DDSP SVC
ved DDSP Cascade Diffusion Model
Язык: английский简体中文 한국어 (устаревший)
(1) Предварительная обработка:
python preprocess.py -c configs/reflow.yaml(2) Обучение:
python train_reflow.py -c configs/reflow.yaml(3) Нереально-временное вывод:
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > 'infer_step'-это количество шагов выборки для выпрямленной оды, «метод»-это «euler» или «rk4», «t_start»-это момент времени начала ODE, который должен быть больше или равным t_start в файле конфигурации, рекомендуется сохранить его равным (по умолчанию 0,7).
Установка зависимостей, подготовка данных, настройка предварительно обученного энкодера (Hubert или ContentVec), экстрактора высоты (RMVPE) и Vocoder (NSF-Hifigan)-это то же самое, что обучение чистой модели DDSP (см. Раздел ниже).
Мы предоставляем предварительно обученную модель на странице выпуска.
Переместите model_0.pt в папку экспорта модели, указанную параметром «expdir» в diffusion-fast.yaml , и программа автоматически загрузит предварительно обученную модель в этой папке.
(1) Предварительная обработка:
python preprocess.py -c configs/diffusion-fast.yaml(2) Тренировать каскадную модель (только одну модель) :
python train_diff.py -c configs/diffusion-fast.yaml(3) Нереально-временное вывод:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > Модель версии 5.0 имеет встроенную модель DDSP, поэтому указание внешней модели DDSP с использованием -ddsp не нужна. Другие параметры имеют то же значение, что и модель версии 3.0, но «KSTEP» должен быть меньше или равным k_step_max в файле конфигурации, рекомендуется сохранить его равным (по умолчанию 100)
(4) Gui в реальном времени :
python gui_diff.pyПримечание: вам нужно загрузить модель версии 5.0 в правой части графического интерфейса
Установка зависимостей, подготовка данных, настройка предварительно обученного энкодера (Hubert или ContentVec), экстрактора высоты (RMVPE) и Vocoder (NSF-Hifigan)-это то же самое, что обучение чистой модели DDSP (см. Раздел ниже).
Мы предоставляем предварительно обученную модель здесь: https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/pre-trained-model/model_0.pt (с использованием «contentVec768l12 'encoder)
Переместите model_0.pt в папку экспорта модели, указанную параметром «expdir» в diffusion-new.yaml , и программа автоматически загрузит предварительно обученную модель в этой папке.
(1) Предварительная обработка:
python preprocess.py -c configs/diffusion-new.yaml(2) Тренировать каскадную модель (только одну модель) :
python train_diff.py -c configs/diffusion-new.yamlПримечание: существует временная проблема с обучением FP16, но FP32 и BF16 работают нормально,
(3) Нереально-временное вывод:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > Модель версии 4.0 имеет встроенную модель DDSP, поэтому указание внешней модели DDSP с использованием -ddsp не нужна. Другие параметры имеют то же значение, что и модель версии 3.0, но «KSTEP» должен быть меньше или равным k_step_max в файле конфигурации, рекомендуется сохранить его равным (по умолчанию 100)
(4) Gui в реальном времени :
python gui_diff.pyПримечание: вам нужно загрузить модель версии 4.0 в правой части графического интерфейса
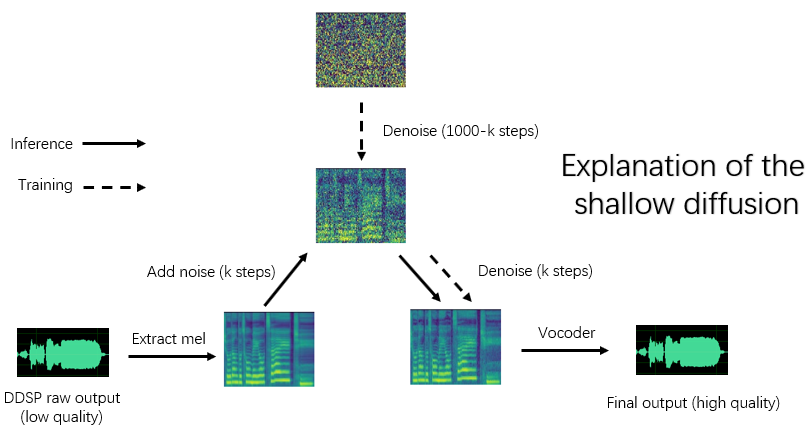
Установка зависимостей, подготовка данных, настройка предварительно обученного энкодера (Hubert или ContentVec), экстрактора высоты (RMVPE) и Vocoder (NSF-Hifigan)-это то же самое, что обучение чистой модели DDSP (см. Главу 1 ~ 3 ниже).
Поскольку диффузионную модель труднее тренироваться, мы предоставляем здесь несколько предварительно обученных моделей:
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre trained-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt (используя hubertsoft 'encoder)
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-triend-model/blob/main/fix_pitch_add_vctk_600k/model_0.pt (с использованием 'contentVec768l12' encoder)
Переместите model_0.pt в папку экспорта модели, указанную параметром «expdir» в diffusion.yaml , и программа автоматически загрузит предварительно обученные модели в этой папке.
