DDSP SVC
ved DDSP Cascade Diffusion Model
ภาษา: ภาษาอังกฤษ简体中文 한국어( ล้าสมัย)
(1) การประมวลผลล่วงหน้า:
python preprocess.py -c configs/reflow.yaml(2) การฝึกอบรม:
python train_reflow.py -c configs/reflow.yaml(3) การอนุมานแบบไม่เรียลไทม์:
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > 'infer_step' คือจำนวนขั้นตอนการสุ่มตัวอย่างสำหรับบทกวีที่แก้ไขแล้ว 'วิธี' คือ 'ออยเลอร์' หรือ 'rk4', 't_start' เป็นจุดเริ่มต้นของ ODE ซึ่งต้องมีขนาดใหญ่กว่าหรือเท่ากับ t_start ในไฟล์กำหนดค่า
การติดตั้งการพึ่งพาการเตรียมข้อมูลการกำหนดค่าตัวเข้ารหัสที่ผ่านการฝึกอบรมมาก่อน (Hubert หรือ ContentVec), Pitch Extractor (RMVPE) และ Vocoder (NSF-Hifigan) นั้นเหมือนกับการฝึกอบรมแบบจำลอง DDSP บริสุทธิ์ (ดูหัวข้อด้านล่าง)
เรามีรูปแบบที่ผ่านการฝึกอบรมมาก่อนในหน้ารุ่น
ย้าย model_0.pt ไปยังโฟลเดอร์ส่งออกโมเดลที่ระบุโดยพารามิเตอร์ 'expdir' ใน diffusion-fast.yaml และโปรแกรมจะโหลดโมเดลที่ผ่านการฝึกอบรมล่วงหน้าโดยอัตโนมัติในโฟลเดอร์นั้น
(1) การประมวลผลล่วงหน้า:
python preprocess.py -c configs/diffusion-fast.yaml(2) ฝึกอบรมโมเดลคาสเคด (ฝึกอบรมเพียงรุ่นเดียว):
python train_diff.py -c configs/diffusion-fast.yaml(3) การอนุมานแบบไม่เรียลไทม์:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > รุ่นรุ่น 5.0 มีโมเดล DDSP ในตัวดังนั้นการระบุโมเดล DDSP ภายนอกโดยใช้ -ddsp นั้นไม่จำเป็น ตัวเลือกอื่นมีความหมายเช่นเดียวกับรุ่น 3.0 แต่ 'kstep' จะต้องน้อยกว่าหรือเท่ากับ k_step_max ในไฟล์การกำหนดค่าขอแนะนำให้ทำให้มันเท่ากัน (ค่าเริ่มต้นคือ 100)
(4) GUI แบบเรียลไทม์:
python gui_diff.pyหมายเหตุ: คุณต้องโหลดรุ่นเวอร์ชัน 5.0 ทางด้านขวามือของ GUI
การติดตั้งการพึ่งพาการเตรียมข้อมูลการกำหนดค่าตัวเข้ารหัสที่ผ่านการฝึกอบรมมาก่อน (Hubert หรือ ContentVec), Pitch Extractor (RMVPE) และ Vocoder (NSF-Hifigan) นั้นเหมือนกับการฝึกอบรมแบบจำลอง DDSP บริสุทธิ์ (ดูหัวข้อด้านล่าง)
เรามีรูปแบบที่ผ่านการฝึกอบรมมาก่อน: https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/pre-trained-model/model_0.pt (ใช้ 'contentVec768L12' encoder)
