PFLlib
37 methods
初心者向けのアルゴリズムライブラリとベンチマークプラットフォームを作成し、新しい対連邦学習のためのベンチマークプラットフォームを作成します。このプロジェクトにアルゴリズム、データセット、メトリックを貢献して、FLコミュニティを拡大してください。
? PFLLIBには公式Webサイトとドメイン名があります:https://www.pfllib.com/ !!!
?リーダーボードはライブです!私たちの方法(FEDCP、GPFL、およびFEDDBE)が道を導きます。特に、FEDDBEは、さまざまなデータの不均一性レベルにわたって堅牢なパフォーマンスで際立っています。
?次のリリースでライセンスをApache-2.0に変更します。
4つの新しいデータセットが追加されており、そのうち2つは実際のシナリオに対処しています。(1)さまざまな病院から供給されたリンパ節セクションの乳がん転移からの腫瘍組織パッチと(2)異なるカメラトラップで撮影された野生生物の写真。他の2つのデータセットは、ラベル皮を皮を剥ぐシナリオに焦点を当てています。病院の胸部X線画像は、Covid-19のための胸部X線画像と、胃腸疾患検出のための病院の内視鏡画像です。これらのデータセットは、htfllibとも互換性があります
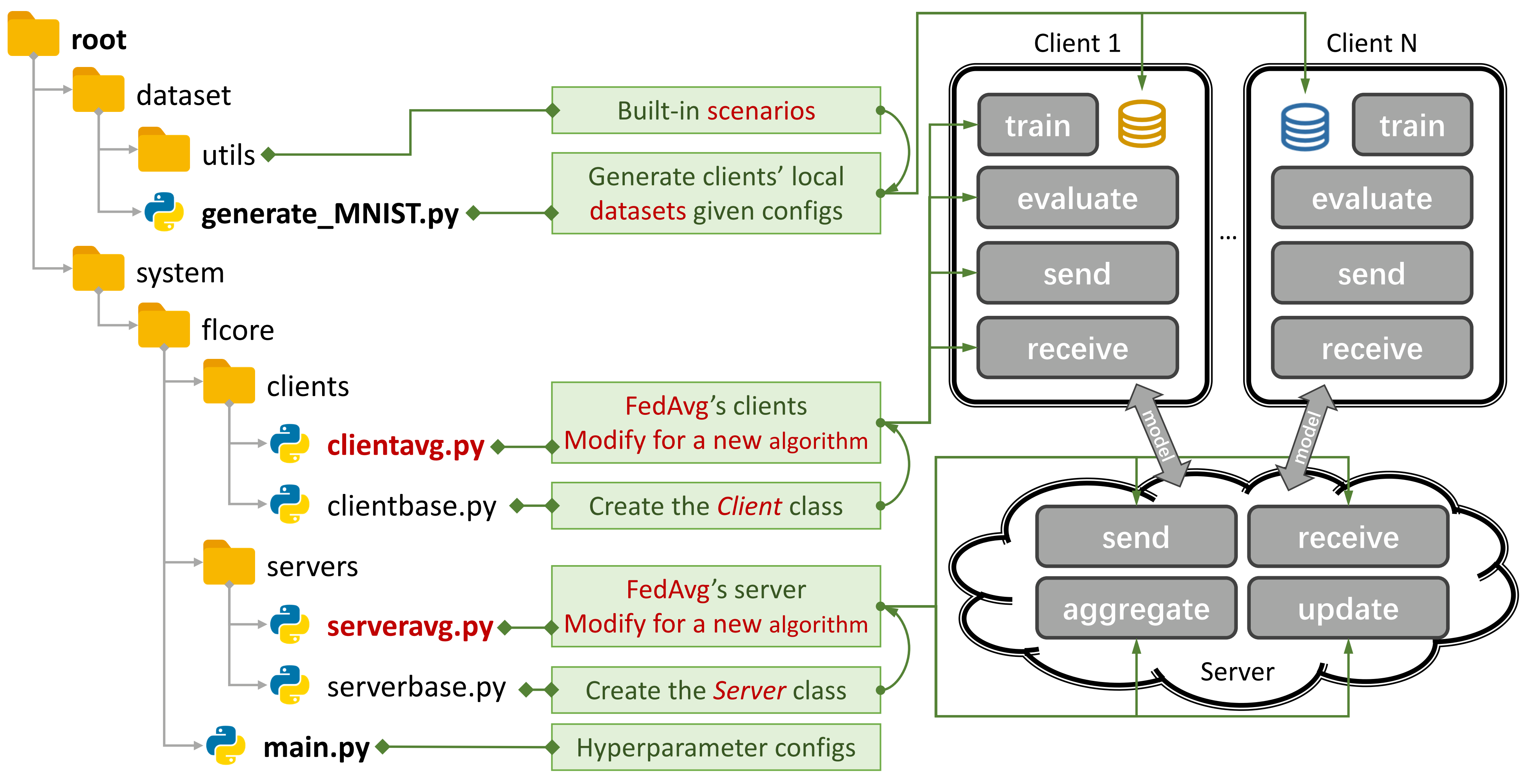 図1:FEDAVGの例。
図1:FEDAVGの例。 generate_DATA.pyを使用してシナリオを作成し、 main.py 、 clientNAME.py 、およびserverNAME.pyを使用してアルゴリズムを実行できます。新しいアルゴリズムの場合、 clientNAME.pyおよびserverNAME.pyに新しい機能を追加する必要があります。
リポジトリが便利だと思う場合は、対応する論文を引用してください。
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37従来のFL(TFL)およびパーソナライズされたFL(PFL)アルゴリズム、3つのシナリオ、および24のデータセット。
いくつかの実験結果は、その論文ではここで利用できます。
このガイドを参照して、使用方法を学びます。
ベンチマークプラットフォームは、 500のクライアント用のCIFAR100の4層CNNを使用してシナリオをシミュレートできます。
プライバシー評価と系統的研究サプロートを提供しています。
一部のクライアントでトレーニングし、 args.num_new_clientsの./system/main.pyを設定して、新しいクライアントのパフォーマンスを評価できます。すべてのTFL/PFLアルゴリズムがこの機能をサポートしているわけではないことに注意してください。
Pfllibは主にデータ(統計)不均一性に焦点を当てています。データとモデルの不均一性の両方に対処するアルゴリズムとベンチマークプラットフォームについては、拡張されたプロジェクトの不均一なフェデレート学習(HTFLLIB)を参照してください。
多様なユーザーの需要を満たすよう努めているため、プロジェクトの頻繁な更新により、デフォルト設定とシナリオ作成コードが変更され、実験結果に影響を与える可能性があります。
閉じた問題は、エラーが発生したときに大いに役立つ場合があります。
プルリクエストを送信するときは、コメントボックスに十分な指示と例を提供してください。
データの不均一性現象の起源は、非IID(独立していない、同一に分布していない)と不均衡なデータを生成するユーザーの特性です。 FLシナリオにデータの不均一性が存在するため、この硬いナットをクラックするために無数のアプローチが提案されています。対照的に、パーソナライズされたFL(PFL)は、統計的に不均一なデータを利用して、各ユーザーのパーソナライズされたモデルを学習できます。
伝統的なFL(TFL)
基本的なTFL
FEDAVG - 分散データAistats 2017からのディープネットワークのコミュニケーション効率の高い学習
