DDSP SVC
ved DDSP Cascade Diffusion Model
Idioma: Inglês简体中文 ((Desatualizado)
(1) pré -processamento:
python preprocess.py -c configs/reflow.yaml(2) Treinamento:
python train_reflow.py -c configs/reflow.yaml(3) Inferência não-real:
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > 'infer_step' é o número de etapas de amostragem para ode de fluxo retificado, 'método' é 'euler' ou 'rk4', 't_start' é o ponto de início da ODE, que precisa ser maior que igual ou igual a t_start no arquivo de configuração, é recomendado manter-o igual (o padrão é 0.7)
Instalando dependências, preparação de dados, configuração do codificador pré-treinado (Hubert ou ContentVec), extrator de afinação (RMVPE) e vocoder (NSF-Hifigan) são os mesmos que treinam um modelo Puro DDSP (consulte a seção abaixo).
Fornecemos um modelo pré-treinado na página de liberação.
Mova o model_0.pt para a pasta de exportação de modelo especificada pelo parâmetro 'Expdir' no diffusion-fast.yaml , e o programa carregará automaticamente o modelo pré-treinado nessa pasta.
(1) pré -processamento:
python preprocess.py -c configs/diffusion-fast.yaml(2) Treinar um modelo em cascata (apenas treinar um modelo):
python train_diff.py -c configs/diffusion-fast.yaml(3) Inferência não-real:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > O modelo de versão 5.0 possui um modelo DDSP interno, portanto, especificar um modelo DDSP externo usando -ddsp é desnecessário. As outras opções têm o mesmo significado que o modelo de versão 3.0, mas 'Kstep' precisa ser menor ou igual a k_step_max no arquivo de configuração, é recomendável mantê -lo igual (o padrão é 100)
(4) GUI em tempo real:
python gui_diff.pyNota: você precisa carregar o modelo da versão 5.0 no lado direito da GUI
Instalando dependências, preparação de dados, configuração do codificador pré-treinado (Hubert ou ContentVec), extrator de afinação (RMVPE) e vocoder (NSF-Hifigan) são os mesmos que treinam um modelo Puro DDSP (consulte a seção abaixo).
Fornecemos um modelo pré-treinado aqui: https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/pretrouve-model/model_0.pt (usando 'ContentVec768L12' codificador)
Mova o model_0.pt para a pasta de exportação de modelo especificada pelo parâmetro 'Expdir' no diffusion-new.yaml , e o programa carregará automaticamente o modelo pré-treinado nessa pasta.
(1) pré -processamento:
python preprocess.py -c configs/diffusion-new.yaml(2) Treinar um modelo em cascata (apenas treinar um modelo):
python train_diff.py -c configs/diffusion-new.yamlNota: Há um problema temporário com o treinamento FP16, mas FP32 e BF16 estão funcionando normalmente,
(3) Inferência não-real:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > O modelo de versão 4.0 possui um modelo DDSP interno, portanto, especificar um modelo DDSP externo usando -ddsp é desnecessário. As outras opções têm o mesmo significado que o modelo de versão 3.0, mas 'Kstep' precisa ser menor ou igual a k_step_max no arquivo de configuração, é recomendável mantê -lo igual (o padrão é 100)
(4) GUI em tempo real:
python gui_diff.pyNota: você precisa carregar o modelo da versão 4.0 no lado direito da GUI
Instalando dependências, preparação de dados, configuração do codificador pré-treinado (Hubert ou ContentVec), extrator de afinação (RMVPE) e vocoder (NSF-Hifigan) são os mesmos que treinam um modelo Puro DDSP (consulte o Capítulo 1 ~ 3 abaixo).
Como o modelo de difusão é mais difícil de treinar, fornecemos alguns modelos pré-treinados aqui:
https://huggingface.co/datasets/ms903/diff-svc-reactor-pre-triled-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt (usando 'Hubertsoft')
https://huggingface.co/datasets/ms903/diff-svc-reactor-pre-triled-model/blob/main/fix_pitch_add_vctk_600k/model_0.pt (usando 'ContentVec768l12' Encoder)
Mova o model_0.pt para a pasta de exportação de modelo especificada pelo parâmetro 'Expdir' na diffusion.yaml , e o programa carregará automaticamente os modelos pré-treinados nessa pasta.
(1) pré -processamento:
python preprocess.py -c configs/diffusion.yamlEsse pré -processamento também pode ser usado para treinar o modelo DDSP sem pré -processamento duas vezes, mas você precisa garantir que os parâmetros na tag 'dados' nos arquivos YAML sejam consistentes.
(2) Treinar um modelo de difusão:
python train_diff.py -c configs/diffusion.yaml(3) Treine um modelo DDSP:
python train.py -c configs/combsub.yaml Como mencionado acima, o reprocessamento não é necessário, mas verifique se os parâmetros de combsub.yaml e diffusion.yaml correspondem. O número de alto -falantes 'n_spk' pode ser inconsistente, mas tente usar o mesmo ID para representar o mesmo alto -falante (isso facilita a inferência).
