PFLlib
37 methods
我们为那些新的联合学习的人创建了一个对初学者友好的算法库和基准平台。加入我们,通过为该项目贡献您的算法,数据集和指标来扩展FL社区。
? Pfllib现在拥有其官方网站和域名:https://www.pfllib.com/ !!!
?排行榜是直播的!我们的方法(FEDCP,GPFL和Feddbe)导致了道路。值得注意的是,Feddbe在不同的数据异质性水平上表现出色。
?我们将在下一个版本中将许可证更改为Apache-2.0。
已经添加了四个新数据集,其中两个解决了实际情况:(1)来自来自不同医院的淋巴结切片中乳腺癌转移的肿瘤组织斑块,以及(2)不同相机陷阱捕获的野生动物照片。其他两个数据集侧重于标签链式场景:来自19 Covid-19的医院的胸部X射线图像,以及用于胃肠道疾病检测的医院的内窥镜图像。这些数据集也与我们的htfllib兼容
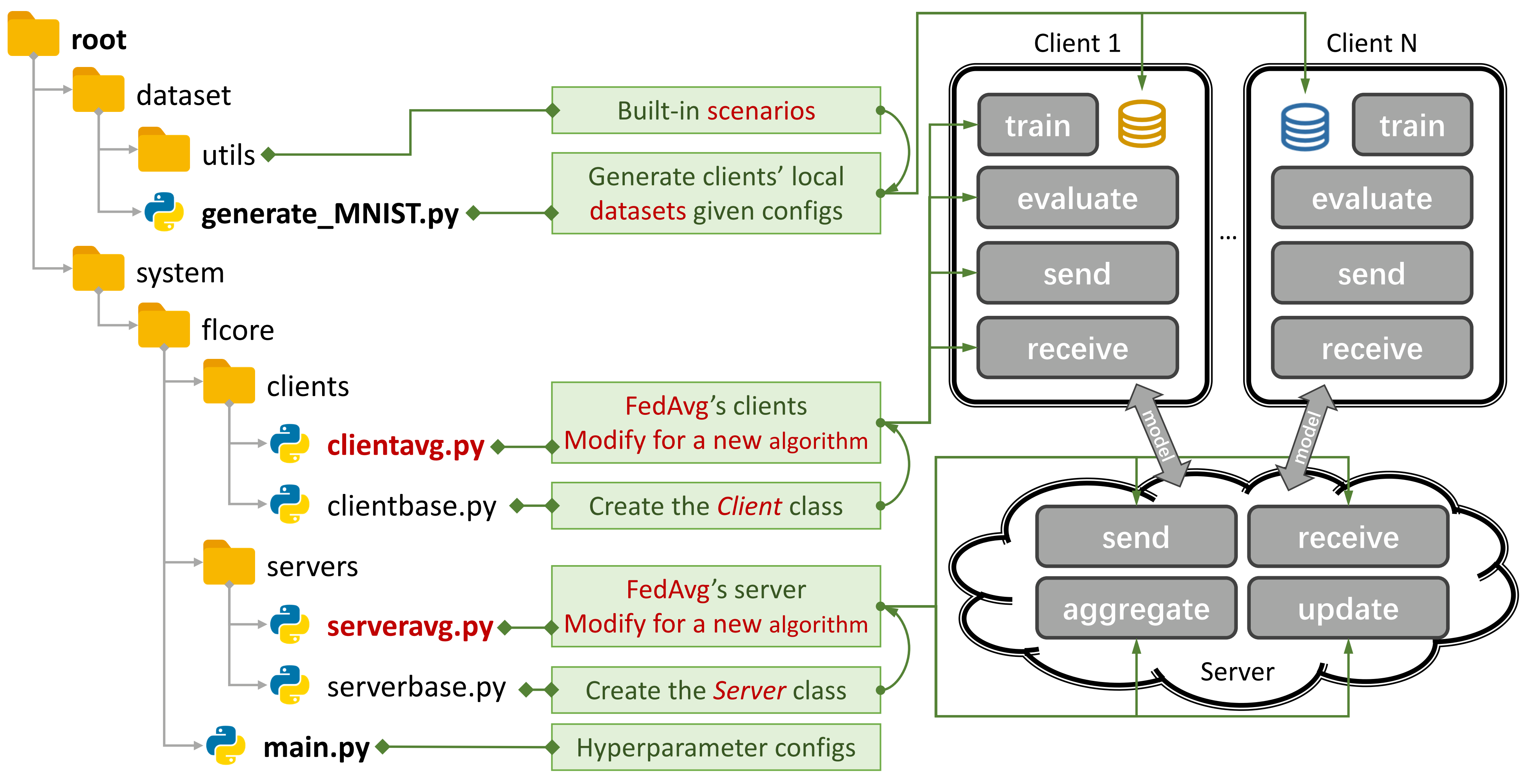 图1:FedAvg的示例。您可以使用
图1:FedAvg的示例。您可以使用generate_DATA.py创建一个方案,并使用main.py , clientNAME.py和serverNAME.py运行算法。对于新算法,您只需要在clientNAME.py和serverNAME.py中添加新功能。
如果您发现我们的存储库有用,请引用相应的论文:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37传统的FL(TFL)和个性化FL(PFL)算法,3个方案和24个数据集。
一些实验结果在其论文和此处都是可用的。
请参阅本指南以了解如何使用它。
基准平台可以使用CIFAR100上的4层CNN模拟场景,其中一个NVIDIA GEFORCE RTX 3090 GPU卡只有5.08GB GPU内存成本。
我们提供隐私评估和系统的研究建议。
现在,您可以通过设置args.num_new_clients in ./system/main.py来培训一些客户,并评估新客户的性能。请注意,并非所有TFL/PFL算法都支持此功能。
Pfllib主要关注数据(统计)异质性。有关算法和基准平台,该平台既可以解决数据和模型异质性,请参阅我们扩展的项目异质联合学习(HTFLLIB) 。
当我们努力满足各种用户需求时,该项目的频繁更新可能会改变默认设置和场景创建代码,从而影响实验结果。
出现错误时,封闭的问题可能会对您有所帮助。
提交拉动请求时,请在评论框中提供足够的说明和示例。
数据异质性现象的起源是用户的特征,他们生成非IID(不是独立且分布相同)和不平衡数据的特征。在FL情况下存在数据异质性,已经提出了无数方法来破解这种硬坚果。相比之下,个性化的FL(PFL)可以利用统计上异质的数据来学习每个用户的个性化模型。
传统的FL(TFL)
基本TFL
FedAvg - 从分散数据AISTATS 2017中对深层网络的沟通效率学习
基于更新校正的TFL
脚手架- 脚手架:联邦学习ICML 2020的随机控制平均
基于正则化的TFL
FEDPROX-在异质网络中联合优化MLSYS 2020
Feddyn-基于动态正则化ICLR 2021的联合学习
基于型号的TFL
月亮- 模型对抗性联合学习CVPR 2021
联邦快递- 通过logits校准ICML 2022的联合学习与标签分布偏斜
基于知识依据的TFL
FedGen-无数据知识蒸馏,用于异质联邦学习ICML 2021
FEDNTD - 通过联邦学习神经2022中的非实际蒸馏保护全球知识
个性化的FL(PFL)
基于元学习的PFL
Per-Fedavg - 具有理论保证的个性化联合学习:一种模型不合时宜的元学习方法神经2020
基于正则化的PFL
