한국어( usang)
(1) preprocessing :
python preprocess.py -c configs/reflow.yaml(2) Pelatihan :
python train_reflow.py -c configs/reflow.yaml(3) Inferensi non-real-time :
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > 'infer_step' adalah jumlah langkah pengambilan sampel untuk ode aliran yang diperbaiki, 'metode' adalah 'euler' atau 'rk4', 't_start' adalah titik waktu mulai ode, yang perlu lebih besar dari atau sama dengan t_start dalam file konfigurasi, disarankan untuk tetap sama (default adalah 0,7)
Menginstal dependensi, persiapan data, mengkonfigurasi encoder pra-terlatih (Hubert atau ContentVec), pitch extractor (RMVPE) dan Vocoder (NSF-Hifigan) sama dengan melatih model DDSP murni (lihat bagian di bawah).
Kami menyediakan model pra-terlatih di halaman rilis.
Pindahkan model_0.pt ke folder ekspor model yang ditentukan oleh parameter 'expdir' di diffusion-fast.yaml , dan program akan secara otomatis memuat model pra-terlatih di folder itu.
(1) preprocessing :
python preprocess.py -c configs/diffusion-fast.yaml(2) Latih model kaskade (hanya melatih satu model) :
python train_diff.py -c configs/diffusion-fast.yaml(3) Inferensi non-real-time :
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > Model versi 5.0 memiliki model DDSP bawaan, jadi menentukan model DDSP eksternal menggunakan -ddsp tidak perlu. Opsi lain memiliki arti yang sama dengan model versi 3.0, tetapi 'kstep' harus kurang dari atau sama dengan k_step_max dalam file konfigurasi, disarankan agar tetap sama (standarnya adalah 100)
(4) GUI real-time :
python gui_diff.pyCatatan: Anda perlu memuat model versi 5.0 di sisi kanan GUI
Menginstal dependensi, persiapan data, mengkonfigurasi encoder pra-terlatih (Hubert atau ContentVec), pitch extractor (RMVPE) dan Vocoder (NSF-Hifigan) sama dengan melatih model DDSP murni (lihat bagian di bawah).
Kami menyediakan model pra-terlatih di sini: https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/pre-trained-model/model_0.pt (menggunakan 'contentVec768l12' encoder))
Pindahkan model_0.pt ke folder ekspor model yang ditentukan oleh parameter 'expdir' di diffusion-new.yaml , dan program akan secara otomatis memuat model pra-terlatih di folder itu.
(1) preprocessing :
python preprocess.py -c configs/diffusion-new.yaml(2) Latih model kaskade (hanya melatih satu model) :
python train_diff.py -c configs/diffusion-new.yamlCatatan: Ada masalah sementara dengan pelatihan FP16, tetapi FP32 dan BF16 bekerja secara normal,
(3) Inferensi non-real-time :
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > Model versi 4.0 memiliki model DDSP bawaan, jadi menentukan model DDSP eksternal menggunakan -ddsp tidak perlu. Opsi lain memiliki arti yang sama dengan model versi 3.0, tetapi 'kstep' harus kurang dari atau sama dengan k_step_max dalam file konfigurasi, disarankan agar tetap sama (standarnya adalah 100)
(4) GUI real-time :
python gui_diff.pyCatatan: Anda perlu memuat model versi 4.0 di sisi kanan GUI
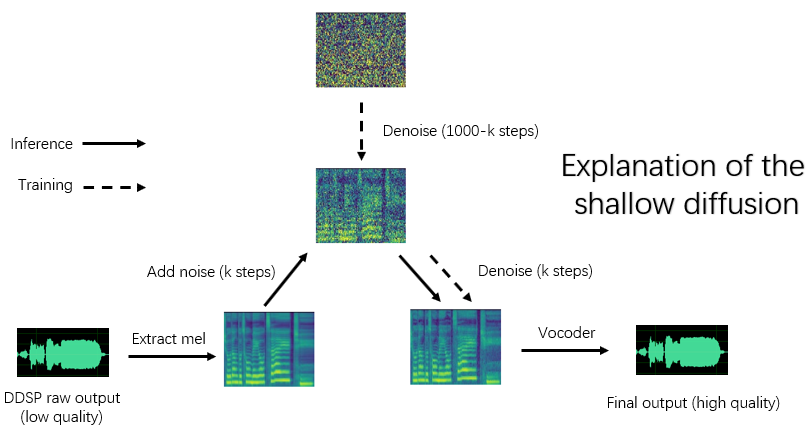
Menginstal dependensi, persiapan data, mengkonfigurasi encoder pra-terlatih (Hubert atau ContentVec), pitch extractor (RMVPE) dan Vocoder (NSF-Hifigan) sama dengan melatih model DDSP murni (lihat Bab 1 ~ 3 di bawah).
