DDSP SVC
ved DDSP Cascade Diffusion Model
Sprache: Englisch简体中文 한국어( veraltet)
(1) Vorverarbeitung:
python preprocess.py -c configs/reflow.yaml(2) Training:
python train_reflow.py -c configs/reflow.yaml(3) Nicht-Real-Zeit-Inferenz:
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > 'infer_step' ist die Anzahl der Stichprobenschritte für die korrigierte Flow-Ode, 'Methode' ist 'Euler' oder 'RK4', 'T_Start' der Startzeitpunkt der ODE, der größer oder gleich t_start in der Konfigurationsdatei sein muss, um es gleich oder gleich zu halten (Standard) (Standard) oder 0,7).
Die Installation von Abhängigkeiten, Datenvorbereitung, Konfiguration des vorgeborenen Encoders (Hubert oder ContentVEC), Pitch-Extraktor (RMVPE) und Vocoder (NSF-Hifigan) sind das gleiche wie das Training eines reinen DDSP-Modells (siehe Abschnitt unten).
Wir bieten ein vorgebildetes Modell auf der Release-Seite.
Verschieben Sie das model_0.pt in den Modell Exportordner "Expdir" in diffusion-fast.yaml , und das Programm lädt das vorgebildete Modell automatisch in diesem Ordner.
(1) Vorverarbeitung:
python preprocess.py -c configs/diffusion-fast.yaml(2) trainieren Sie ein Kaskadenmodell (nur ein Modell trainieren):
python train_diff.py -c configs/diffusion-fast.yaml(3) Nicht-Real-Zeit-Inferenz:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > Das 5.0 -Versionsmodell verfügt über ein integriertes DDSP -Modell. Daher ist es unnötig, ein externes DDSP -Modell mit -ddsp anzugeben. Die anderen Optionen haben die gleiche Bedeutung wie das 3.0 -Versionsmodell, aber 'Kstep' muss in der Konfigurationsdatei weniger oder gleich k_step_max sein. Es wird empfohlen, es gleich zu halten (die Standardeinstellung beträgt 100).
(4) Echtzeit-GUI:
python gui_diff.pyHinweis: Sie müssen das Modell der Version 5.0 auf der rechten Seite der GUI laden
Die Installation von Abhängigkeiten, Datenvorbereitung, Konfiguration des vorgeborenen Encoders (Hubert oder ContentVEC), Pitch-Extraktor (RMVPE) und Vocoder (NSF-Hifigan) sind das gleiche wie das Training eines reinen DDSP-Modells (siehe Abschnitt unten).
Wir bieten hier ein vorgebildetes Modell: https://huggingface.co/datasets/ms903/ddsp--Svc-4.0/resolve/main/pre-trained-model/model_0.pt (mithilfe von 'contentVec768l12' ccoder))
Verschieben Sie das model_0.pt in den Modell Exportordner "Expdir" in diffusion-new.yaml , und das Programm lädt das vorgebildete Modell automatisch in diesem Ordner.
(1) Vorverarbeitung:
python preprocess.py -c configs/diffusion-new.yaml(2) trainieren Sie ein Kaskadenmodell (nur ein Modell trainieren):
python train_diff.py -c configs/diffusion-new.yamlHinweis: Es gibt ein vorübergehendes Problem mit dem FP16 -Training, aber FP32 und BF16 funktionieren normal.
(3) Nicht-Real-Zeit-Inferenz:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > Das 4.0 -Versionsmodell verfügt über ein integriertes DDSP -Modell. Daher ist es unnötig, ein externes DDSP -Modell mit -ddsp anzugeben. Die anderen Optionen haben die gleiche Bedeutung wie das 3.0 -Versionsmodell, aber 'Kstep' muss in der Konfigurationsdatei weniger oder gleich k_step_max sein. Es wird empfohlen, es gleich zu halten (die Standardeinstellung beträgt 100).