(4) Inferência de tempo não real:
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 'Speedup' é a velocidade de aceleração, 'método' é 'ddim', 'pndm', 'dpm-solver' ou 'unipc', 'kstep' é o número de etapas de difusão superficiais, 'diffiD' é o ID do alto-falante do modelo de difusão e outros parâmetros têm o mesmo significado que main.py
Um 'kstep' razoável é de cerca de 100 ~ 300. Pode haver uma perda percebida da qualidade do som quando a 'aceleração' excede 20.
Se o mesmo ID tiver sido usado para representar o mesmo alto-falante durante o treinamento, '-diffid' poderá estar vazio, caso contrário, a opção '-diffid' precisará ser especificada.
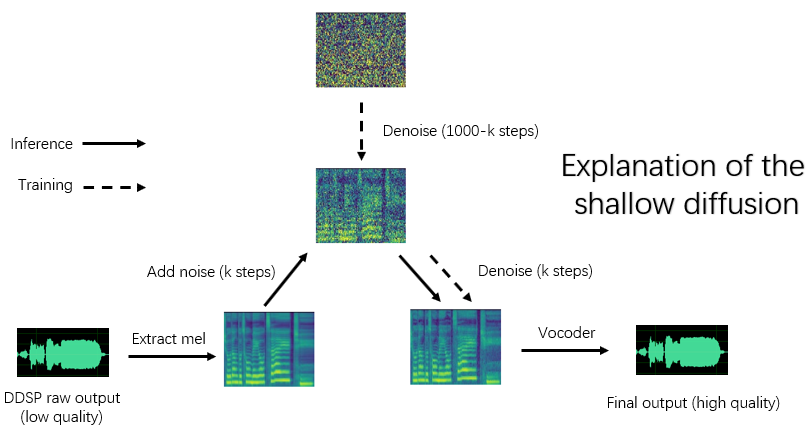
Se '-ddsp' estiver vazio, o modelo de difusão pura é usado, neste momento, a difusão rasa será realizada com o MEL da fonte de entrada e, se mais '-kstep' estiver vazia, a difusão gaussiana é realizada.
O programa verificará automaticamente se os parâmetros do modelo DDSP e o modelo de difusão correspondem (taxa de amostragem, tamanho do salto e codificador) e, se eles não corresponderem, ignorará o carregamento do modelo DDSP e entrará no modo de difusão gaussiano.
(5) GUI em tempo real:
python gui_diff.pyO DDSP-SVC é um novo projeto de conversão de voz de canto de código aberto dedicado ao desenvolvimento de um software gratuito de trocador de voz AI que pode ser popularizado em computadores pessoais.
Comparado com o famoso SO-Vits-SVC, seu treinamento e síntese têm requisitos muito mais baixos para o hardware do computador, e o tempo de treinamento pode ser reduzido por ordens de magnitude, que é próxima à velocidade de treinamento do RVC.
Além disso, ao executar a mudança de voz em tempo real, o consumo de recursos de hardware deste projeto é significativamente menor que o do SO-VITS-SVC, mas provavelmente um pouco mais alto que a versão mais recente do RVC.
Embora a qualidade da síntese original do DDSP não seja ideal (a saída original pode ser ouvida em tensorboard durante o treinamento), depois de melhorar a qualidade do som com um intensificador baseado em vocoder pré-treinado (versão antiga) ou com um modelo de difusão rasa (nova versão), para alguns conjuntos de dados, ele pode obter a qualidade da síntese não menos que Sovits-SVC e RVC.
Os modelos de versão antiga ainda são compatíveis, os capítulos a seguir são as instruções para a versão antiga. Algumas operações da nova versão são as mesmas, consulte os capítulos anteriores.
Isenção de responsabilidade: Certifique-se de treinar apenas modelos DDSP-SVC com dados autorizados obtidos legalmente e não use esses modelos e qualquer áudio que sintetize para fins ilegais. O autor deste repositório não é responsável por nenhuma infração, fraude e outros atos ilegais causados pelo uso desses pontos de verificação e áudio do modelo.
Log de atualização: Estou com preguiça de traduzir, consulte a versão chinesa ReadMe.
Recomendamos primeiro instalar o Pytorch no site oficial e depois executar:
pip install -r requirements.txtNota: Eu testei apenas o código usando o Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0, dependências novas ou muito antigas podem não funcionar
ATUALIZAÇÃO: Python 3.8 (Windows) + CUDA 11.8 + Torch 2.0.0 + Torchaudio 2.0.1 Obras, e o treinamento é mais rápido.
(1) Faça o download do codificador ContentVeC pré-treinado e coloque-o na pasta pretrain/contentvec .
(2) Faça o download do codificador Hubertsoft pré-treinado e coloque-o na pasta pretrain/hubert e modifique o arquivo de configuração ao mesmo tempo.
Download e descompacte o vocoder NSF-Hifigan pré-treinado
Ou use o projeto https://github.com/openvpi/singingvocoders para ajustar o vocoder para maior qualidade de som.
Em seguida, renomeie o arquivo do ponto de verificação e coloque -o no local especificado pelo parâmetro 'vocoder.ckpt' no arquivo de configuração. O valor padrão é pretrain/nsf_hifigan/model .
