PFLlib
37 methods
Мы создаем удобную для начинающих библиотеку алгоритмов и эталонная платформа для новичков для федеративного обучения. Присоединяйтесь к нам в расширении сообщества FL, внесли свой вклад в ваши алгоритмы, наборы данных и показатели этого проекта.
? У Pfllib теперь есть официальный сайт и доменное имя: https: //www.pfllib.com/ !!!
? Таблица лидеров живет! Наши методы - FEDCP, GPFL и Feddbe - протянулись. Примечательно, что FedDbe выделяется с высокой производительностью в разных уровнях гетерогенности данных.
? Мы изменим лицензию на Apache-2.0 в следующем выпуске.
Были добавлены четыре новых набора данных, два из которых касаются реальных сценариев: (1) Пласти опухолевой ткани из метастазов рака молочной железы в секциях лимфатических узлов, полученных из разных больниц , и (2) фотографии дикой природы, сделанные различными ловушками камеры . Два других набора данных сосредоточены на сценарии наклейка на этикетке : рентгеновские изображения грудной клетки из больниц для COVID-19 и эндоскопических изображений из больниц для обнаружения желудочно-кишечных заболеваний. Эти наборы данных также совместимы с нашими htfllib
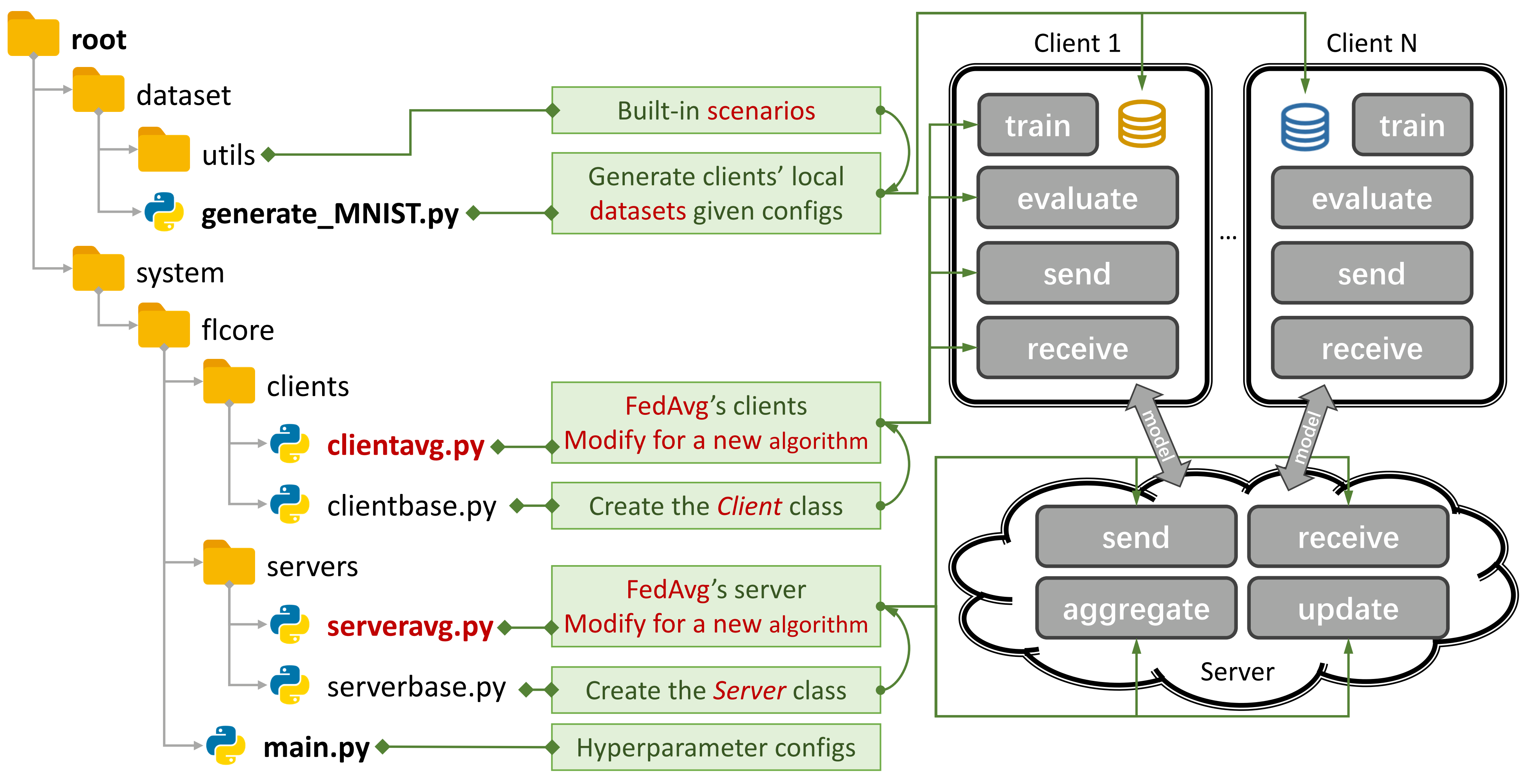 Рисунок 1: Пример для Fedavg. Вы можете создать сценарий, используя
Рисунок 1: Пример для Fedavg. Вы можете создать сценарий, используя generate_DATA.py и запустить алгоритм с помощью main.py , clientNAME.py и serverNAME.py . Для нового алгоритма вам нужно только добавить новые функции в clientNAME.py и serverNAME.py .
Если вы найдете наш репозиторий полезным, пожалуйста, цитируйте соответствующую статью:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 Традиционные FL (TFL) и персонализированные алгоритмы FL (PFL), 3 сценария и 24 наборы данных.