Karena model difusi lebih sulit untuk dilatih, kami menyediakan beberapa model pra-terlatih di sini:
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt (menggunakan 'hubertsoft' encoder))
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/fix_pitch_add_vctk_600k/model_0.pt (menggunakan 'contentvec768l12' encoder)
Pindahkan model_0.pt ke folder ekspor model yang ditentukan oleh parameter 'expdir' dalam diffusion.yaml , dan program akan secara otomatis memuat model pra-terlatih di folder itu.
(1) preprocessing :
python preprocess.py -c configs/diffusion.yamlPreprocessing ini juga dapat digunakan untuk melatih model DDSP tanpa preprocessing dua kali, tetapi Anda perlu memastikan bahwa parameter di bawah tag 'Data' dalam file YAML konsisten.
(2) Latih model difusi :
python train_diff.py -c configs/diffusion.yaml(3) Latih model DDSP :
python train.py -c configs/combsub.yaml Seperti yang disebutkan di atas, preprocessing ulang tidak diperlukan, tetapi silakan periksa apakah parameter combsub.yaml dan diffusion.yaml cocok. Jumlah speaker 'N_SPK' bisa tidak konsisten, tetapi cobalah untuk menggunakan ID yang sama untuk mewakili pembicara yang sama (ini membuat inferensi lebih mudah).
(4) Inferensi non-real-time :
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 'Speedup' adalah kecepatan akselerasi, 'metode' adalah 'ddim', 'pndm', 'dpm-solver' atau 'unipc', 'kStep' adalah jumlah langkah difusi dangkal, 'diffid' adalah ID pembicara dari model difusi, dan parameter lain memiliki arti yang sama dengan main.py
'KSTEP' yang masuk akal adalah sekitar 100 ~ 300. Mungkin ada kehilangan kualitas suara yang dirasakan ketika 'speedup' melebihi 20.
Jika ID yang sama telah digunakan untuk mewakili pembicara yang sama selama pelatihan, '-diffid' dapat kosong, jika tidak, opsi '-diffid' perlu ditentukan.
Jika '-ddsp' kosong, model difusi murni digunakan, pada saat ini, difusi dangkal dilakukan dengan MEL dari sumber input, dan jika lebih lanjut '-kstep' kosong, difusi Gaussian yang sangat dalam dilakukan.
Program akan secara otomatis memeriksa apakah parameter model DDSP dan kecocokan model difusi (laju pengambilan sampel, ukuran hop dan encoder), dan jika tidak cocok, itu akan mengabaikan memuat model DDSP dan memasuki mode difusi Gaussian.
(5) GUI real-time :
python gui_diff.pyDDSP-SVC adalah proyek konversi suara menyanyi open source baru yang didedikasikan untuk pengembangan perangkat lunak pengubah suara AI gratis yang dapat dipopulerkan di komputer pribadi.
Dibandingkan dengan So-Vits-SVC yang terkenal, pelatihan dan sintesisnya memiliki persyaratan yang jauh lebih rendah untuk perangkat keras komputer, dan waktu pelatihan dapat dipersingkat dengan pesanan besarnya, yang dekat dengan kecepatan pelatihan RVC.
