PFLlib
37 methods
Kami membuat perpustakaan algoritma yang ramah-pemula dan platform benchmark untuk mereka yang baru untuk pembelajaran federasi. Bergabunglah dengan kami dalam memperluas komunitas FL dengan menyumbangkan algoritma, dataset, dan metrik Anda untuk proyek ini.
? Pfllib sekarang memiliki situs web resminya dan nama domainnya: https: //www.pfllib.com/ !!!
? Papan peringkatnya langsung! Metode kami - FEDCP, GPFL, dan FedDbe - sia -sia. Khususnya, FedDBE menonjol dengan kinerja yang kuat di berbagai tingkat heterogenitas data.
? Kami akan mengubah lisensi ke Apache-2.0 di rilis berikutnya.
Empat dataset baru telah ditambahkan, dua di antaranya membahas skenario dunia nyata : (1) Patch jaringan tumor dari metastasis kanker payudara di bagian kelenjar getah bening yang bersumber dari berbagai rumah sakit , dan (2) foto satwa liar yang ditangkap oleh perangkap kamera yang berbeda . Dua dataset lainnya fokus pada skenario label-skew : gambar x-ray dada dari rumah sakit untuk covid-19 dan gambar endoskopi dari rumah sakit untuk deteksi penyakit gastrointestinal. Kumpulan data ini juga kompatibel dengan htfllib kami
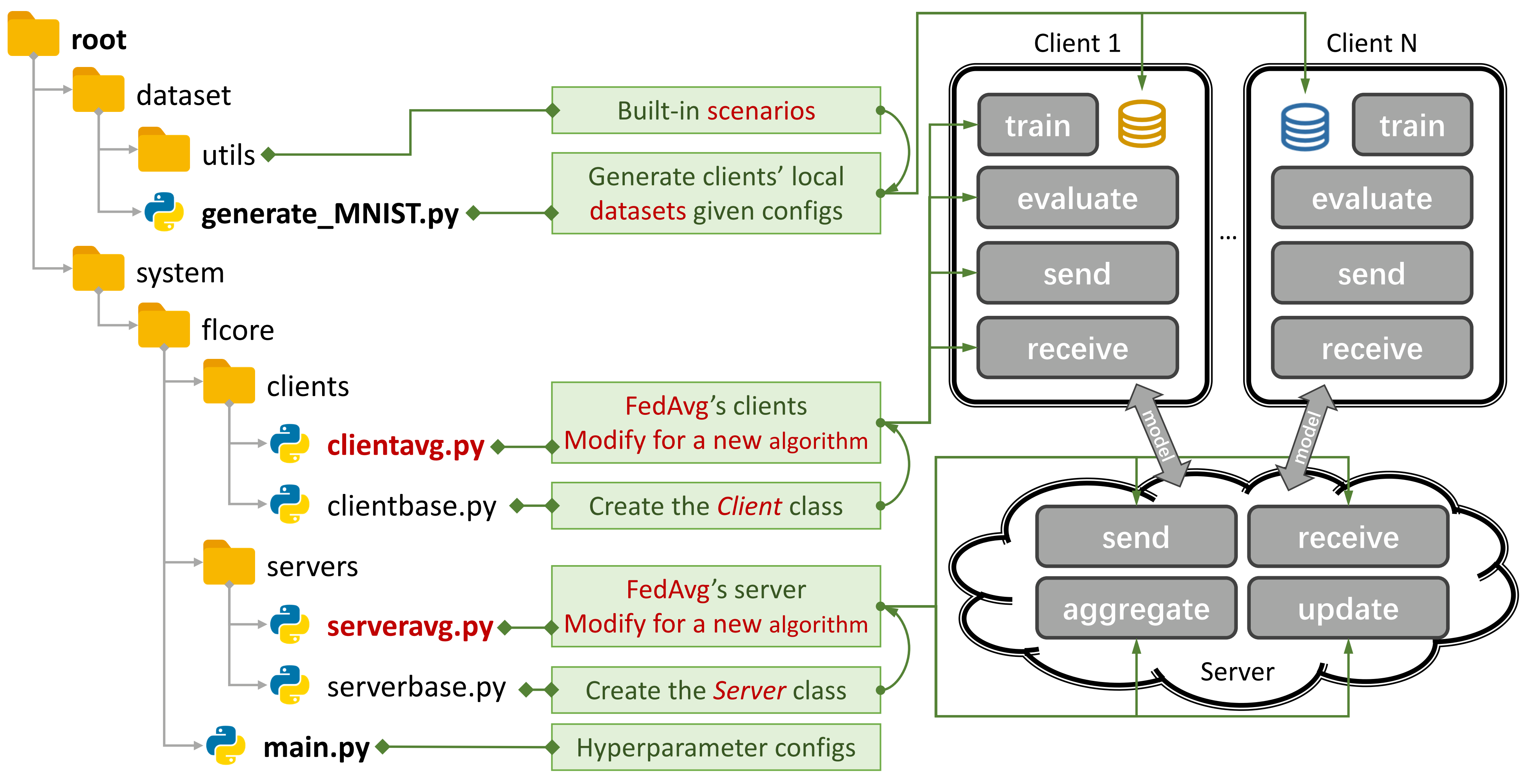 Gambar 1: Contoh untuk Fedavg. Anda dapat membuat skenario menggunakan
Gambar 1: Contoh untuk Fedavg. Anda dapat membuat skenario menggunakan generate_DATA.py dan menjalankan algoritma menggunakan main.py , clientNAME.py , dan serverNAME.py . Untuk algoritma baru, Anda hanya perlu menambahkan fitur baru di clientNAME.py dan serverNAME.py .