Некоторые экспериментальные результаты доступны в его бумаге и здесь.
Обратитесь к этому руководству, чтобы узнать, как его использовать.
Платформа Benchmark может имитировать сценарии, используя 4-слойную CNN на CIFAR100 для 500 клиентов на одной карте GPU NVIDIA GEFORCE RTX 3090 с стоимостью памяти 5,08 ГБ .
Мы предоставляем оценку конфиденциальности и систематические исследования.
Теперь вы можете тренироваться с некоторыми клиентами и оценить производительность на новых клиентах, установив args.num_new_clients в ./system/main.py . Обратите внимание, что не все алгоритмы TFL/PFL поддерживают эту функцию.
Pfllib в первую очередь фокусируется на гетерогенности данных (статистической). Для алгоритмов и эталонной платформы, которая рассматривает как данные, так и гетерогенность модели , обратитесь к нашему расширенному гетерогенному федеративному обучению (HTFLLIB) .
Поскольку мы стремимся удовлетворить разнообразные пользовательские требования, частые обновления проекта могут изменить настройки по умолчанию и коды создания сценариев, влияя на экспериментальные результаты.
Закрытые проблемы могут вам очень помочь, когда возникают ошибки.
При отправке запросов на привлечение укажите достаточные инструкции и примеры в поле для комментариев.
Происхождение явления гетерогенности данных -это характеристики пользователей, которые генерируют не IID (не независимые и идентично распределенные) и несбалансированные данные. С неоднородностью данных, существующими в сценарии FL, было предложено множество подходов, чтобы взломать этот жесткий орех. Напротив, персонализированный FL (PFL) может воспользоваться статистически неоднородными данными, чтобы изучить персонализированную модель для каждого пользователя.