(1) Предварительная обработка:
python preprocess.py -c configs/diffusion.yamlЭта предварительная обработка также может использоваться для обучения модели DDSP без предварительной обработки дважды, но вам необходимо убедиться, что параметры в рамках тега «Data» в файлах YAML были последовательны.
(2) Обучить диффузионную модель:
python train_diff.py -c configs/diffusion.yaml(3) Обучить модель DDSP:
python train.py -c configs/combsub.yaml Как упомянуто выше, повторная обработка не требуется, но, пожалуйста, проверьте, являются ли параметры combsub.yaml и diffusion.yaml match. Количество динамиков 'n_spk' может быть непоследовательным, но попытаться использовать тот же идентификатор, чтобы представлять один и тот же динамик (это облегчает вывод).
(4) Нереально-временное вывод:
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > «Ускорение»-это скорость ускорения, «метод»-это «ddim», «pndm», «dpm-solver» или «unipc», «kstep»-это количество шагов мелких диффузии, «дифференцировка»-это идентификатор диффузии диффузионной модели, а другие параметры имеют то же значение, что и main.py
Разумный «kstep» составляет около 100 ~ 300. Может быть предполагаемая потеря качества звука, когда «ускорение» превышает 20.
Если тот же идентификатор был использован для представления одного и того же динамика во время обучения, «-диффид» может быть пустым, в противном случае необходимо указать опцию «-диффид».
Если «-ddsp» пуста, используется чистая диффузионная модель, в настоящее время неглубокая диффузия выполняется с MEL входного источника, и если дальше '-Kstep' пуст, выполняется полная глубинная диффузия гаусса.
Программа автоматически проверит, соответствуют ли параметры модели DDSP и совпадения диффузионной модели (скорость выборки, размер прыжка и кодер), и если они не соответствуют, она будет игнорировать загрузку модели DDSP и ввести режим диффузии Гаусса.
(5) графический интерфейс в реальном времени :
python gui_diff.pyDDSP-SVC-новый проект по преобразованию голоса с открытым исходным кодом, посвященный разработке бесплатного программного обеспечения для AI Voice Changer, которое можно популяризировать на персональных компьютерах.
По сравнению со знаменитым SO-VITS-SVC, его обучение и синтез имеют гораздо более низкие требования к компьютерному оборудованию, и время обучения может быть сокращено на заказы величины, что близко к скорости обучения RVC.
Кроме того, при выполнении изменения голоса в режиме реального времени потребление аппаратного ресурса этого проекта значительно ниже, чем у So-Vits-SVC, но, вероятно, немного выше, чем в последней версии RVC.
Хотя первоначальное качество синтеза DDSP не является идеальным (исходный вывод можно услышать в Tensorboard во время обучения), после повышения качества звука с помощью предварительно обученного усилителя на основе Vocoder (старая версия) или с малой диффузионной моделью (новая версия), для некоторых наборов данных он может достичь качества синтеза, не меньше, чем Sovits-SVC и RVC.
Старые модели версий по -прежнему совместимы, следующие главы являются инструкциями для старой версии. Некоторые операции новой версии одинаковы, см. Предыдущие главы.
Отказ от ответственности: Пожалуйста, убедитесь, что обучайте только модели DDSP-SVC с юридически полученными авторизованными данными , и не используйте эти модели и любой аудио, который они синтезируют для незаконных целей. Автор этого хранилища не несет ответственности за какие -либо нарушения, мошенничество и другие незаконные действия, вызванные использованием этих модельных контрольных точек и аудио.
Журнал обновления: я слишком ленив, чтобы переводить, см. Китайскую версию Readme.
Мы рекомендуем сначала установить Pytorch с официального веб -сайта, затем запустите:
pip install -r requirements.txtПримечание. Я тестирую только код, используя Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0, слишком новые или слишком старые зависимости могут не работать
Обновление: Python 3.8 (Windows) + CUDA 11.8 + TORCH 2.0.0 + TORCHAUDIO 2.0.1 Работы, а обучение быстрее.
(1) Загрузите предварительно обученный энкодер ContentVec и поместите его в папку pretrain/contentvec .
(2) Загрузите предварительно обученный энкодер Hubertsoft и поместите его в папку pretrain/hubert , а затем измените файл конфигурации одновременно.
Загрузите и расслабляйте предварительно обученный nsf-hifigan Vocoder
Или используйте проект https://github.com/openvpi/singingvocoders, чтобы точно настроить вокад для более высокого качества звука.
Затем переименование файла контрольной точки и поместите его в местоположении, указанном параметром 'Vocoder.ckpt' в файле конфигурации. Значение по умолчанию - pretrain/nsf_hifigan/model .
«Config.json» Vocoder должен быть в том же каталоге, например, pretrain/nsf_hifigan/config.json .