Jika Anda menemukan repositori kami berguna, silakan kutip kertas yang sesuai:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 Algoritma FL (TFL) tradisional dan algoritma FL (PFL) yang dipersonalisasi, 3 skenario, dan 24 set data.
Beberapa hasil eksperimen tersedia dalam makalahnya dan di sini.
Lihat panduan ini untuk mempelajari cara menggunakannya.
Platform benchmark dapat mensimulasikan skenario menggunakan CNN 4-lapis di CIFAR100 untuk 500 klien pada satu kartu GPU NVIDIA GeForce RTX 3090 dengan hanya biaya memori GPU 5.08GB .
Kami memberikan evaluasi privasi dan penekan penelitian sistematis.
Anda sekarang dapat melatih beberapa klien dan mengevaluasi kinerja pada klien baru dengan mengatur args.num_new_clients di ./system/main.py . Harap dicatat bahwa tidak semua algoritma TFL/PFL mendukung fitur ini.
Pfllib terutama berfokus pada heterogenitas data (statistik). Untuk algoritma dan platform benchmark yang membahas data heterogenitas data dan model , silakan merujuk ke proyek heterogen federated project kami yang diperluas (htfllib) .
Saat kami berusaha untuk memenuhi permintaan pengguna yang beragam, seringnya pembaruan untuk proyek dapat mengubah pengaturan default dan kode pembuatan skenario, yang mempengaruhi hasil eksperimen.
Masalah tertutup dapat banyak membantu Anda ketika kesalahan muncul.
Saat mengirimkan permintaan tarik, berikan instruksi dan contoh yang cukup di kotak komentar.
Asal usul fenomena heterogenitas data adalah karakteristik pengguna, yang menghasilkan data non-IID (tidak independen dan terdistribusi secara identik) dan tidak seimbang. Dengan heterogenitas data yang ada dalam skenario FL, segudang pendekatan telah diusulkan untuk memecahkan kacang keras ini. Sebaliknya, FL (PFL) yang dipersonalisasi dapat memanfaatkan data heterogen yang secara statistik untuk mempelajari model yang dipersonalisasi untuk setiap pengguna.
FL tradisional (TFL)
TFL Dasar
Fedavg -Pembelajaran yang hemat komunikasi dari jaringan dalam dari data terdesentralisasi Aistats 2017
TFL Berbasis Perbarui Koreksi
SCAFFOLD - SCAFFOLD: Rata -rata terkontrol stokastik untuk pembelajaran federasi ICML 2020
TFL berbasis regularisasi
FedProx - Optimalisasi Federasi dalam Jaringan Heterogen MLSYS 2020
Feddyn - Pembelajaran federasi berdasarkan regularisasi dinamis ICLR 2021
TFL berbasis model-splitting
Moon -Model-Contrastive Federated Learning CVPR 2021
FedLC - Pembelajaran Federasi dengan Distribusi Label Condong Via Logit Calibration ICML 2022
TFL Berbasis Distilasi Pengetahuan
FedGen -Distilasi Pengetahuan Bebas Data untuk Pembelajaran Federasi Heterogen ICML 2021
Fedntd -Pelestarian Pengetahuan Global dengan Distilasi Tidak Kebetulan dalam Pembelajaran Federasi Neurips 2022
FL (PFL) yang dipersonalisasi
PFL berbasis meta-pembelajaran
Per-Fedavg -Pembelajaran federasi yang dipersonalisasi dengan jaminan teoretis: Pendekatan meta-pembelajaran model-agnostik Neurips 2020
PFL berbasis regularisasi
PFEDME - Pembelajaran federasi yang dipersonalisasi dengan Moreau Amplop Neurips 2020
Ditto - Ditto: Pembelajaran federasi yang adil dan kuat melalui personalisasi ICML 2021
PFL berbasis agregasi yang dipersonalisasi
APFL - Adaptive Pribadi Federated Learning 2020
FedFomo - Pembelajaran Federasi yang Dipersonalisasi dengan Optimasi Model Pesanan Pertama ICLR 2021
Fedamp -Pembelajaran federasi silang-silo yang dipersonalisasi pada data non-IID AAAI 2021
FedPHP - FedPHP: Personalisasi Federasi dengan Model Privat Berwaris ECML PKDD 2021
Apple -Adaptasi dengan Adaptasi: Belajar Personalisasi untuk Pembelajaran Federasi Silang-Silo IJCAI 2022
Fedala - Fedala: Agregasi lokal adaptif untuk pembelajaran federasi yang dipersonalisasi AAAI 2023
PFL berbasis model-splitting