(4) Echtzeit-GUI:
python gui_diff.pyHinweis: Sie müssen das Modell der Version 4.0 auf der rechten Seite der GUI laden
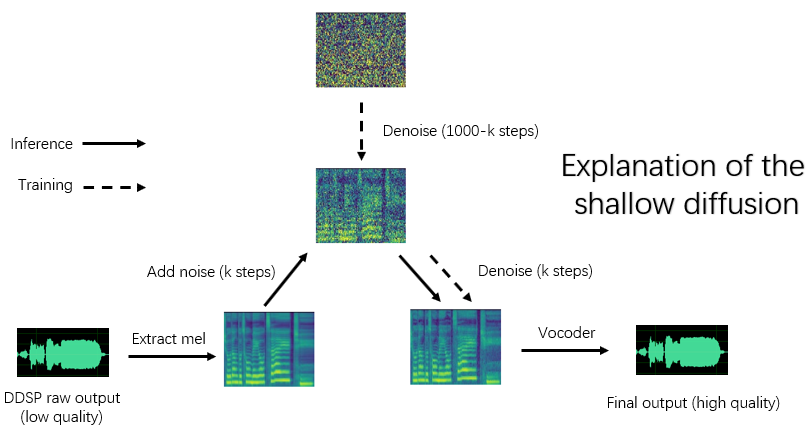
Die Installation von Abhängigkeiten, Datenvorbereitung, Konfiguration des vorgeborenen Encoders (Hubert oder ContentVEC), Pitch-Extraktor (RMVPE) und Vocoder (NSF-Hifigan) sind das gleiche wie das Training eines reinen DDSP-Modells (siehe Kapitel 1 ~ 3 unten).
Da das Diffusionsmodell schwieriger zu trainieren ist, stellen wir hier einige vorgebrachte Modelle an:
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt (mit 'Hubertsoft' Encoder 'Encoder))
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/fix_pitch_add_vctk_600k/model_0.pt (mit 'contentVec768l12' ccoder))
Verschieben Sie den model_0.pt in den Modell Exportordner "Expdir" in diffusion.yaml , und lädt das Programm automatisch die vorgebauten Modelle in diesem Ordner.
(1) Vorverarbeitung:
python preprocess.py -c configs/diffusion.yamlDiese Vorverarbeitung kann auch verwendet werden, um das DDSP -Modell zweimal ohne Vorverarbeitung zu trainieren. Sie müssen jedoch sicherstellen, dass die Parameter unter dem Tag "Daten" in YAML -Dateien konsistent sind.
(2) trainieren Sie ein Diffusionsmodell:
python train_diff.py -c configs/diffusion.yaml(3) trainieren Sie ein DDSP -Modell:
python train.py -c configs/combsub.yaml Wie oben erwähnt, ist keine Neubearbeitung erforderlich, aber prüfen Sie, ob die Parameter von combsub.yaml und diffusion.yaml Match. Die Anzahl der Sprecher n_spk 'kann inkonsistent sein, aber versuchen Sie, dieselbe ID zu verwenden, um denselben Sprecher darzustellen (dies erleichtert die Inferenz).
(4) Nicht-Real-Zeit-Inferenz:
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > "Beschleunigung" ist die Beschleunigungsgeschwindigkeit, "Methode" ist "ddim", "pndm", "dpm-solver" oder "unipc", "kstep" ist die Anzahl der flachen Diffusionsschritte, "diffid" ist die Sprecher-ID des Diffusionsmodells, und andere Parameter haben die gleiche Bedeutung wie main.py .
Ein vernünftiger 'Kstep' beträgt ca. 100 ~ 300. Es kann zu einem wahrgenommenen Verlust der Klangqualität kommen, wenn die Geschwindigkeit 20 über 20 liegt.
Wenn dieselbe ID zur Darstellung desselben Sprechers während des Trainings verwendet wurde, kann '-diffid' leer sein, andernfalls muss die Option "-diffid" angegeben werden.
Wenn '-ddsp' leer ist, wird das reine Diffusionsmodell verwendet, zu diesem Zeitpunkt wird die flache Diffusion mit dem Mel der Eingangsquelle durchgeführt, und wenn weiter '-kstep' leer ist, wird eine leere Gaußsche Diffusion mit voller Tiefe durchgeführt.
Das Programm wird automatisch prüfen, ob die Parameter des DDSP -Modells und des Diffusionsmodell -Matchs (Stichprobenrate, Hopfengröße und Encoder) und wenn sie nicht übereinstimmen, ignoriert es das Laden des DDSP -Modells und eingibt den Gaußschen Diffusionsmodus.
(5) Echtzeit-GUI:
python gui_diff.pyDDSP-SVC ist ein neues Open-Source-Sang-Sprach-Conversion-Projekt, das sich der Entwicklung einer kostenlosen AI-Sprachwechsler-Software widmet, die auf PCs populär gemacht werden kann.
Im Vergleich zu den berühmten SO-Vits-SVC haben seine Schulung und Synthese viel geringere Anforderungen an Computerhardware, und die Trainingszeit kann durch Größenordnungen verkürzt werden, was nahe an der Trainingsgeschwindigkeit von RVC liegt.