更新補正ベースのTFL
足場- 足場:連合学習ICML 2020の確率制御平均化
正規化ベースのTFL
FedProx - 不均一なネットワークMLSYS 2020におけるフェデレーション最適化
Feddyn - 動的正規化ICLR 2021に基づくフェデレーションラーニング
モデル分解ベースのTFL
月- モデル制御のフェデレーション学習CVPR 2021
FEDLC - ロジッツキャリブレーションICML 2022を介したラベル配布のレーベル分布の連合学習
知識駆動ベースのTFL
FEDGEN - 不均一なフェデレーション学習ICML 2021のためのデータなしの知識蒸留
FEDNTD - 連邦学習ニューリップス2022における非真実の蒸留によるグローバルな知識の保存
パーソナライズされたFL(PFL)
メタ学習ベースのPFL
フェダブごと- 理論的保証を伴うパーソナライズされたフェデレーション学習:モデルに依存しないメタラーニングアプローチニューリップ2020
正規化ベースのPFL
PFEDME - モローエンベロープニューリップス2020を使用したパーソナライズされたフェデレーションラーニング
同上- 同上:パーソナライズを通じて公正で堅牢な連邦学習ICML 2021
パーソナライズされた凝集ベースのPFL
APFL - 適応性のあるパーソナライズされたフェデレーションラーニング2020
FEDFOMO - 一次モデル最適化ICLR 2021を使用したパーソナライズされたフェデレーションラーニング
FEDAMP - 非IIDデータに関するパーソナライズされたクロスシロフェデレーションラーニングAAAI 2021
FEDPHP - FEDPHP:継承されたプライベートモデルECML PKDD 2021を使用したフェデレーションパーソナライゼーション
Apple - 適応への適応:クロスシロフェデレーション学習IJCAI 2022の学習パーソナライズ
Fedala - Fedala:パーソナライズされた連邦学習のための適応局所集約AAAI 2023
モデル分解ベースのPFL
FEDPER - パーソナライズレイヤー2019を使用したフェデレーションラーニング
LG-fedavg - ローカルで考え、グローバルに行動する:ローカルおよびグローバルな表現での連合学習2020
FEDREP - パーソナライズされたフェデレーション学習ICML 2021の共有表現を利用する
FedRod - 画像分類のための一般的でパーソナライズされたフェデレーション学習を埋めることについてICLR 2022
Fedbabu - Fedbabu:Federated Image分類ICLR 2022の拡張表現に向けて
FEDGC - グラデーション補正による顔認識のためのフェデレーションラーニングAAAI 2022
FEDCP - FEDCP:条件付きポリシーKDD 2023を介したパーソナライズされたフェデレーション学習の機能情報の分離
GPFL - GPFL:同時に、パーソナライズされたフェデレーション学習のための一般的でパーソナライズされた機能情報を学習するICCV 2023
Fedgh - Fedgh:一般化されたグローバルヘッダーACM MM 2023を使用した不均一な連邦学習
FEDDBE - 表現スペースニューリップス2023におけるフェデレーション学習のドメインバイアスを排除する
FEDCAC - 大胆だが慎重:慎重に積極的なコラボレーションICCV 2023を通じてパーソナライズされた連合学習の可能性を解き放つ
PFL-DA - 分散3D印刷テクノメトリクスへのアプリケーションを使用したドメイン適応によるパーソナライズされたフェデレーション学習2023
他のPFL
FEDMTL(モカではない) - フェデレーションマルチタスク学習ニューリップ2017
FEDBN - FEDBN:ローカルバッチ正規化ICLR 2021を介した非IID機能に関するフェデレーションラーニング
