DDSP SVC
ved DDSP Cascade Diffusion Model
Idioma: Inglés简体中文 한국어( Desactivado)
(1) Preprocesamiento:
python preprocess.py -c configs/reflow.yaml(2) Entrenamiento:
python train_reflow.py -c configs/reflow.yaml(3) Inferencia no en tiempo real:
python main_reflow.py -i < input.wav > -m < model_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -step < infer_step > -method < method > -ts < t_start > 'Infer_step' es el número de pasos de muestreo para la ODE de flujo rectificado, 'método' es 'euler' o 'rk4', 't_start' es el punto de inicio de oda, que debe ser más grande o igual que t_start en el archivo de configuración, se recomienda mantener igual a 0.7)
Instalar dependencias, preparación de datos, configuración del codificador previamente entrenado (Hubert o ContentVec), extractor de tono (RMVPE) y Vocoder (NSF-Hifigan) son los mismos que el entrenamiento de un modelo DDSP puro (ver sección a continuación).
Proporcionamos un modelo previamente capacitado en la página de lanzamiento.
Mueva el model_0.pt a la carpeta de exportación del modelo especificada por el parámetro 'expdir' en diffusion-fast.yaml , y el programa cargará automáticamente el modelo previamente capacitado en esa carpeta.
(1) Preprocesamiento:
python preprocess.py -c configs/diffusion-fast.yaml(2) Entrenar un modelo en cascada (solo entrenar un modelo):
python train_diff.py -c configs/diffusion-fast.yaml(3) Inferencia no en tiempo real:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > El modelo de versión 5.0 tiene un modelo DDSP incorporado, por lo que especificar un modelo DDSP externo que usa -ddsp es innecesario. Las otras opciones tienen el mismo significado que el modelo de versión 3.0, pero 'kstep' debe ser menor o igual a k_step_max En el archivo de configuración, se recomienda mantener igual (el valor predeterminado es 100)
(4) GUI en tiempo real:
python gui_diff.pyNota: debe cargar el modelo de la versión 5.0 en el lado derecho de la GUI
Instalar dependencias, preparación de datos, configuración del codificador previamente entrenado (Hubert o ContentVec), extractor de tono (RMVPE) y Vocoder (NSF-Hifigan) son los mismos que el entrenamiento de un modelo DDSP puro (ver sección a continuación).
Proporcionamos un modelo previamente entrenado aquí: https://huggingface.co/datasets/ms903/ddsp-svc-4.0/resolve/main/pre-trained-model/model_0.pt (usando 'contentvec768l12' encoder)
Mueva el model_0.pt a la carpeta de exportación del modelo especificada por el parámetro 'expdir' en diffusion-new.yaml , y el programa cargará automáticamente el modelo previamente capacitado en esa carpeta.
(1) Preprocesamiento:
python preprocess.py -c configs/diffusion-new.yaml(2) Entrenar un modelo en cascada (solo entrenar un modelo):
python train_diff.py -c configs/diffusion-new.yamlNota: Hay un problema temporal con el entrenamiento FP16, pero FP32 y BF16 funcionan normalmente,
(3) Inferencia no en tiempo real:
python main_diff.py -i < input.wav > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -speedup < speedup > -method < method > -kstep < kstep > El modelo de versión 4.0 tiene un modelo DDSP incorporado, por lo que especificar un modelo DDSP externo que usa -ddsp es innecesario. Las otras opciones tienen el mismo significado que el modelo de versión 3.0, pero 'kstep' debe ser menor o igual a k_step_max En el archivo de configuración, se recomienda mantener igual (el valor predeterminado es 100)
(4) GUI en tiempo real:
python gui_diff.pyNota: debe cargar el modelo de la versión 4.0 en el lado derecho de la GUI
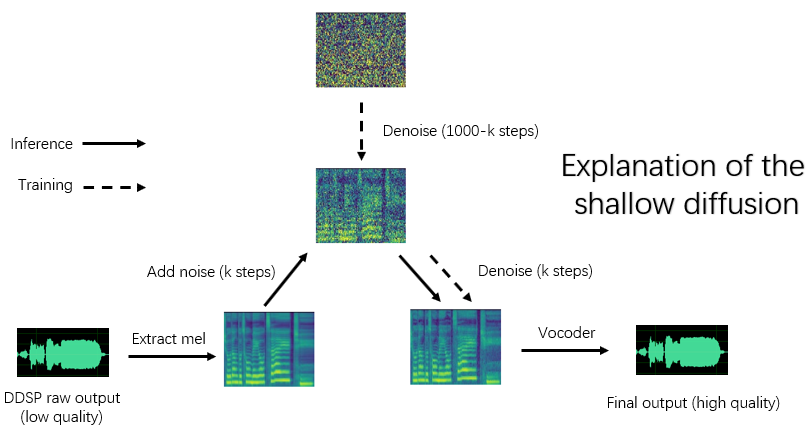
Instalar dependencias, preparación de datos, configuración del codificador previamente entrenado (Hubert o ContentVec), extractor de tono (RMVPE) y Vocoder (NSF-Hifigan) son los mismos que capacitar un modelo DDSP puro (ver Capítulo 1 ~ 3 a continuación).