Bei der Durchführung von Echtzeit-Sprachwechseln ist der Hardware-Ressourcenverbrauch dieses Projekts erheblich niedriger als die von SO-Vits-SVC ,, aber wahrscheinlich etwas höher als die neueste Version von RVC.
Obwohl die ursprüngliche Synthesequalität von DDSP nicht ideal ist (die ursprüngliche Ausgabe ist im Tensorboard während des Trainings zu hören), nach der Verbesserung der Klangqualität mit einem vorgebildeten Vocoder-basierten Enhancer (alte Version) oder mit einem flachen Diffusionsmodell (neuer Version) für einige Datensätze können die Synthesequalität nicht weniger als SOVITS-SVC und RVC und RVC und RVC und RVC und RVC und RVC und RVC erreicht werden.
Die alten Versionsmodelle sind noch kompatibel, die folgenden Kapitel sind die Anweisungen für die alte Version. Einige Operationen der neuen Version sind gleich, siehe die vorherigen Kapitel.
Haftungsausschluss: Bitte schulen Sie nur DDSP-SVC-Modelle mit legal erhaltenen autorisierten Daten und verwenden Sie diese Modelle nicht und auch von Audio, die sie für illegale Zwecke synthetisieren. Der Autor dieses Repositorys ist nicht für Verstöße, Betrug und andere illegale Handlungen verantwortlich, die durch die Verwendung dieser Modell -Checkpoints und Audio verursacht werden.
Update -Protokoll: Ich bin zu faul, um sie zu übersetzen. Siehe die chinesische Version Readme.
Wir empfehlen zuerst, Pytorch von der offiziellen Website zu installieren, und dann ausführen:
pip install -r requirements.txtHinweis: Ich teste den Code nur mit Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0, zu neu oder zu alte Abhängigkeiten funktionieren möglicherweise nicht
Update: Python 3.8 (Windows) + CUDA 11.8 + Torch 2.0.0 + Torchaudio 2.0.1 funktioniert und das Training ist schneller.
(1) Laden Sie den vorgebildeten ContentVec-Encoder herunter und setzen Sie ihn unter den Ordner pretrain/contentvec .
pretrain/hubert
Laden Sie den vorgebildeten NSF-Hifigan-Vocoder herunter und öffnen Sie sie
Oder verwenden Sie das Projekt https://github.com/openvpi/singingvocoders, um den Vocoder für höhere Klangqualität zu beenden.
Benennen Sie dann die Checkpoint -Datei um und platzieren Sie sie am Parameter 'vocoder.ckpt' in der Konfigurationsdatei. Der Standardwert ist pretrain/nsf_hifigan/model .
Das 'config.json' des Vocoders muss sich im selben Verzeichnis befinden, z. B. pretrain/nsf_hifigan/config.json .
Laden Sie den vorgebildeten RMVPE-Extraktor herunter und entpacken Sie ihn in pretrain/ Ordner.
Setzen Sie den gesamten Trainingsdatensatz (.wav -Format -Audioclips) in das folgende Verzeichnis: data/train/audio . Stellen Sie alle Validierungsdatensatz (.wav -Format -Audioclips) in das folgende Verzeichnis: data/val/audio . Sie können auch rennen
python draw.py Um Validierungsdaten auszuwählen (Sie können die Parameter in draw.py anpassen, um die Anzahl der extrahierten Dateien und andere Parameter zu ändern).
Dann rennen
python preprocess.py -c configs/combsub.yamlFür ein Modell des substraktiven Combooth -Synthesizers ( Empfehlung ) oder ausführen
python preprocess.py -c configs/sins.yamlFür ein Modell von Sinusoiden Additive Synthesizer.
Für das Training des Diffusionsmodells siehe Abschnitt 3.0, 4.0 oder 5.0 oben.
Sie können die Konfigurationsdateikonfiguration config/<model_name>.yaml vor der Vorverarbeitung ändern. Die Standardkonfiguration eignet sich zum Training 44,1 kHz hohe Abtastrate-Synthesizer mit GTX-1660-Grafikkarte.
Hinweis 1: Bitte behalten Sie die Stichprobenrate aller Audioclips in Übereinstimmung mit der Stichprobenrate in der YAML -Konfigurationsdatei! Wenn es nicht konsistent ist, kann das Programm sicher ausgeführt werden, aber das Resampling während des Schulungsprozesses ist sehr langsam.
