PFLlib
37 methods
Criamos uma biblioteca de algoritmo para iniciantes e uma plataforma de referência para aqueles novos no aprendizado federado. Junte -se a nós na expansão da comunidade FL, contribuindo com seus algoritmos, conjuntos de dados e métricas para este projeto.
? O Pfllib agora tem seu site oficial e nome de domínio: https: //www.pfllib.com/ !!!
? A tabela de classificação está ao vivo! Nossos métodos - FEDCP, GPFL e FEDDBE - lideram o caminho. Notavelmente, o Feddbe se destaca com um desempenho robusto em vários níveis de heterogeneidade de dados.
? Alteraremos a licença para o Apache-2.0 na próxima versão.
Foram adicionados quatro novos conjuntos de dados, dois dos quais abordam cenários do mundo real : (1) patches de tecido tumoral de metástases de câncer de mama em seções de linfonodo provenientes de diferentes hospitais e (2) fotos da vida selvagem capturadas por diferentes armadilhas da câmera . Os outros dois conjuntos de dados concentram-se no cenário de Staque de Labelas : Imagens de Raios-X de Tóia de Hospitais para Covid-19 e Imagens Endoscópicas de Hospitais para Detecção de Doenças Gastrointestinais. Esses conjuntos de dados também são compatíveis com o nosso htfllib
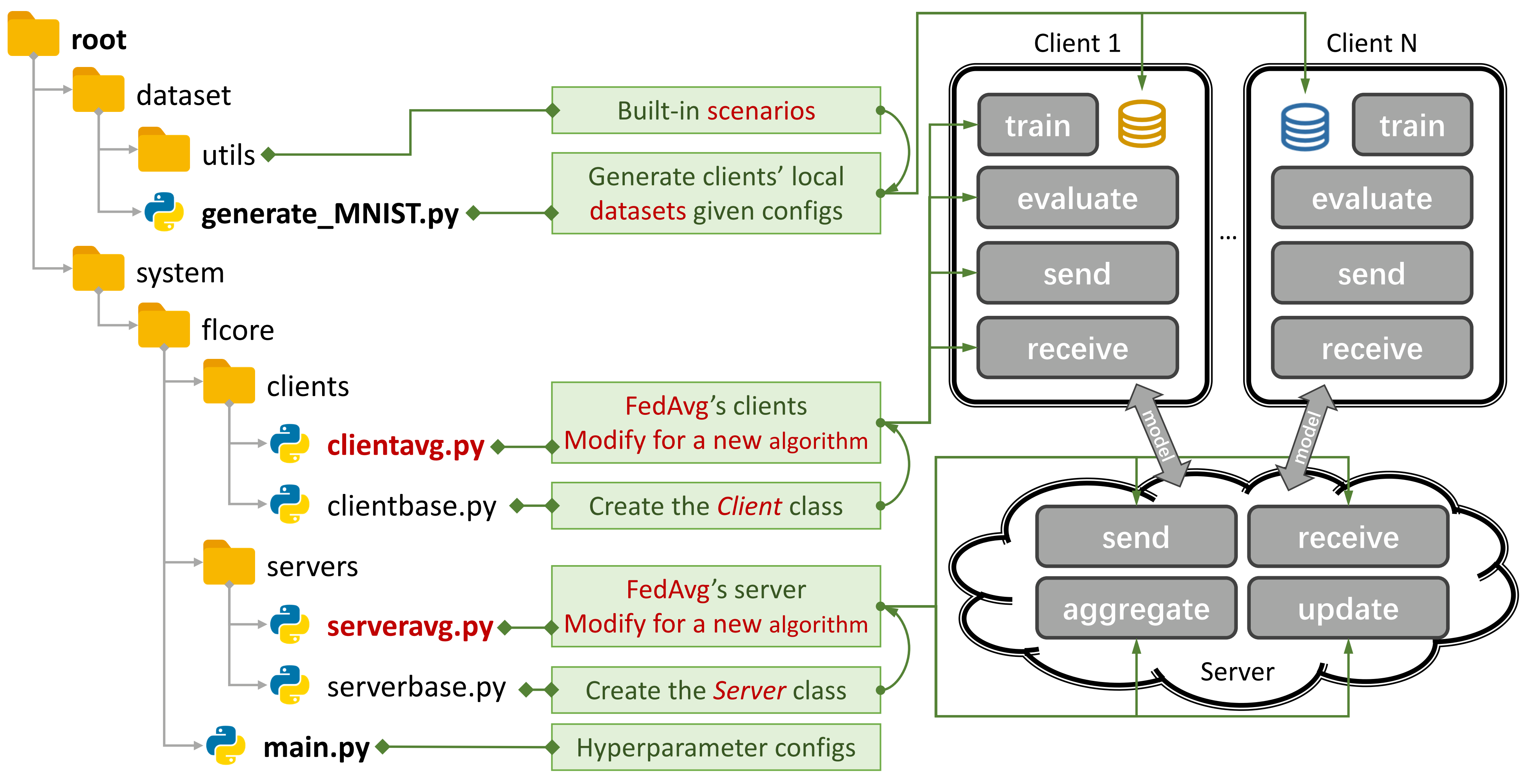 Figura 1: Um exemplo para o Fedavg. Você pode criar um cenário usando
Figura 1: Um exemplo para o Fedavg. Você pode criar um cenário usando generate_DATA.py e executar um algoritmo usando main.py , clientNAME.py e serverNAME.py . Para um novo algoritmo, você só precisa adicionar novos recursos em clientNAME.py e serverNAME.py .