PFEDME - 莫罗信封神经2020的个性化联合学习
同上- 同上:通过个性化ICML 2021
基于个性化聚集的PFL
APFL - 自适应个性化联合学习2020
FedFomo - 一阶模型优化ICLR 2021的个性化联合学习
FedAmp - 非IID数据的个性化跨核心联合学习AAAI 2021
FEDPHP - FEDPHP:通过继承的私人模型ECML PKDD 2021的联合个性化
苹果- 适应适应:学习个性化的跨核心联合学习ijcai 2022
FEDALA - FEDALA:个性化联邦学习AAAI 2023的自适应本地聚合
基于模型分解的PFL
FEDPER - 与个性化层的联合学习2019
LG-FEDAVG - 在本地思考,全球行动:与本地和全球代表的联邦学习2020
FEDREP - 为个性化联合学习ICML 2021的共享表示形式
Fedrod-关于图像分类ICLR 2022的桥接通用和个性化联合学习
FedBabu - FedBabu:迈向联合图像分类ICLR 2022的增强表示形式
FedGC-联合学习以梯度校正AAAI 2022
FEDCP - FedCP:通过有条件政策KDD 2023分开特征信息,以供个性化联合学习
GPFL - GPFL:同时学习个性化联合学习ICCV 2023的通用和个性化功能信息
FEDGH - FEDGH:具有广义全球标头ACM MM 2023的异质联邦学习
Feddbe - 消除代表空间中联邦学习的领域偏见神经2023
FedCac-大胆但谨慎:通过谨慎的积极协作ICCV 2023释放个性化联合学习的潜力
PFL-DA - 通过域适应的个性化联合学习,并使用分布式3D打印Technometrics 2023
其他PFL
FEDMTL(不是摩卡咖啡) - 联邦多任务学习神经2017
FEDBN - FEDBN:通过本地批发归一化ICLR 2021对非IID特征的联合学习
基于知识依据的PFL(更多在HTFLLIB中)
Feddistill(FD) - 沟通效率的机上机器学习:非IID私人数据2018下的联合蒸馏和增强
FML - 联邦共同学习2020
FEDKD - 通过知识蒸馏自然传播的沟通效率的联合学习2022
FEDPROTO - FEDPROTO:非均质客户的联合原型学习AAAI 2022
FEDPCL(带有预训练的模型) - 预先训练模型的联合学习:一种对比学习方法神经2022
FEDPAC - 具有功能一致性和分类器协作ICLR 2023的个性化联合学习
我们支持各种数据集的三种类型的方案,并将通用数据集拆分代码移动到./dataset/utils以便于扩展。如果您需要另一个数据集,只需编写另一个代码以下载它,然后使用utils。
对于标签偏斜方案,我们介绍了16个著名数据集:
数据集可以很容易地分为IID和非IID版本。在非IID方案中,我们区分两种类型的分布:
病理非IID :在这种情况下,每个客户端仅包含标签的一个子集,例如,即使整个数据集包含所有10个标签,MNIST数据集的10个标签中只有2个标签中只有2个。这导致跨客户的数据分布高度偏斜。
实际非IID :在这里,我们使用Dirichlet分布对数据分布进行建模,从而导致更现实,更不平衡的失衡。有关此的更多详细信息,请参阅本文。
此外,我们提供了一个balance选项,其中数据金额均匀分配到所有客户端。
对于特征偏移方案,我们在域适应中使用了3个广泛使用的数据集:
对于实际情况,我们介绍了5个自然分离的数据集:
有关物联网中数据集和FL算法的更多详细信息,请参阅FL-IOT。
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy 运行python generate_MNIST.py noniid - dir的命令行输出