ย้าย model_0.pt ไปยังโฟลเดอร์ส่งออกโมเดลที่ระบุโดยพารามิเตอร์ 'expdir' ใน diffusion-new.yaml และโปรแกรมจะโหลดโมเดลที่ผ่านการฝึกอบรมล่วงหน้าโดยอัตโนมัติในโฟลเดอร์นั้น
(1) การประมวลผลล่วงหน้า:
python preprocess.py -c configs/diffusion-new.yaml(2) ฝึกอบรมโมเดลคาสเคด (ฝึกอบรมเพียงรุ่นเดียว):
python train_diff.py -c configs/diffusion-new.yamlหมายเหตุ: มีปัญหาชั่วคราวเกี่ยวกับการฝึกอบรม FP16 แต่ FP32 และ BF16 ทำงานได้ตามปกติ
(3) การอนุมานแบบไม่เรียลไทม์:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > รุ่น 4.0 รุ่นมีโมเดล DDSP ในตัวดังนั้นการระบุโมเดล DDSP ภายนอกโดยใช้ -ddsp นั้นไม่จำเป็น ตัวเลือกอื่นมีความหมายเช่นเดียวกับรุ่น 3.0 แต่ 'kstep' จะต้องน้อยกว่าหรือเท่ากับ k_step_max ในไฟล์การกำหนดค่าขอแนะนำให้ทำให้มันเท่ากัน (ค่าเริ่มต้นคือ 100)
(4) GUI แบบเรียลไทม์:
python gui_diff.pyหมายเหตุ: คุณต้องโหลดรุ่นเวอร์ชัน 4.0 ทางด้านขวามือของ GUI
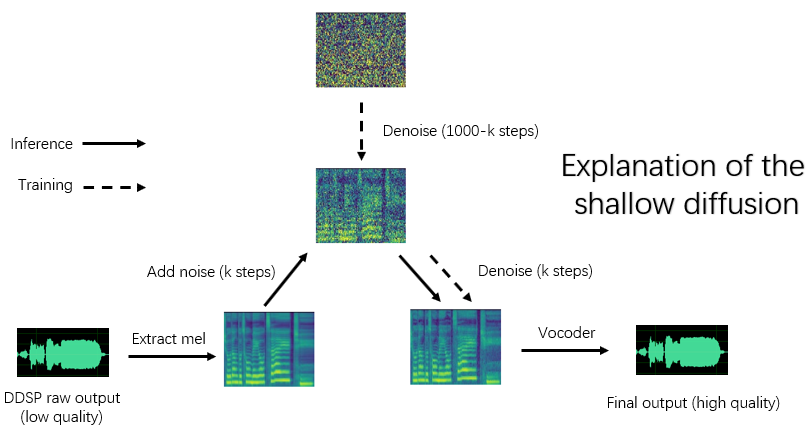
การติดตั้งการพึ่งพาการเตรียมข้อมูลการกำหนดค่าตัวเข้ารหัสที่ผ่านการฝึกอบรมมาก่อน (Hubert หรือ ContentVec), Pitch Extractor (RMVPE) และ Vocoder (NSF-Hifigan) นั้นเหมือนกับการฝึกอบรมแบบจำลอง DDSP บริสุทธิ์ (ดูบทที่ 1 ~ 3 ด้านล่าง)
เนื่องจากรูปแบบการแพร่กระจายนั้นยากกว่าที่จะฝึกอบรมเราจึงจัดทำโมเดลที่ผ่านการฝึกอบรมมาก่อน:
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt (ใช้ encoder 'hubertsoft)
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/fix_pitch_add_vctk_600k/model_0.pt (ใช้ 'contentVec768L12' encoder)
ย้าย model_0.pt ไปยังโฟลเดอร์ส่งออกโมเดลที่ระบุโดยพารามิเตอร์ 'expdir' ใน diffusion.yaml และโปรแกรมจะโหลดโมเดลที่ผ่านการฝึกอบรมล่วงหน้าโดยอัตโนมัติในโฟลเดอร์นั้น
(1) การประมวลผลล่วงหน้า:
python preprocess.py -c configs/diffusion.yamlการประมวลผลล่วงหน้านี้ยังสามารถใช้ในการฝึกอบรมโมเดล DDSP โดยไม่ต้องประมวลผลล่วงหน้าสองครั้ง แต่คุณต้องตรวจสอบให้แน่ใจว่าพารามิเตอร์ภายใต้แท็ก 'ข้อมูล' ในไฟล์ YAML นั้นสอดคล้องกัน
(2) ฝึกอบรมแบบจำลองการแพร่:
python train_diff.py -c configs/diffusion.yaml(3) ฝึกอบรมรุ่น DDSP:
python train.py -c configs/combsub.yaml ดังที่ได้กล่าวไว้ข้างต้นไม่จำเป็นต้องประมวลผลซ้ำ แต่โปรดตรวจสอบว่าพารามิเตอร์ของ combsub.yaml และ diffusion.yaml จับคู่หรือไม่ จำนวนของลำโพง 'N_SPK' อาจไม่สอดคล้องกัน แต่พยายามใช้ ID เดียวกันเพื่อแสดงลำโพงตัวเดียวกัน (ทำให้การอนุมานง่ายขึ้น)
(4) การอนุมานแบบไม่เรียลไทม์:
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 'speedup' คือความเร็วการเร่งความเร็ว 'เมธอด' คือ 'ddim', 'pndm', 'dpm-solver' หรือ 'unipc', 'kstep' คือจำนวนขั้นตอนการแพร่กระจายตื้น 'diffid' เป็นรหัสลำโพงของแบบจำลองการแพร่กระจายและพารามิเตอร์อื่น ๆ มีความหมายเช่นเดียวกับ main.py
'kstep' ที่สมเหตุสมผลอยู่ที่ประมาณ 100 ~ 300 อาจมีการสูญเสียคุณภาพเสียงที่รับรู้เมื่อ 'การเร่งความเร็ว' เกิน 20
หาก ID เดียวกันถูกใช้เพื่อเป็นตัวแทนของลำโพงเดียวกันในระหว่างการฝึกอบรม '-diffid' อาจว่างเปล่ามิฉะนั้นจะต้องระบุตัวเลือก '-diffid'
หาก '-DDSP' ว่างเปล่าจะใช้โมเดลการแพร่กระจายบริสุทธิ์ในเวลานี้การแพร่กระจายแบบตื้นจะดำเนินการกับ MEL ของแหล่งอินพุตและหากเพิ่มเติม '-KSTEP' ว่างเปล่า
โปรแกรมจะตรวจสอบโดยอัตโนมัติว่าพารามิเตอร์ของโมเดล DDSP และการจับคู่การแพร่กระจาย (อัตราการสุ่มตัวอย่างขนาดฮ็อพและตัวเข้ารหัส) และหากไม่ตรงกันมันจะไม่สนใจการโหลดโมเดล DDSP และเข้าสู่โหมดการแพร่กระจายแบบเกาส์เซียน
(5) GUI แบบเรียลไทม์:
python gui_diff.pyDDSP-SVC เป็นโครงการแปลงเสียงโอเพ่นซอร์สใหม่ที่อุทิศให้กับการพัฒนาซอฟต์แวร์เปลี่ยนเสียง AI ฟรีที่สามารถเป็นที่นิยมในคอมพิวเตอร์ส่วนบุคคล
เมื่อเทียบกับ SO-VITS-SVC ที่มีชื่อเสียงการฝึกอบรมและการสังเคราะห์มีข้อกำหนดที่ต่ำกว่าสำหรับฮาร์ดแวร์คอมพิวเตอร์และเวลาการฝึกอบรมสามารถสั้นลงตามคำสั่งของขนาดซึ่งใกล้เคียงกับความเร็วในการฝึกอบรมของ RVC
นอกจากนี้เมื่อทำการเปลี่ยนเสียงแบบเรียลไทม์การใช้ทรัพยากรฮาร์ดแวร์ของโครงการนี้ต่ำกว่า SO-VITS-SVC, อย่างมาก แต่อาจสูงกว่า RVC เวอร์ชันล่าสุดเล็กน้อย
แม้ว่าคุณภาพการสังเคราะห์ดั้งเดิมของ DDSP นั้นไม่เหมาะ (สามารถได้ยินเอาต์พุตดั้งเดิมใน Tensorboard ในขณะที่การฝึกอบรม) หลังจากเพิ่มคุณภาพเสียงด้วยเครื่องเพิ่มประสิทธิภาพที่ได้รับการฝึกฝนมาก่อน (รุ่นเก่า) หรือรุ่นการแพร่กระจายตื้น (รุ่นใหม่) สำหรับชุดข้อมูลบางชุด