Se você achar útil nosso repositório, cite o artigo correspondente:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 Algoritmos tradicionais de FL (TFL) e FL (PFL) personalizados, 3 cenários e 24 conjuntos de dados.
Alguns resultados experimentais estão avaliáveis em seu artigo e aqui.
Consulte este guia para aprender a usá -lo.
A plataforma de benchmark pode simular cenários usando a CNN de 4 camadas no CIFAR100 para 500 clientes em uma placa GPU NVIDIA GeForce RTX 3090 com apenas custo de memória GPU de 5,08 GB .
Fornecemos avaliação de privacidade e suprimento de pesquisa sistemática.
Agora você pode treinar alguns clientes e avaliar o desempenho em novos clientes, definindo args.num_new_clients em ./system/main.py . Observe que nem todos os algoritmos TFL/PFL suportam esse recurso.
O PFLLIB se concentra principalmente nos dados (estatísticos) heterogeneidade. Para algoritmos e uma plataforma de referência que aborda dados e heterogeneidade de modelos , consulte o nosso projeto estendido de aprendizado federado heterogêneo (HTFLLIB) .
À medida que nos esforçamos para atender às diversas demandas do usuário, atualizações frequentes do projeto podem alterar as configurações padrão e os códigos de criação de cenários, afetando os resultados experimentais.
Problemas fechados podem ajudá -lo muito quando surgirem erros.
Ao enviar solicitações de puxar, forneça instruções e exemplos suficientes na caixa de comentários.
A origem do fenômeno de heterogeneidade de dados são as características dos usuários, que geram dados não IID (não independentes e distribuídos idênticos) e desequilibrados. Com a heterogeneidade de dados existindo no cenário FL, uma infinidade de abordagens foi proposta para quebrar essa porca dura. Por outro lado, a FL personalizada (PFL) pode aproveitar os dados estatisticamente heterogêneos para aprender o modelo personalizado para cada usuário.