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
对于MNIST和时尚狂热者
对于CIFAR10,CIFAR100和TININ-IMAGENET
对于ag_news和sogou_news
对于AmazonReview
对于全能
对于Har和Pamap
安装CUDA。
安装Conda最新并激活Conda。
有关其他配置,请参阅prepare.sh脚本。
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version 使用git下载此项目到适当的位置。
git clone https://github.com/TsingZ0/PFLlib.git创建适当的环境(请参阅环境)。
构建评估方案(请参阅数据集和方案(更新))。
运行评估:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN model注意:最好在使用新机器上使用任何算法之前调整算法特定的超参数。
该库旨在通过新算法和数据集易于扩展。这是您可以添加它们的方法:
新数据集:要添加一个新数据集,只需在./dataset中创建一个generate_DATA.py文件,然后编写下载代码并使用utils,如./dataset/generate_MNIST.py (您可以将其视为模板)中所示):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func新算法:要添加新算法,扩展了基于./system/flcore/servers/serverbase.py and ./system/flcore/clients/clientbase.py中定义的基类服务器和客户端。
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm新模型:要添加新模型,只需将其包含在./system/flcore/trainmodel/models.py中。
新优化器:如果您需要新的优化器进行培训,请将其添加到./system/flcore/optimizers/fedoptimizer.py中。
新的基准平台或库:我们的框架很灵活,允许用户为特定应用程序(例如FL-IOT和HTFLLIB)构建自定义平台或库。
您可以使用以下隐私评估方法来评估PFLLIB中TFL/PFL算法的隐私功能。请参阅./system/flcore/servers/serveravg.py 。请注意,这些评估中的大多数通常在原始论文中不考虑。我们鼓励您添加更多攻击和指标以进行隐私评估。
为了在实际条件下模拟联合学习(FL),例如客户辍学,较慢的培训器,缓慢的发送者和网络TTL(live) ,您可以调整以下参数:
-cdr :客户的辍学率。根据此速度,在每个培训回合中随机放弃客户。-tsr和-ssr :分别较慢的培训器和慢速发送方速率。这些参数定义了将以缓慢的培训器或缓慢发件人的行为行为的客户比例。一旦将客户端选为“慢培训师”或“慢速发送者”,它将始终如一地训练/发送速度较慢。-tth :毫秒中网络TTL的阈值。多亏了@stonesjtu,该库还可以为模型记录GPU内存使用量。
如果您对上述算法的实验结果感兴趣(例如准确性) ,则可以在我们接受的FL论文中找到结果,该论文也利用了此库。这些论文包括:
请注意,尽管这些结果基于此库,但重现确切的结果可能具有挑战性,因为某些设置可能会因社区反馈而改变。例如,在较早的版本中,我们将shuffle=False in clientbase.py中。
这是您的参考文档:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