知識駆動ベースのPFL(htfllibの詳細)
FEDDISTILL(FD) - コミュニケーション効率の良い機械学習:非IIDプライベートデータの下でのフェデレーション蒸留と増強2018
FML - フェデレーションミューチュアルラーニング2020
FEDKD - 知識蒸留自然コミュニケーションによるコミュニケーション効率の高いフェデレーション学習2022
FedProto - FedProto:異質なクライアントを介したフェデレーションプロトタイプ学習AAAI 2022
FEDPCL(事前に訓練されたモデルw/o) - 事前に訓練されたモデルからのフェデレーション学習:対照的な学習アプローチニューリップ2022
FEDPAC - 機能アライメントと分類器コラボレーションICLR 2023を備えたパーソナライズされたフェデレーションラーニング
さまざまなデータセットを使用して3種類のシナリオをサポートし、Common DataSetの分割コードを./dataset/utilsに移動して簡単に拡張します。別のデータセットが必要な場合は、それをダウンロードするために別のコードを記述して、utilsを使用してください。
ラベルのスキューシナリオについては、 16の有名なデータセットを紹介します。
データセットは、 IIDおよび非IIDバージョンに簡単に分割できます。非IIDシナリオでは、2種類の分布を区別します。
病理学的非IID :この場合、各クライアントはラベルのサブセットのみを保持しています。たとえば、データセット全体に10個のラベルがすべて含まれていても、MNISTデータセットの10個のラベルのうち2個のみです。これにより、クライアント全体でデータの非常に歪んだ分布が発生します。
実用的な非IID :ここでは、Dirichlet Distributionを使用してデータ分布をモデル化します。その結果、より現実的で極端な不均衡が発生します。この詳細については、このペーパーを参照してください。
さらに、データ量がすべてのクライアントに均等に分散されるbalanceオプションを提供します。
機能シフトシナリオでは、ドメイン適応で3つの広く使用されているデータセットを利用します。
実際のシナリオについては、 5つの自然に分離されたデータセットを紹介します。
IoTのデータセットとFLアルゴリズムの詳細については、FL-OITを参照してください。
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy 実行中のpython generate_MNIST.py noniid - dirのコマンドライン出力
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
ミストとファッションミストのために
CIFAR10、CIFAR100、およびTiny-Imagenetの場合
AG_NEWSとSOGOU_NEWSの場合
AmazonReview用
Omniglot用
HARとPAMAPの場合
cudaをインストールします。
コンドラを最新インストールし、コンドラをアクティブにします。
追加の構成については、 prepare.shスクリプトを参照してください。
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version このプロジェクトをGITを使用して適切な場所にダウンロードしてください。
git clone https://github.com/TsingZ0/PFLlib.git適切な環境を作成します(環境を参照)。
評価シナリオをビルドします(データセットとシナリオ(更新)を参照)。
評価を実行:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN model注:新しいマシンでアルゴリズムを使用する前に、アルゴリズム固有のハイパーパラメーターを調整することが望ましいです。