FL tradicional (TFL)
Tfl básico
Fedavg -aprendizado com eficiência de comunicação de redes profundas a partir de dados descentralizados Aistats 2017
TFL baseado em correção de atualização
Andaimes - andaime: Média estocástica controlada para aprendizado federado ICML 2020
TFL baseada em regularização
FedProx - otimização federada em redes heterogêneas MLSYS 2020
Feddyn - Aprendizagem federada com base na regularização dinâmica ICLR 2021
TFL baseado em modelo
Lua -Aprendizagem federada contrastiva de modelo CVPR 2021
Fedlc - Aprendizagem federada com distribuição de etiquetas Skew via logits calibração ICML 2022
TFL baseado em distribuição de conhecimento
Fedgen -Destilação de conhecimento sem dados para aprendizado federado heterogêneo ICML 2021
Fedntd -Preservação do Conhecimento Global por destilação não verdadeira em Federated Learning Neurips 2022
FL personalizado (PFL)
PFL baseado em meta-aprendizagem
PER-FEDAVG -Aprendizagem federada personalizada com garantias teóricas: uma abordagem de meta-aprendizagem de modelo-agnóstico Neurips 2020
PFL baseada em regularização
PFEDME - Aprendizagem federada personalizada com Moreau envelopes Neurips 2020
Idem - Idem: Aprendizagem federada justa e robusta através da personalização ICML 2021
PFL baseado em agregação personalizada
APFL - Aprendizagem federada personalizada adaptativa 2020
FedFomo - Aprendizagem federada personalizada com otimização de modelo de primeira ordem ICLR 2021
Fedamp -Aprendizagem federada personalizada do Silo Cross-Silo em dados não IID AAAI 2021
FedPhp - FedPhp: Personalização federada com modelos privados herdados ECML PKDD 2021
Apple -Adapte-se à adaptação: Aprendendo a personalização para o aprendizado federado de cross-silo ijcai 2022
Fedala - Fedala: agregação local adaptável para aprendizado federado personalizado AAAI 2023
PFL baseado em modelo
FedPer - Aprendizagem Federada com Camadas de Personalização 2019
LG-FEDAVG -Pense localmente, age globalmente: aprendizado federado com representações locais e globais 2020
Fedrep - Explorando representações compartilhadas para aprendizado federado personalizado ICML 2021
Fedrod - Em ponte de aprendizado federado genérico e personalizado para classificação de imagem ICLR 2022
FedBabu - FedBabu: Rumo à representação aprimorada para classificação de imagem federada ICLR 2022
FEDGC - Aprendizagem federada para reconhecimento de rosto com correção de gradiente AAAI 2022
FEDCP - FEDCP: separando as informações do recurso para aprendizado federado personalizado por meio da política condicional KDD 2023
GPFL - GPFL: Aprendendo simultaneamente informações genéricas e personalizadas de recursos para aprendizado federado personalizado ICCV 2023
Fedgh - Fedgh: aprendizado federado heterogêneo com cabeçalho global generalizado ACM MM 2023
FeddBE - Eliminando o viés do domínio para aprendizado federado no espaço de representação Neurips 2023
FedCac - ousado, mas cauteloso: desbloqueando o potencial da aprendizagem federada personalizada por meio de colaboração cautelosamente agressiva ICCV 2023
PFL-DA -Aprendizagem federada personalizada via adaptação de domínio com um aplicativo para distribuído Technometrics de impressão 3D distribuído 2023
Outro Pfl
Fedmtl (não Mocha) -Federated Multi-Task Learning Neurips 2017
FedBN -FedBN: Federated Learning sobre recursos não IID via normalização em lote local ICLR 2021
PFL baseado em distribuição de conhecimento (mais em htfllib)
Feddistill (FD) -Aprendizagem de máquina com desenvolvimento de comunicação no dispositivo: destilação federada e aumento sob dados privados não IID 2018
FML - Aprendizagem mútua federada 2020
Fedkd -Aprendizagem federada com eficiência de comunicação através da Nature Communications 2022
FedProto - FedProto: Federated Prototype Learning em clientes heterogêneos AAAI 2022
Fedpcl (modelos pré-treinados) -Aprendizagem federada com modelos pré-treinados: uma abordagem de aprendizado contrastiva Neurips 2022
FedPac - Aprendizagem federada personalizada com alinhamento de recursos e colaboração de classificadores ICLR 2023
Suportamos 3 tipos de cenários com vários conjuntos de dados e movimentamos o código de divisão de conjunto de dados comum para ./dataset/utils para facilitar a extensão. Se você precisar de outro conjunto de dados, basta escrever outro código para fazer o download e usar os utils.
Para o cenário da gravadora , apresentamos 16 conjuntos de dados famosos:
Os conjuntos de dados podem ser facilmente divididos em versões IID e não IID . No cenário não IID , distinguimos entre dois tipos de distribuição:
Não-IID patológico : nesse caso, cada cliente mantém apenas um subconjunto dos rótulos, por exemplo, apenas 2 em cada 10 rótulos do conjunto de dados MNIST, mesmo que o conjunto de dados geral contenha todos os 10 rótulos. Isso leva a uma distribuição altamente distorcida de dados entre clientes.
PRÁTICO NÃO IID : Aqui, modelamos a distribuição de dados usando uma distribuição de Dirichlet, o que resulta em um desequilíbrio mais realista e menos extremo. Para mais detalhes sobre isso, consulte este artigo.