รุ่นเก่ายังคงใช้งานร่วมกันได้บทต่อไปนี้เป็นคำแนะนำสำหรับเวอร์ชันเก่า การดำเนินการบางอย่างของเวอร์ชันใหม่เหมือนกันดูบทก่อนหน้า
ข้อจำกัดความรับผิดชอบ: โปรดตรวจสอบให้แน่ใจว่าได้ฝึกอบรมเฉพาะรุ่น DDSP-SVC ที่มี ข้อมูลที่ได้รับอนุญาตตามกฎหมาย และไม่ใช้โมเดลเหล่านี้และเสียงใด ๆ ที่พวกเขาสังเคราะห์เพื่อวัตถุประสงค์ที่ผิดกฎหมาย ผู้เขียนที่เก็บนี้จะไม่รับผิดชอบต่อการละเมิดการฉ้อโกงและการกระทำที่ผิดกฎหมายอื่น ๆ ที่เกิดจากการใช้ด่านตรวจสอบและเสียงเหล่านี้
บันทึกอัปเดต: ฉันขี้เกียจเกินไปที่จะแปลโปรดดู readme เวอร์ชันภาษาจีน
เราขอแนะนำให้ติดตั้ง pytorch ก่อนจากเว็บไซต์ทางการจากนั้นเรียกใช้:
pip install -r requirements.txtหมายเหตุ: ฉันทดสอบรหัสโดยใช้ Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0 การพึ่งพาใหม่หรือเก่าเกินไปอาจไม่ทำงาน
อัปเดต: Python 3.8 (Windows) + Cuda 11.8 + Torch 2.0.0 + Torchaudio 2.0.1 งานและการฝึกอบรมเร็วขึ้น
(1) ดาวน์โหลดตัวเข้ารหัส ContentVec ที่ผ่านการฝึกอบรมมาแล้วและวางไว้ภายใต้โฟลเดอร์ pretrain/contentvec
(2) ดาวน์โหลดตัวเข้ารหัส Hubertsoft ที่ผ่านการฝึกอบรมมาแล้วและวางไว้ภายใต้โฟลเดอร์ pretrain/hubert จากนั้นแก้ไขไฟล์การกำหนดค่าในเวลาเดียวกัน
ดาวน์โหลดและคลายซิปคำ Vocoder NSF-Hifigan ที่ผ่านการฝึกอบรมมาก่อน
หรือใช้ https://github.com/openvpi/singingvocoders โครงการเพื่อปรับแต่งเสียงร้องเพื่อคุณภาพเสียงที่สูงขึ้น
จากนั้นเปลี่ยนชื่อไฟล์จุดตรวจสอบและวางไว้ที่ตำแหน่งที่ระบุโดยพารามิเตอร์ 'vocoder.ckpt' ในไฟล์การกำหนดค่า ค่าเริ่มต้นคือ pretrain/nsf_hifigan/model
'config.json' ของ vocoder จะต้องอยู่ที่ไดเรกทอรีเดียวกันตัวอย่างเช่น pretrain/nsf_hifigan/config.json
ดาวน์โหลดตัวแยก RMVPE ที่ผ่านการฝึกอบรมมาแล้วและคลายซิปลงใน pretrain/ โฟลเดอร์
ใส่ชุดข้อมูลการฝึกอบรมทั้งหมด (. wav รูปแบบคลิปเสียง) ในไดเรกทอรีด้านล่าง: data/train/audio ใส่ชุดข้อมูลการตรวจสอบทั้งหมด (. wav รูปแบบคลิปเสียง) ในไดเรกทอรีด้านล่าง: data/val/audio คุณยังสามารถเรียกใช้