Традиционный FL (TFL)
Базовый TFL
Fedavg -Коммуникационное изучение глубоких сетей из децентрализованных данных Aistats 2017
Основанный на обновлении TFL
Скафолд - Скасто: Стохастическое управляемое усреднение для федеративного обучения ICML 2020
Основанный на регуляризации TFL
FedProx - Федеративная оптимизация в гетерогенных сетях MLSYS 2020
Feddyn - Федеративное обучение на основе динамической регуляризации ICLR 2021
На основе модели TFL
Луна -модель-контрастирование федеративного обучения CVPR 2021
FEDLC - Федеративное обучение с перекосом распределения ярлыков через калибровку Logits ICML 2022
Основанный на знаниях TFL
FedGen -Data Free Knowleding Distillation для гетерогенного федеративного обучения ICML 2021
Fedntd -Сохранение глобальных знаний нереализованной дистилляцией в федеративном обучении Neurips 2022
Персонализированный FL (PFL)
Мета-обучение на основе PFL
PER-FEDAVG -персонализированное федеративное обучение с теоретическими гарантиями: модель-агроновый подход мета-обучения Neurips 2020
PFL на основе регуляризации
PFEDME - персонализированное федеративное обучение с Moreau Covertes Neurips 2020
То же самое - то же самое: справедливое и надежное федеративное обучение через персонализацию ICML 2021
PFL на основе персонализированной агрегации
APFL - адаптивное персонализированное федеративное обучение 2020
FedFomo - персонализированное федеративное обучение с оптимизацией модели первого порядка ICLR 2021
Fedamp -персонализированное межселостное федеративное обучение по данным, не связанным с IID AAAI 2021
FEDPHP - FEDPHP: Федеративная персонализация с унаследованными частными моделями ECML PKDD 2021
Apple -адаптироваться к адаптации: персонализация обучения для межселостного федерального обучения IJCAI 2022
Федерала - Федерала: адаптивная местная агрегация для персонализированного федеративного обучения AAAI 2023
На основе модели PFL
Fedper - Федеративное обучение с уровнями персонализации 2019
LG-FEDAVG -Подумайте о местном уровне, действуйте во всем мире: Федеративное обучение с местными и глобальными представлениями 2020
FedRep - Используя общие представления для персонализированного федеративного обучения ICML 2021
Fedrod - о преодолении общего и персонализированного федеративного обучения для классификации изображений ICLR 2022
Fedbabu - Fedbabu: к расширенному представлению для классификации федеративных изображений ICLR 2022
FedGC - Федеративное обучение для распознавания лица с коррекцией градиента AAAI 2022
FEDCP - FEDCP: разделение информации о функциях для персонализированного федеративного обучения с помощью условной политики KDD 2023
GPFL - GPFL: одновременно изучение общей и персонализированной информации о функциях для персонализированного федеративного обучения ICCV 2023
Федг - Федг: гетерогенное федеративное обучение с обобщенным глобальным заголовком ACM MM 2023
Feddbe - Устранение предвзятости домена для федеративного обучения в репрезентативных Space Neurips 2023
FedCac - смелый, но осторожный: раскрытие потенциала персонализированного федеративного обучения через осторожно агрессивное сотрудничество ICCV 2023
PFL-DA -Персонализированное федеративное обучение с помощью адаптации домена с приложением к распределенной 3D-печати Technometrics 2023
Другое PFL
Fedmtl (не мокко) -федеративное многозадачное обучение Neurips 2017
FedBN -FedBN: Федеративное обучение по функциям, не имеющим IID, через локальную нормализацию партии ICLR 2021
На основе знаний PFL (подробнее в HTFLLIB)
FedDistill (FD) -Эффективное общение машинное обучение: федеративная дистилляция и увеличение в соответствии с не-IID частными данными 2018
FML - Федеративное взаимное обучение 2020
FedKD -Коммуникационное федеративное обучение с помощью знаний дистилляции природы 2022
FedProto - FedProto: Federated Prototype Learning для гетерогенных клиентов AAAI 2022
FEDPCL (без обученных моделей) -Федеративное обучение на предварительно обученных моделях: контрастный подход к обучению Neurips 2022
FedPac - персонализированное федеративное обучение с выравниванием функций и сотрудничество Classifier ICLR 2023
Мы поддерживаем 3 типа сценариев с различными наборами данных и перемещаем общий код расщепления наборов данных в ./dataset/utils для легкого расширения. Если вам нужен другой набор данных, просто напишите другой код, чтобы загрузить его, а затем использовать UTIL.
Для сценария перекоса на лейбле мы представляем 16 известных наборов данных:
Наборы данных могут быть легко разделены на IID и невозможные версии. В сценарии , не связанном с IID , мы различаем два типа распределения:
Патологический не-IID : в этом случае каждый клиент содержит только подмножество метков, например, всего 2 из 10 метков, из набора данных MNIST, даже если общий набор данных содержит все 10 метки. Это приводит к сильно искаженному распределению данных по клиентам.
Практическая не-IID : здесь мы моделируем распределение данных с использованием дирихлета, что приводит к более реалистичному и менее экстремальному дисбалансу. Для получения более подробной информации об этом обратитесь к этой статье.