Debido a que el modelo de difusión es más difícil de entrenar, proporcionamos algunos modelos previamente capacitados aquí:
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/hubertsoft_fix_pitch_add_vctk_500k/model_0.pt (usando 'hubertsoft' encoder)
https://huggingface.co/datasets/ms903/diff-svc-refactor-pre-trained-model/blob/main/fix_pitch_add_vctk_600k/model_0.pt (usando 'contentvec768l12' encoder)
Mueva el model_0.pt a la carpeta de exportación del modelo especificada por el parámetro 'expdir' en diffusion.yaml , y el programa cargará automáticamente los modelos previamente capacitados en esa carpeta.
(1) Preprocesamiento:
python preprocess.py -c configs/diffusion.yamlEste preprocesamiento también se puede utilizar para entrenar el modelo DDSP sin preprocesamiento dos veces, pero debe asegurarse de que los parámetros en la etiqueta 'Datos' en los archivos YAML sean consistentes.
(2) Entrenar un modelo de difusión:
python train_diff.py -c configs/diffusion.yaml(3) Entrenar un modelo DDSP:
python train.py -c configs/combsub.yaml Como se mencionó anteriormente, no se requiere volver a procesar, pero verifique si los parámetros de combsub.yaml y diffusion.yaml coinciden. El número de oradores 'N_SPK' puede ser inconsistente, pero intente usar la misma ID para representar el mismo altavoz (esto facilita la inferencia).
(4) Inferencia no en tiempo real:
python main_diff.py -i < input.wav > -ddsp < ddsp_ckpt.pt > -diff < diff_ckpt.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -diffid < diffusion_speaker_id > -speedup < speedup > -method < method > -kstep < kstep > 'Speedup' es la velocidad de aceleración, 'método' es 'ddim', 'pndm', 'dpm-solver' o 'uniPc', 'kstep' es el número de pasos de difusión poco profundos, 'diffid' es la identificación del altavoz del modelo de difusión, y otros parámetros tienen el mismo significado como main.py
Un 'kstep' razonable es de aproximadamente 100 ~ 300. Puede haber una pérdida percibida de calidad de sonido cuando 'Speedup' supera los 20.
Si la misma identificación se ha utilizado para representar el mismo orador durante la capacitación, '-diffid' puede estar vacía, de lo contrario, la opción '-diffid' debe especificarse.
Si '-DDSP' está vacío, el modelo de difusión puro se usa, en este momento, la difusión poco profunda se realiza con el MEL de la fuente de entrada, y si más allá '-kstep' se realiza vacía, se realiza la difusión gaussiana completa.
El programa verificará automáticamente si los parámetros del modelo DDSP y el modelo de difusión coinciden (velocidad de muestreo, tamaño de lúpulo y codificador), y si no coinciden, ignorará la carga del modelo DDSP e ingresará el modo de difusión gaussiana.
(5) GUI en tiempo real:
python gui_diff.pyDDSP-SVC es un nuevo proyecto de conversión de voz de código abierto dedicado al desarrollo del software gratuito de cambio de voz de IA que se puede popularizar en las computadoras personales.
En comparación con el famoso SO-VITS-SVC, su entrenamiento y síntesis tienen requisitos mucho más bajos para el hardware de la computadora, y el tiempo de entrenamiento puede acortarse por órdenes de magnitud, que está cerca de la velocidad de entrenamiento de RVC.
Además, al realizar el cambio de voz en tiempo real, el consumo de recursos de hardware de este proyecto es significativamente más bajo que el de SO-VITS-SVC, pero probablemente un poco más alto que la última versión de RVC.