python draw.py เพื่อช่วยคุณเลือกข้อมูลการตรวจสอบความถูกต้อง (คุณสามารถปรับพารามิเตอร์ใน draw.py เพื่อแก้ไขจำนวนไฟล์ที่แยกและพารามิเตอร์อื่น ๆ )
จากนั้นวิ่ง
python preprocess.py -c configs/combsub.yamlสำหรับโมเดลของ synthesizer substractive combtooth ( แนะนำ ) หรือเรียกใช้
python preprocess.py -c configs/sins.yamlสำหรับแบบจำลองของ synthesizer สารเติมแต่งไซน์
สำหรับการฝึกอบรมรูปแบบการแพร่ดูดูหัวข้อ 3.0, 4.0 หรือ 5.0 ด้านบน
คุณสามารถแก้ไขการกำหนดค่าไฟล์ config/<model_name>.yaml ก่อนการประมวลผลล่วงหน้า การกำหนดค่าเริ่มต้นเหมาะสำหรับการฝึกอบรม 44.1kHz สูง synthesizer อัตราการสุ่มตัวอย่างด้วยการ์ดกราฟิก GTX-1660
หมายเหตุ 1: โปรดเก็บอัตราการสุ่มตัวอย่างของคลิปเสียงทั้งหมดที่สอดคล้องกับอัตราการสุ่มตัวอย่างในไฟล์กำหนดค่า YAML! หากไม่สอดคล้องกันโปรแกรมสามารถดำเนินการได้อย่างปลอดภัย แต่การสุ่มตัวอย่างระหว่างกระบวนการฝึกอบรมจะช้ามาก
หมายเหตุ 2: จำนวนคลิปเสียงทั้งหมดสำหรับชุดข้อมูลการฝึกอบรมแนะนำให้ประมาณ 1,000 โดยเฉพาะอย่างยิ่งคลิปเสียงที่ยาวสามารถถูกตัดเป็นส่วนสั้น ๆ ซึ่งจะเพิ่มความเร็วในการฝึกอบรม แต่ระยะเวลาของคลิปเสียงทั้งหมดไม่ควรน้อยกว่า 2 วินาที หากมีคลิปเสียงมากเกินไปคุณต้องมีหน่วยความจำภายในขนาดใหญ่หรือตั้งค่าตัวเลือก 'CACHE_ALL_DATA' เป็นเท็จในไฟล์การกำหนดค่า
หมายเหตุ 3: จำนวนคลิปเสียงทั้งหมดสำหรับชุดข้อมูลการตรวจสอบความถูกต้องแนะนำให้ประมาณ 10 โปรดอย่าใส่มากเกินไปหรือจะช้ามากในการตรวจสอบความถูกต้อง
หมายเหตุ 4: หากชุดข้อมูลของคุณมีคุณภาพสูงมากให้ตั้งค่า 'F0_Extractor' เป็น 'RMVPE' ในไฟล์ config
หมายเหตุ 5: รองรับการฝึกอบรมหลายลำโพงตอนนี้ พารามิเตอร์ 'N_SPK' ในการควบคุมไฟล์การกำหนดค่าว่าเป็นโมเดลหลายลำโพงหรือไม่ หากคุณต้องการฝึกอบรมโมเดล หลายลำโพง โฟลเดอร์เสียงจะต้องมีการตั้งชื่อด้วย จำนวนเต็มบวกไม่เกิน 'N_SPK' เพื่อแสดงรหัสลำโพงโครงสร้างไดเรกทอรีเหมือนด้านล่าง:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...ถ้า 'n_spk' = 1 โครงสร้างไดเรกทอรีของโมเดล ลำโพงเดียว ยังคงรองรับซึ่งเป็นเหมือนด้านล่าง:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yamlบรรทัดคำสั่งสำหรับการฝึกอบรมโมเดลอื่น ๆ นั้นคล้ายคลึงกัน