Anmerkung 2: Die Gesamtzahl der Audioclips für den Trainingsdatensatz wird empfohlen, etwa 1000 zu beträgt, insbesondere langen Audioclips können in kurze Segmente geschnitten werden, wodurch das Training beschleunigt wird. Die Dauer aller Audioclips sollte jedoch nicht weniger als 2 Sekunden betragen. Wenn es zu viele Audioclips gibt, benötigen Sie ein großes internes Memory oder setzen Sie in der Konfigurationsdatei die Option 'cache_all_data' auf Falsch.
Anmerkung 3: Die Gesamtzahl der Audioclips für den Validierungsdatensatz wird empfohlen, etwa 10 zu beträgt.
ANMERKUNG 4: Wenn Ihr Datensatz nicht sehr hoch ist, setzen Sie 'f0_extractor' in der Konfigurationsdatei auf 'rmvpe'.
Anmerkung 5: Multi-Sprecher-Training wird jetzt unterstützt. Der Parameter 'n_spk' in der Konfigurationsdatei steuert, ob es sich um ein Multi-Sprecher-Modell handelt. Wenn Sie ein Modell mit mehreren Lautsprechern trainieren möchten, müssen Audioordner mit positiven Ganzzahlen genannt werden, die nicht größer als 'n_spk' sind , um Sprecher-IDs darzustellen, ist die Verzeichnisstruktur nach unten:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...Wenn 'n_spk' = 1, wird die Verzeichnisstruktur des Einzellautsprechermodells weiter unterstützt, was wie unten ist:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yamlDie Befehlszeile für das Training anderer Modelle ist ähnlich.
Sie können das Training sicher unterbrechen und dann wird die gleiche Befehlszeile ausgeführt.
Sie können das Modell auch finanzunieren, wenn Sie das Training zuerst unterbrechen, dann den neuen Datensatz neu bearbeiten oder die Trainingsparameter (batchSize, LR usw.) ändern und dann dieselbe Befehlszeile ausführen.
# check the training status using tensorboard
tensorboard --logdir=expTest -Audio -Proben sind nach der ersten Validierung im Tensorboard sichtbar.
Hinweis: Die Test-Audio-Proben in Tensorboard sind die ursprünglichen Ausgaben Ihres DDSP-SVC-Modells, die nicht von einem Enhancer verbessert werden. Wenn Sie den synthetischen Effekt nach der Verwendung des Enhancers (die möglicherweise eine höhere Qualität aufweisen können) testen möchten, verwenden Sie bitte die im folgende Kapitel beschriebene Methode.
( Empfehlung ) Verbessern Sie den Ausgang mit dem vorgefertigten Vocoder-basierten Enhancer:
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >Rohausgabe von DDSP:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseAndere Optionen zum F0 -Extraktor und der Reaktion Threhold , siehe:
python main.py -h(Update) Mix-Sprecher wird jetzt unterstützt. Sie können die Option "-mix" verwenden, um Ihr eigenes Vokal-Timbre zu entwerfen. Unten finden Sie ein Beispiel:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0Starten Sie eine einfache GUI mit dem folgenden Befehl:
python gui.pyDas Front-End verwendet Technologien wie Schiebefenster, Kreuzverschlüsse, SOLA-basiertes Spleiß- und kontextbezogene semantische Referenz, die die Schallqualität in der Nähe der Nicht-Real-Zeit-Synthese mit geringer Latenz und Ressourcenbeschäftigung erreichen können.
UPDATE: Ein Spleißalgorithmus, das auf einem Phasenvokoder basiert, wird jetzt hinzugefügt. In den meisten Fällen hat der Sola -Algorithmus jedoch bereits eine hohe Spleißqualität, sodass er standardmäßig ausgeschaltet wird. Wenn Sie eine extreme Schallqualität mit geringer Latenz in Echtzeit verfolgen, können Sie in Betracht ziehen, die Parameter einzuschalten und sorgfältig abzustimmen, und es besteht die Möglichkeit, dass die Klangqualität höher ist. Eine große Anzahl von Tests hat jedoch festgestellt, dass der Phasen-Vokoder, wenn die Kreuzzeit länger als 0,1 Sekunden beträgt, einen signifikanten Abbau der Schallqualität verursacht.
DDSP
PC-DDSP
Soft-VC
ContentVec
Diffsinger (OpenVPI -Version)
Diff-SVC
Diffusions-SVC