Selain itu, ketika melakukan perubahan suara real-time, konsumsi sumber daya perangkat keras dari proyek ini secara signifikan lebih rendah daripada So-Vits-SVC, tetapi mungkin sedikit lebih tinggi dari versi RVC terbaru.
Meskipun kualitas sintesis asli DDSP tidak ideal (output asli dapat didengar di Tensorboard saat pelatihan), setelah meningkatkan kualitas suara dengan penambah berbasis vocoder pra-terlatih (versi lama) atau dengan model difusi dangkal (versi baru), untuk beberapa dataset, ia dapat mencapai kualitas sintesis yang tidak lebih dari Sovit-SVC dan RVC.
Model versi lama masih kompatibel, bab -bab berikut adalah instruksi untuk versi lama. Beberapa operasi versi baru sama, lihat bab -bab sebelumnya.
Penafian: Pastikan hanya melatih model DDSP-SVC dengan data resmi yang diperoleh secara hukum , dan jangan menggunakan model ini dan audio apa pun yang mereka sintesis untuk tujuan ilegal. Penulis repositori ini tidak bertanggung jawab atas pelanggaran, penipuan dan tindakan ilegal lainnya yang disebabkan oleh penggunaan pos pemeriksaan dan audio model ini.
Perbarui Log: Saya terlalu malas untuk diterjemahkan, silakan lihat ReadMe versi Cina.
Kami merekomendasikan terlebih dahulu menginstal Pytorch dari situs web resmi, lalu jalankan:
pip install -r requirements.txtCatatan: Saya hanya menguji kode menggunakan Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0, terlalu baru atau terlalu lama dependensi mungkin tidak berfungsi
UPDATE: Python 3.8 (Windows) + CUDA 11.8 + Torch 2.0.0 + Torchaudio 2.0.1 Pekerjaan, dan pelatihan lebih cepat.
(1) Unduh Encoder ContentVec Pra-Terlatih dan letakkan di bawah folder pretrain/contentvec .
(2) Unduh Hubertsoft Encoder yang sudah terlatih dan letakkan di bawah folder pretrain/hubert , dan kemudian modifikasi file konfigurasi secara bersamaan.
Unduh dan unzip Vocoder NSF-Hifigan yang sudah terlatih
Atau gunakan proyek https://github.com/openvpi/singvocoders untuk menyempurnakan vokoder untuk kualitas suara yang lebih tinggi.
Kemudian ganti nama file pos pemeriksaan dan letakkan di lokasi yang ditentukan oleh parameter 'Vocoder.ckpt' di file konfigurasi. Nilai defaultnya adalah pretrain/nsf_hifigan/model .
'Config.json' dari vocoder harus berada di direktori yang sama, misalnya, pretrain/nsf_hifigan/config.json .
Unduh ekstraktor RMVPE pra-terlatih dan unzip ke pretrain/ folder.
Letakkan semua dataset pelatihan (.WAV Format Klip Audio) di direktori di bawah ini: data/train/audio . Letakkan semua dataset validasi (.WAV Format Klip Audio) di direktori di bawah ini: data/val/audio . Anda juga bisa berlari
python draw.py Untuk membantu Anda memilih data validasi (Anda dapat menyesuaikan parameter dalam draw.py untuk memodifikasi jumlah file yang diekstraksi dan parameter lainnya)
Lalu jalankan
python preprocess.py -c configs/combsub.yamlUntuk model combtooth subtraktif synthesizer ( rekomendasi ), atau jalankan
python preprocess.py -c configs/sins.yamlUntuk model synthesizer aditif sinusoid.
Untuk melatih model difusi, lihat Bagian 3.0, 4.0 atau 5.0 di atas.
Anda dapat memodifikasi konfigurasi config/<model_name>.yaml sebelum preprocessing. Konfigurasi default cocok untuk pelatihan sintesizer laju pengambilan sampel tinggi 44.1kHz dengan kartu grafis GTX-1660.
Catatan 1: Harap simpan laju pengambilan sampel dari semua klip audio yang konsisten dengan laju pengambilan sampel dalam file konfigurasi YAML! Jika tidak konsisten, program dapat dieksekusi dengan aman, tetapi resampling selama proses pelatihan akan sangat lambat.