このライブラリは、新しいアルゴリズムとデータセットで簡単に拡張できるように設計されています。これらを追加する方法は次のとおりです。
新しいデータセット:新しいデータセットを追加するには、 ./dataset datasetにgenerate_DATA.pyファイルを作成してから、ダウンロードコードを作成し、 ./dataset/generate_MNIST.py generate_mnist.pyに示すようにutilsを使用します(テンプレートとして考慮することができます):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func新しいアルゴリズム:新しいアルゴリズムを追加するには、 ./system/flcore/servers/serverbase.py flcore/servers/serverbase.pyおよび./system/flcore/clients/clientbase.pyで定義されているベースクラスサーバーとクライアントを拡張します。
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm新しいモデル:新しいモデルを追加するには、 ./system/flcore/trainmodel/models.py flcore/trainmodel/models.pyにそれを含めるだけです。
新しいオプティマイザー:トレーニングに新しいオプティマイザーが必要な場合は、 ./system/flcore/optimizers/fedoptimizer.py /flcore/optimizers/fedoptimizer.pyに追加します。
新しいベンチマークプラットフォームまたはライブラリ:当社のフレームワークは柔軟であり、ユーザーはFL-IOTやHTFLLIBなどの特定のアプリケーション用のカスタムプラットフォームまたはライブラリを構築できます。
次のプライバシー評価方法を使用して、PFLLIBのTFL/PFLアルゴリズムのプライバシー提供機能を評価できます。例については./system/flcore/servers/serveravg.py flcore/servers/serveravg.pyを参照してください。これらの評価のほとんどは、通常、元の論文では考慮されていないことに注意してください。プライバシー評価のために、さらに攻撃とメトリックを追加することをお勧めします。
クライアントのドロップアウト、スロートレーナー、遅い送信者、ネットワークTTL(時間までの時間)などの実際の条件の下でフェデレートラーニング(FL)をシミュレートするには、次のパラメーターを調整できます。
-cdr :クライアントのドロップアウト率。クライアントは、このレートに基づいて各トレーニングラウンドでランダムに削除されます。-tsrおよび-ssr :それぞれ遅いトレーナーと遅い送信者レート。これらのパラメーターは、遅いトレーナーまたは遅い送信者として動作するクライアントの割合を定義します。クライアントが「スロートレーナー」または「遅い送信者」として選択されると、他のクライアントよりも一貫して訓練/送信されます。-tth :ミリ秒単位でのネットワークTTLのしきい値。@StonesJTUのおかげで、このライブラリはモデルのGPUメモリ使用量を記録することもできます。
上記のアルゴリズムの実験結果(たとえば、精度)に興味がある場合は、このライブラリを利用する受け入れられているFLペーパーで結果を見つけることができます。これらの論文には次のものが含まれます。
これらの結果はこのライブラリに基づいていますが、コミュニティのフィードバックに応じて一部の設定が変更された可能性があるため、正確な結果を再現することは困難な場合があります。たとえば、以前のバージョンでは、 clientbase.pyでshuffle=Falseを設定します。
参照の関連書類は次のとおりです。
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