O 'config.json' do vocoder precisa estar no mesmo diretório, por exemplo, pretrain/nsf_hifigan/config.json .
Faça o download do extrator RMVPE pré-treinado e descompacte-o em pretrain/ pasta.
Coloque todo o conjunto de dados de treinamento (clipes de áudio do formato .wav) no diretório abaixo: data/train/audio . Coloque todo o conjunto de dados de validação (clipes de áudio do formato .wav) no diretório abaixo: data/val/audio . Você também pode correr
python draw.py Para ajudá -lo a selecionar dados de validação (você pode ajustar os parâmetros no draw.py para modificar o número de arquivos extraídos e outros parâmetros)
Em seguida, corra
python preprocess.py -c configs/combsub.yamlPara um modelo de sintetizador subestrinhas do Combtooth ( recomendar ) ou executar
python preprocess.py -c configs/sins.yamlPara um modelo de sintetizador aditivo sinusóides.
Para treinar o modelo de difusão, consulte a Seção 3.0, 4.0 ou 5.0 acima.
Você pode modificar o arquivo de configuração config/<model_name>.yaml antes do pré -processamento. A configuração padrão é adequada para o treinamento de 44.1kHz de alta taxa de amostragem sintetizador com a placa gráfica GTX-1660.
Nota 1: Por favor, mantenha a taxa de amostragem de todos os clipes de áudio consistentes com a taxa de amostragem no arquivo de configuração YAML! Se não for consistente, o programa poderá ser executado com segurança, mas a reamostragem durante o processo de treinamento será muito lenta.
NOTA 2: O número total de clipes de áudio para treinamento de treinamento é recomendado para cerca de 1000, especialmente o clipe de áudio longo pode ser cortado em segmentos curtos, o que acelerará o treinamento, mas a duração de todos os clipes de áudio não deve ser inferior a 2 segundos. Se houver muitos clipes de áudio, você precisará de uma grande memória interna ou definir a opção 'cache_all_data' como false no arquivo de configuração.
NOTA 3: O número total de clipes de áudio para o conjunto de dados de validação é recomendado como cerca de 10, por favor, não coloque muitos ou será muito lento para fazer a validação.
Nota 4: Se o seu conjunto de dados não for de alta qualidade, defina 'f0_extractor' como 'rmvpe' no arquivo de configuração.
Nota 5: O treinamento com vários alto-falantes é suportado agora. O parâmetro 'N_SPK' no arquivo de configuração controla se é um modelo multi-falante. Se você deseja treinar um modelo de vários falantes , as pastas de áudio precisam ser nomeadas com números inteiros positivos não maiores que 'n_spk' para representar IDs de alto-falante, a estrutura do diretório é como abaixo:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...Se 'n_spk' = 1, a estrutura de diretório do modelo de alto -falante ainda é suportada, como é abaixo:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yamlA linha de comando para treinar outros modelos é semelhante.
Você pode interromper com segurança o treinamento e executar a mesma linha de comando retomará o treinamento.
Você também pode definir o modelo se interromper primeiro o treinamento e depois pré-processar o novo conjunto de dados ou alterar os parâmetros de treinamento (BatchSize, LR etc.) e executar a mesma linha de comando.
# check the training status using tensorboard
tensorboard --logdir=expAs amostras de áudio de teste serão visíveis em Tensorboard após a primeira validação.
Nota: As amostras de áudio de teste no Tensorboard são as saídas originais do seu modelo DDSP-SVC que não é aprimorado por um intensificador. Se você deseja testar o efeito sintético após o uso do intensificador (que pode ter maior qualidade), use o método descrito no capítulo seguinte.
( Recomendar ) Aprimore a saída usando o intensificador de vocoder pré-treinado:
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >Saída bruta do DDSP:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseOutras opções sobre o extrator F0 e a resposta Threhold , Veja:
python main.py -h(Atualização) O Mix-Speaker é suportado agora. Você pode usar a opção "-mix" para projetar seu próprio timbre vocal, abaixo está um exemplo:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0Inicie uma GUI simples com o seguinte comando:
python gui.pyO front-end utiliza tecnologias como janela deslizante, splicing de desbotamento, baseado em sola e referência semântica contextual, que podem obter a qualidade do som próximo à síntese de tempo não real com baixa latência e ocupação de recursos.
ATUALIZAÇÃO: Um algoritmo de emenda baseado em um vocoder de fase agora é adicionado, mas na maioria dos casos o algoritmo sola já possui alta qualidade de som de emenda o suficiente, por isso é desligado por padrão. Se você estiver buscando a qualidade de som em tempo real de baixa latência extrema, considere ativá-lo e ajustar os parâmetros com cuidado, e existe a possibilidade de a qualidade do som ser maior. No entanto, um grande número de testes constatou que, se o tempo cruzado for superior a 0,1 segundos, o vocoder de fase causará uma degradação significativa na qualidade do som.
DDSP
PC-DDSP
Soft-VC
Contentvec
DiffSinger (versão OpenVPI)
Diff-svc
Difusão-SVC