Aunque la calidad de síntesis original de DDDSP no es ideal (la salida original se puede escuchar en Tensorboard mientras está entrenando), después de mejorar la calidad del sonido con un potenciador basado en vocoder previamente capacitado (versión anterior) o con un modelo de difusión poco profundo (nueva versión), para algunos conjuntos de datos, puede lograr la calidad de síntesis no menos que SOVITS-SVC y RVC.
Los modelos de versión antiguas aún son compatibles, los siguientes capítulos son las instrucciones para la versión anterior. Algunas operaciones de la nueva versión son las mismas, ver los capítulos anteriores.
Descargo de responsabilidad: asegúrese de capacitar solo a los modelos DDSP-SVC con datos autorizados legalmente obtenidos , y no use estos modelos y cualquier audio que sinteticen con fines ilegales. El autor de este repositorio no es responsable de ninguna infracción, fraude y otros actos ilegales causados por el uso de estos puntos de control de modelo y audio.
Registro de actualización: soy demasiado vago para traducir, consulte la versión china ReadMe.
Recomendamos primero instalar pytorch desde el sitio web oficial, luego ejecutar:
pip install -r requirements.txtNota: Solo pruebo el código usando Python 3.8 (Windows) + Torch 1.9.1 + Torchaudio 0.6.0, dependencias demasiado nuevas o demasiado antiguas pueden no funcionar
ACTUALIZACIÓN: Python 3.8 (Windows) + Cuda 11.8 + Torch 2.0.0 + Torchaudio 2.0.1 funciona, y la capacitación es más rápida.
(1) Descargue el codificador ContentVEC previamente capacitado y colóquelo en la carpeta pretrain/contentvec .
(2) Descargue el codificador HubertSoft previamente capacitado y colóquelo en la carpeta pretrain/hubert , y luego modifique el archivo de configuración al mismo tiempo.
Descargar y descomponer el vocoder NSF-Hifigan previamente entrenado
O use el proyecto https://github.com/openvpi/singingvocoders para engañar al vocoder para una mayor calidad de sonido.
Luego, cambie el nombre del archivo de punto de control y colóquelo en la ubicación especificada por el parámetro 'VOCODER.CKPT' en el archivo de configuración. El valor predeterminado es pretrain/nsf_hifigan/model .
El 'config.json' del Vocoder debe estar en el mismo directorio, por ejemplo, pretrain/nsf_hifigan/config.json .
Descargue el extractor RMVPE previamente capacitado y descózalo en pretrain/ carpeta.
Coloque todo el conjunto de datos de capacitación (clips de audio de formato .WAV) en el siguiente directorio: data/train/audio . Coloque todo el conjunto de datos de validación (clips de audio de formato .WAV) en el siguiente directorio: data/val/audio . También puedes correr
python draw.py Para ayudarlo a seleccionar datos de validación (puede ajustar los parámetros en draw.py para modificar el número de archivos extraídos y otros parámetros)
Luego corre
python preprocess.py -c configs/combsub.yamlPara un modelo de sintetizador de sustractivo combttooth ( recomendar ) o ejecutar
python preprocess.py -c configs/sins.yamlPara un modelo de sintetizador aditivo sinusoides.
Para capacitar al modelo de difusión, consulte la Sección 3.0, 4.0 o 5.0 arriba.
Puede modificar el archivo de configuración config/<model_name>.yaml antes del preprocesamiento. La configuración predeterminada es adecuada para capacitar un sintetizador de velocidad de muestreo de 44.1kHz con tarjeta gráfica GTX-1660.
Nota 1: ¡Mantenga la tasa de muestreo de todos los clips de audio consistentes con la tasa de muestreo en el archivo de configuración YAML! Si no es consistente, el programa se puede ejecutar de manera segura, pero el remuestreo durante el proceso de capacitación será muy lento.
Nota 2: Se recomienda que el número total de clips de audio para el conjunto de datos de entrenamiento sea de aproximadamente 1000, especialmente el clip de audio largo se puede cortar en segmentos cortos, lo que acelerará el entrenamiento, pero la duración de todos los clips de audio no debe ser menos de 2 segundos. Si hay demasiados clips de audio, necesita una gran memoria interna o establecer la opción 'Cache_all_Data' en False en el archivo de configuración.
Nota 3: Se recomienda que el número total de clips de audio para el conjunto de datos de validación sea de aproximadamente 10, no ponga demasiados o será muy lento para hacer la validación.