Кроме того, мы предлагаем вариант balance , где сумма данных равномерно распределена по всем клиентам.
Для сценария сдвига функций мы используем 3 широко используемых наборов данных в адаптации домена:
Для реального сценария мы представляем 5 естественных наборов данных:
Для получения более подробной информации о наборах данных и алгоритмах FL в IoT , пожалуйста, обратитесь к FL-IOT.
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy Вывод командной строки запуска python generate_MNIST.py noniid - dir
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
для Mnist и Fashion-Mnist
для Cifar10, Cifar100 и Tiny-Imagenet
для ag_news и sogou_news
Для AmazonReview
для Omniglot
для Хар и Памапа
Установите CUDA.
Установите Conda Laster и активируйте Conda.
Для получения дополнительных конфигураций см. Сценарий prepare.sh .
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version Загрузите этот проект в подходящее место с помощью GIT.
git clone https://github.com/TsingZ0/PFLlib.gitСоздайте правильные среды (см. Среды).
Сценарии оценки сборки (см. Наборы данных и сценарии (обновление)).
Оценка запуска:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN modelПримечание : предпочтительнее настроить алгоритм-специфические гиперпараметры, прежде чем использовать любой алгоритм на новой машине.
Эта библиотека разработана так, чтобы легко расширяться с помощью новых алгоритмов и наборов данных. Вот как вы можете добавить их:
Новый набор данных : чтобы добавить новый набор данных, просто создайте файл generate_DATA.py в ./dataset , а затем напишите код загрузки и используйте уты, как показано в ./dataset/generate_MNIST.py (вы можете рассматривать его как шаблон):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func Новый алгоритм : чтобы добавить новый алгоритм, расширить сервер и клиент базовых классов, которые определены в ./system/flcore/servers/serverbase.py и ./system/flcore/clients/clientbase.py , соответственно.
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm Новая модель : чтобы добавить новую модель, просто включите ее в ./system/flcore/trainmodel/models.py .
Новый оптимизатор : если вам нужен новый оптимизатор для обучения, добавьте его в ./system/flcore/optimizers/fedoptimizer.py .
Новая эталонная платформа или библиотека : наша структура является гибкой, что позволяет пользователям создавать пользовательские платформы или библиотеки для конкретных приложений, таких как FL-IOT и HTFLLIB.
Вы можете использовать следующие методы оценки конфиденциальности для оценки возможностей конфиденциальности алгоритмов TFL/PFL в pfllib. Пожалуйста, см ./system/flcore/servers/serveravg.py Обратите внимание, что большинство из этих оценок обычно не рассматриваются в исходных статьях. Мы призываем вас добавить больше атак и метрик для оценки конфиденциальности.
Чтобы имитировать федеративное обучение (FL) в практических условиях, таких как отсечение клиента , медленные тренеры , медленные отправители и сетевой TTL (время к продолжению) , вы можете настроить следующие параметры:
-cdr : Скорость отсева для клиентов. Клиенты случайным образом сбрасываются в каждом учебном раунде на основе этой скорости.-tsr и -ssr : медленный тренер и медленные рассылки, соответственно. Эти параметры определяют долю клиентов, которые будут вести себя как медленные тренеры или медленные отправители. Как только клиент будет выбран в качестве «медленного тренера» или «медленного отправителя», он будет последовательно тренироваться/отправлять медленнее, чем другие клиенты.-tth : Порог для сети TTL в миллисекундах.Благодаря @stonesjtu, эта библиотека также может записать использование памяти графического процессора для модели.
Если вы заинтересованы в экспериментальных результатах (например, точность) для алгоритмов, упомянутых выше, вы можете найти результаты в наших общепринятых документах FL, в которых также используется эта библиотека. Эти документы включают в себя:
Обратите внимание, что, хотя эти результаты были основаны на этой библиотеке, воспроизведение точных результатов может быть сложным, поскольку некоторые настройки могли измениться в ответ на обратную связь с сообществом. Например, в более ранних версиях мы устанавливаем shuffle=False in clientbase.py .
Вот соответствующие статьи для вашей ссылки:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