Catatan 2: Jumlah total klip audio untuk dataset pelatihan disarankan sekitar 1000, terutama klip audio yang panjang dapat dipotong menjadi segmen pendek, yang akan mempercepat pelatihan, tetapi durasi semua klip audio tidak boleh kurang dari 2 detik. Jika ada terlalu banyak klip audio, Anda memerlukan opsi internal-memori internal yang besar atau atur opsi 'CACHE_ALL_DATA' untuk false dalam file konfigurasi.
Catatan 3: Jumlah total klip audio untuk dataset validasi disarankan sekitar 10, tolong jangan terlalu banyak atau akan sangat lambat untuk melakukan validasi.
Catatan 4: Jika dataset Anda tidak berkualitas tinggi, atur 'f0_extractor' ke 'rmvpe' di file konfigurasi.
Catatan 5: Pelatihan multi-speaker didukung sekarang. Parameter 'n_spk' dalam file konfigurasi mengontrol apakah itu model multi-speaker. Jika Anda ingin melatih model multi-speaker , folder audio perlu dinamai dengan bilangan bulat positif yang tidak lebih besar dari 'n_spk' untuk mewakili ID speaker, struktur direktori seperti di bawah ini:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...Jika 'n_spk' = 1, struktur direktori model speaker tunggal masih didukung, yang seperti di bawah ini:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yamlBaris perintah untuk melatih model lain serupa.
Anda dapat dengan aman mengganggu pelatihan, kemudian menjalankan baris perintah yang sama akan melanjutkan pelatihan.
Anda juga dapat melakukan finetune model jika Anda mengganggu pelatihan terlebih dahulu, kemudian preproksi kembali dataset baru atau ubah parameter pelatihan (BatchSize, LR dll.) Dan kemudian jalankan baris perintah yang sama.
# check the training status using tensorboard
tensorboard --logdir=expSampel Audio Uji akan terlihat di Tensorboard setelah validasi pertama.
CATATAN: Sampel audio uji di Tensorboard adalah output asli dari model DDSP-SVC Anda yang tidak ditingkatkan oleh penambah. Jika Anda ingin menguji efek sintetis setelah menggunakan penambah (yang mungkin memiliki kualitas lebih tinggi), silakan gunakan metode yang dijelaskan dalam bab berikut.
( Rekomendasikan ) Tingkatkan output menggunakan penambah berbasis vocoder pretrained:
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >Output mentah DDSP:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseOpsi lain tentang ekstraktor f0 dan respons threhold, lihat:
python main.py -h(UPDATE) Mix-speaker didukung sekarang. Anda dapat menggunakan opsi "-Mix" untuk merancang timbre vokal Anda sendiri, di bawah ini adalah contoh:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0Mulailah GUI sederhana dengan perintah berikut:
python gui.pyFront-end menggunakan teknologi seperti jendela geser, cross fading, splicing berbasis sola dan referensi semantik kontekstual, yang dapat mencapai kualitas suara yang dekat dengan sintesis non-real-time dengan latensi rendah dan pekerjaan sumber daya.
Pembaruan: Algoritma splicing berdasarkan fase vocoder sekarang ditambahkan, tetapi dalam kebanyakan kasus algoritma Sola sudah memiliki kualitas suara splicing yang cukup tinggi, sehingga dimatikan secara default. Jika Anda mengejar kualitas suara real-time latensi rendah yang ekstrem, Anda dapat mempertimbangkan untuk menyalakannya dan menyetel parameter dengan hati-hati, dan ada kemungkinan bahwa kualitas suara akan lebih tinggi. Namun, sejumlah besar tes telah menemukan bahwa jika waktu silang lebih panjang dari 0,1 detik, vokoder fase akan menyebabkan degradasi yang signifikan dalam kualitas suara.
DDSP
PC-DDSP
Soft-VC
ContentVec
Diffsinger (versi OpenVPI)
Diff-svc
Difusi-SVC