Nota 4: Si su conjunto de datos no es de muy alta calidad, establezca 'F0_EXTROTOR' en 'RMVPE' en el archivo de configuración.
Nota 5: El entrenamiento de múltiples altavoces ahora se admite. El parámetro 'N_SPK' en el archivo de configuración controla si es un modelo de múltiples altavoces. Si desea entrenar un modelo de múltiples altavoces , las carpetas de audio deben ser nombradas con enteros positivos no mayores que 'n_spk' para representar ID de altavoces, la estructura del directorio está como a continuación:
# training dataset
# the 1st speaker
data/train/audio/1/aaa.wav
data/train/audio/1/bbb.wav
...
# the 2nd speaker
data/train/audio/2/ccc.wav
data/train/audio/2/ddd.wav
...
# validation dataset
# the 1st speaker
data/val/audio/1/eee.wav
data/val/audio/1/fff.wav
...
# the 2nd speaker
data/val/audio/2/ggg.wav
data/val/audio/2/hhh.wav
...Si 'n_spk' = 1, la estructura del directorio del modelo de altavoz único todavía es compatible, que es como a continuación:
# training dataset
data/train/audio/aaa.wav
data/train/audio/bbb.wav
...
# validation dataset
data/val/audio/ccc.wav
data/val/audio/ddd.wav
... # train a combsub model as an example
python train.py -c configs/combsub.yamlLa línea de comando para capacitar a otros modelos es similar.
Puede interrumpir de manera segura el entrenamiento, luego ejecutar la misma línea de comando reanudará la capacitación.
También puede FINENE el modelo si interrumpe primero la capacitación, luego vuelve a depender del nuevo conjunto de datos o cambia los parámetros de capacitación (BatchSize, LR, etc.) y luego ejecuta la misma línea de comando.
# check the training status using tensorboard
tensorboard --logdir=expLas muestras de audio de prueba serán visibles en Tensorboard después de la primera validación.
Nota: Las muestras de audio de prueba en Tensorboard son las salidas originales de su modelo DDSP-SVC que no se ve mejorado por un potenciador. Si desea probar el efecto sintético después de usar el potenciador (que puede tener mayor calidad), utilice el método descrito en el siguiente capítulo.
( Recomendar ) Mejore la salida utilizando el potenciador basado en vocoder previo al vape:
# high audio quality in the normal vocal range if enhancer_adaptive_key = 0 (default)
# set enhancer_adaptive_key > 0 to adapt the enhancer to a higher vocal range
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -eak < enhancer_adaptive_key (semitones) >Salida sin procesar de DDSP:
# fast, but relatively low audio quality (like you hear in tensorboard)
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -id < speaker_id > -e falseOtras opciones sobre el extractor F0 y la respuesta a través de: ver:
python main.py -h(Actualización) Mix-speaker es compatible ahora. Puede usar la opción "-mix" para diseñar su propio timbre vocal, a continuación se muestra un ejemplo:
# Mix the timbre of 1st and 2nd speaker in a 0.5 to 0.5 ratio
python main.py -i < input.wav > -m < model_file.pt > -o < output.wav > -k < keychange (semitones) > -mix " {1:0.5, 2:0.5} " -eak 0Inicie una GUI simple con el siguiente comando:
python gui.pyEl front-end utiliza tecnologías como ventana deslizante, desamparo cruzado, empalme basado en sola y referencia semántica contextual, que pueden lograr una calidad de sonido cercana a la síntesis no real en tiempo real con baja latencia y ocupación de recursos.
ACTUALIZACIÓN: Ahora se agrega un algoritmo de empalme basado en un vocoder de fase, pero en la mayoría de los casos el algoritmo SOLA ya tiene una calidad de sonido de empalme lo suficientemente alta, por lo que se apaga de forma predeterminada. Si está buscando una calidad de sonido extrema de baja latencia en tiempo real, puede considerar encenderlo y ajustar los parámetros con cuidado, y existe la posibilidad de que la calidad de sonido sea más alta. Sin embargo, una gran cantidad de pruebas han encontrado que si el tiempo de fado cruzado es más largo de 0.1 segundos, el vocoder de fase causará una degradación significativa en la calidad del sonido.
DDSP
PC-DDSP
Soft-VC
Contentvec
Diffsinger (versión de OpenVPI)
Diff-svc
Difusión-SVC