Загрузите предварительно обученный экстрактор RMVPE и разкаплите его в pretrain/ папку.
Поместите весь набор учебных данных ( data/train/audio Поместите весь набор данных проверки (.WAV Format Audio Clips) в приведенном ниже каталоге: data/val/audio . Вы также можете бежать
python draw.py Чтобы помочь вам выбрать данные проверки (вы можете настроить параметры в draw.py , чтобы изменить количество извлеченных файлов и других параметров)
Затем беги
python preprocess.py -c configs/combsub.yamlДля модели комбитузинного субстративного синтезатора ( рекомендовать ) или запустить
python preprocess.py -c configs/sins.yamlДля модели синусоидов аддитивный синтезатор.
Для обучения диффузионной модели см. В разделе 3.0, 4.0 или 5.0 выше.
Вы можете изменить конфигурацию файла config/<model_name>.yaml перед предварительной обработкой. Конфигурация по умолчанию подходит для обучения синтезатора скорости отбора проб 44,1 кГц с помощью видеокарты GTX-1660.
ПРИМЕЧАНИЕ 1: Пожалуйста, сохраните скорость выборки всех аудиофилков в соответствии с скоростью отбора проб в файле конфигурации YAML! Если это не согласованно, программа может быть выполнена безопасно, но повторная выборка во время учебного процесса будет очень медленной.
ПРИМЕЧАНИЕ 2: Общее количество аудио -клипов для набора обучающих данных рекомендуется составлять около 1000, особенно длинный аудиоклип может быть разрезан на короткие сегменты, что ускорит обучение, но продолжительность всех аудио -клипов не должна составлять менее 2 секунд. Если слишком много аудио-клипов, вам нужна большая внутренняя память или установить опцию «cache_all_data» для FALSE в файле конфигурации.
ПРИМЕЧАНИЕ 3: Общее количество аудио клипов для набора данных проверки рекомендуется составлять около 10, пожалуйста, не ставите слишком много, иначе будет очень медленно для проверки.
ПРИМЕЧАНИЕ 4: Если ваш набор данных не очень высокий качество, установите «F0_Extractor» для «rmvpe» в файле конфигурации.
ПРИМЕЧАНИЕ 5: Сейчас поддерживается обучение с несколькими динамиками. Параметр 'n_spk' в файле конфигурации управляет тем, является ли это моделью с несколькими динамиками. Если вы хотите обучить многопрофильную модель, аудио папки должны быть названы с положительными целыми числами, не больше, чем «n_spk» для представления идентификаторов ораторов, структура каталогов подобна ниже:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...Если 'n_spk' = 1, структура каталога модели единого динамика все еще поддерживается, что подобно ниже:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yamlКомандная строка для обучения других моделей похожа.
Вы можете безопасно прервать обучение, тогда запуск той же командной строки возобновит обучение.
Вы также можете определить модель, если сначала прерываете обучение, а затем перепроектируйте новый набор данных или изменить параметры обучения (пакетный, LR и т. Д.), А затем запустите одну и ту же командную строку.
# check the training status using tensorboard
tensorboard --logdir=expТестовые образцы звука будут видны в Tensorboard после первой проверки.
ПРИМЕЧАНИЕ. Тестовые образцы звука в Tensorboard являются исходными выходами вашей модели DDSP-SVC, которая не улучшается энхансером. Если вы хотите проверить синтетический эффект после использования Enhancer (который может иметь более высокое качество), используйте метод, описанный в следующей главе.
( Рекомендовать ) Увеличьте выход, используя усилитель на основе вокадного ворота:
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >Необработанный выход DDSP:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseДругие варианты экстрактора F0 и ответа Threhold , Смотрите:
python main.py -h(Обновление) Секретарь смеси теперь поддерживается. Вы можете использовать опцию «-mix» для разработки своего собственного вокального тембра, ниже приведен пример:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0Начните простой графический интерфейс со следующей командой:
python gui.pyФронт-энд использует такие технологии, как раздвижное окно, перекрестное сплав, сплайсинг на основе SOLA и контекстная семантическая ссылка, которая может достичь качества звука, близкого к нереальному синтезу с низкой задержкой и ресурсной занятием.
Обновление: теперь добавлен алгоритм сплайсинга, основанный на фазовом Vocoder, но в большинстве случаев алгоритм Sola уже обладает качеством звука сплайсинга, поэтому он отключается по умолчанию. Если вы стремитесь к экстремальному качеству звука в реальном времени в реальном времени, вы можете подумать о том, чтобы включить его и тщательно настройку параметров, и есть вероятность, что качество звука будет выше. Тем не менее, большое количество тестов показало, что если перекрестное время превышает 0,1 секунды, фазовый вокадер вызовет значительное ухудшение качества звука.
DDSP
PC-DDSP
мягкий VC
ContentVec
Diffsinger (версия OpenVPI)
Diff-SVC
Диффузия-SVC