คุณสามารถขัดจังหวะการฝึกอบรมได้อย่างปลอดภัยจากนั้นเรียกใช้บรรทัดคำสั่งเดียวกันจะกลับมาฝึกอบรมต่อ
นอกจากนี้คุณยังสามารถ finetune โมเดลหากคุณขัดจังหวะการฝึกอบรมก่อนจากนั้นนำชุดข้อมูลใหม่หรือเปลี่ยนพารามิเตอร์การฝึกอบรมอีกครั้ง (BatchSize, LR ฯลฯ ) จากนั้นเรียกใช้บรรทัดคำสั่งเดียวกัน
# check the training status using tensorboard
tensorboard --logdir=expตัวอย่างเสียงทดสอบจะปรากฏใน Tensorboard หลังจากการตรวจสอบครั้งแรก
หมายเหตุ: ตัวอย่างเสียงทดสอบใน Tensorboard เป็นเอาต์พุตดั้งเดิมของโมเดล DDSP-SVC ของคุณที่ไม่ได้รับการปรับปรุงโดยเครื่องเพิ่มประสิทธิภาพ หากคุณต้องการทดสอบเอฟเฟกต์สังเคราะห์หลังจากใช้ตัวเพิ่มประสิทธิภาพ (ซึ่งอาจมีคุณภาพสูงกว่า) โปรดใช้วิธีการที่อธิบายไว้ในบทต่อไปนี้
( แนะนำ ) ปรับปรุงเอาต์พุตโดยใช้เครื่องเพิ่มประสิทธิภาพตามคำแนะนำที่ใช้แล้ว:
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >เอาต์พุตดิบของ DDSP:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseตัวเลือกอื่น ๆ เกี่ยวกับ F0 Extractor และการตอบสนอง threhold, ดู:
python main.py -h(อัปเดต) รองรับไอพ่นมิกซ์ได้แล้ว คุณสามารถใช้ตัวเลือก "-mix" เพื่อออกแบบเสียงร้องของคุณเองด้านล่างเป็นตัวอย่าง:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0เริ่ม GUI ง่ายๆด้วยคำสั่งต่อไปนี้:
python gui.pyส่วนหน้าใช้เทคโนโลยีเช่นหน้าต่างบานเลื่อนการซีดจางการประกบแบบอิงโซล่าและการอ้างอิงความหมายตามบริบทซึ่งสามารถบรรลุคุณภาพเสียงใกล้เคียงกับการสังเคราะห์ที่ไม่ใช่เวลาจริงด้วยเวลาแฝงต่ำและการประกอบอาชีพของทรัพยากร
UPDATE: ตอนนี้มีการเพิ่มอัลกอริทึมการประกบที่อิงตามเฟส Vocoder แล้ว แต่ในกรณีส่วนใหญ่อัลกอริทึม SOLA มีคุณภาพเสียงที่มีการประกบสูงพออยู่แล้วดังนั้นจึงถูกปิดโดยค่าเริ่มต้น หากคุณกำลังติดตามคุณภาพเสียงแบบเรียลไทม์ต่ำสุดขีดคุณสามารถพิจารณาเปิดและปรับพารามิเตอร์อย่างระมัดระวังและมีความเป็นไปได้ที่คุณภาพเสียงจะสูงขึ้น อย่างไรก็ตามมีการทดสอบจำนวนมากพบว่าหากเวลาข้ามเพดานยาวกว่า 0.1 วินาทีผู้ร้องเฟสจะทำให้เกิดการเสื่อมสภาพอย่างมีนัยสำคัญในคุณภาพเสียง
DDSP
PC-DDSP
Soft-VC
contentVec
diffsinger (เวอร์ชัน OpenVPI)
Diff-SVC
การแพร่กระจาย