Além disso, oferecemos uma opção balance , onde o valor dos dados é distribuído uniformemente em todos os clientes.
Para o cenário de mudança de recurso , utilizamos 3 conjuntos de dados amplamente utilizados na adaptação de domínio:
Para o cenário do mundo real , apresentamos 5 conjuntos de dados separados naturalmente:
Para obter mais detalhes sobre conjuntos de dados e algoritmos FL na IoT , consulte o FL-IoT.
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy A linha de comando em execução python generate_MNIST.py noniid - dir
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
para mnist e moda-mnist
Para Cifar10, Cifar100 e Minium-Imagenet
para ag_news e SOGOU_NEWS
para AmazonReview
para omniglot
Para Har e Pamap
Instale o CUDA.
Instale o CONDA mais recente e ative o CONA.
Para configurações adicionais, consulte o script prepare.sh .
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version Faça o download deste projeto para um local apropriado usando o Git.
git clone https://github.com/TsingZ0/PFLlib.gitCrie ambientes adequados (consulte Ambientes).
Construa cenários de avaliação (consulte conjuntos de dados e cenários (atualização)).
Executar avaliação:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN modelNota : É preferível ajustar hiper-parâmetros específicos do algoritmo antes de usar qualquer algoritmo em uma nova máquina.
Esta biblioteca foi projetada para ser facilmente extensível com novos algoritmos e conjuntos de dados. Veja como você pode adicioná -los:
Novo conjunto de dados : para adicionar um novo conjunto de dados, basta criar um arquivo generate_DATA.py em ./dataset e depois escrever o código de download e usar os utilitários como mostrado em ./dataset/generate_MNIST.py (você pode considerá -lo como um modelo):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func Novo algoritmo : para adicionar um novo algoritmo, estenda o servidor e o cliente da Base Classes, que são definidos em ./system/flcore/servers/serverbase.py e ./system/flcore/clients/clientbase.py , respectivamente.
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm Novo modelo : para adicionar um novo modelo, basta incluí -lo em ./system/flcore/trainmodel/models.py .
Novo otimizador : se você precisar de um novo otimizador para treinamento, adicione -o a ./system/flcore/optimizers/fedoptimizer.py .
Nova plataforma ou biblioteca de benchmark : nossa estrutura é flexível, permitindo que os usuários criem plataformas ou bibliotecas personalizadas para aplicativos específicos, como FL-IoT e HTFLLIB.
Você pode usar os seguintes métodos de avaliação de privacidade para avaliar os recursos de preservação de privacidade dos algoritmos TFL/PFL no PFLLIB. Consulte ./system/flcore/servers/serveravg.py para um exemplo. Observe que a maioria dessas avaliações normalmente não é considerada nos documentos originais. Incentivamos você a adicionar mais ataques e métricas para avaliação da privacidade.
Para simular a aprendizagem federada (FL) em condições práticas, como abandono do cliente , treinadores lentos , remetentes lentos e TTL de rede (tempo de vida) , você pode ajustar os seguintes parâmetros:
-cdr : Taxa de abandono para clientes. Os clientes são descartados aleatoriamente em cada rodada de treinamento com base nessa taxa.-tsr e -ssr : Treinador lento e taxas de remetente lento, respectivamente. Esses parâmetros definem a proporção de clientes que se comportarão como treinadores lentos ou remetentes lentos. Depois que um cliente é selecionado como um "treinador lento" ou "remetente lento", ele treinará/enviará de forma mais lenta do que outros clientes.-tth : limiar para a rede TTL em milissegundos.Graças a @stonesjtu, esta biblioteca também pode gravar o uso da memória da GPU para o modelo.
Se você estiver interessado em resultados experimentais (por exemplo, precisão) para os algoritmos mencionados acima, poderá encontrar resultados em nossos trabalhos de FL aceitos, que também utilizam esta biblioteca. Esses documentos incluem:
Observe que, embora esses resultados tenham sido baseados nessa biblioteca, a reprodução dos resultados exatos pode ser desafiadora, pois algumas configurações podem ter mudado em resposta ao feedback da comunidade. Por exemplo, em versões anteriores, definimos shuffle=False no clientbase.py .
Aqui estão os documentos relevantes para sua referência:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