Fedper - Pembelajaran Federasi dengan Lapisan Personalisasi 2019
LG-Fedavg -Berpikir secara lokal, bertindak secara global: pembelajaran federasi dengan representasi lokal dan global 2020
FedREP - Mengeksploitasi Representasi Bersama untuk Pembelajaran Federasi yang Dipersonalisasi ICML 2021
FedRod - Di Bridging Generik dan Pribadi Pembelajaran Federasi untuk Klasifikasi Gambar ICLR 2022
FedBabu - FedBabu: Menuju Peningkatan Representasi untuk Klasifikasi Gambar Federasi ICLR 2022
FedGC - Pembelajaran Federasi untuk Pengakuan Wajah dengan Koreksi Gradien AAAI 2022
FedCP - FedCP: Memisahkan informasi fitur untuk pembelajaran federasi yang dipersonalisasi melalui kebijakan bersyarat KDD 2023
GPFL - GPFL: Secara bersamaan mempelajari informasi fitur generik dan pribadi untuk pembelajaran federasi yang dipersonalisasi ICCV 2023
Fedgh - FedGH: Pembelajaran federasi yang heterogen dengan header global ACM MM 2023 umum
FedDBE - Menghilangkan Bias Domain untuk Pembelajaran Federasi dalam Representasi Ruang Neurips 2023
FedCAC - Bold tapi hati -hati: Membuka kunci potensi pembelajaran federasi yang dipersonalisasi melalui kolaborasi agresif ICCV 2023 dengan hati -hati
PFL-DA -Pembelajaran federasi yang dipersonalisasi melalui adaptasi domain dengan aplikasi untuk Technometrics Printing 3D Terdistribusi 2023
Pfl lainnya
FedMTL (bukan Mocha) -Federated Multi-Task Learning Neurips 2017
FedBN -FedBN: Pembelajaran federasi pada fitur non-IID melalui normalisasi batch lokal ICLR 2021
PFL berbasis Distilasi Pengetahuan (lebih lanjut di htfllib)
FedDistill (FD) -Pembelajaran mesin di perangkat yang efisien-komunikasi: Distilasi dan augmentasi federasi di bawah data pribadi non-IID 2018
FML - Federated Mutual Learning 2020
FEDKD -Pembelajaran Federasi Hemat Komunikasi Melalui Pengetahuan Distilasi Nature Communications 2022
FedProto - FedProto: Pembelajaran prototipe federasi di seluruh klien yang heterogen AAAI 2022
FEDPCL (W/O Model Pra-Terlatih) -Pembelajaran federasi dari model pra-terlatih: pendekatan pembelajaran kontras Neurips 2022
FedPAC - Pembelajaran Federasi yang Dipersonalisasi dengan Penyelarasan Fitur dan Kolaborasi Klasifikasi ICLR 2023
Kami mendukung 3 jenis skenario dengan berbagai set data dan memindahkan kode pemisahan dataset umum ke ./dataset/utils untuk ekstensi yang mudah. Jika Anda memerlukan kumpulan data lain, cukup tulis kode lain untuk mengunduhnya dan kemudian gunakan utils.
Untuk skenario label kemiringan , kami memperkenalkan 16 set data terkenal:
Dataset dapat dengan mudah dibagi menjadi versi IID dan non-IID . Dalam skenario non-IID , kami membedakan antara dua jenis distribusi:
Patologis Non-IID : Dalam hal ini, setiap klien hanya memegang subset label, misalnya, hanya 2 dari 10 label dari dataset MNIST, meskipun dataset keseluruhan berisi semua 10 label. Ini mengarah pada distribusi data yang sangat miring di seluruh klien.
Praktis Non-IID : Di sini, kami memodelkan distribusi data menggunakan distribusi Dirichlet, yang menghasilkan ketidakseimbangan yang lebih realistis dan kurang ekstrem. Untuk detail lebih lanjut tentang ini, lihat makalah ini.
Selain itu, kami menawarkan opsi balance , di mana jumlah data didistribusikan secara merata di semua klien.
Untuk skenario shift fitur , kami menggunakan 3 set data yang banyak digunakan dalam adaptasi domain:
Untuk skenario dunia nyata , kami memperkenalkan 5 set data yang dipisahkan secara alami:
Untuk detail lebih lanjut tentang dataset dan algoritma FL di IoT , silakan merujuk ke FL-IOT.
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy Output baris perintah dari menjalankan python generate_MNIST.py noniid - dir
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
untuk mnist dan fashion-mnist
untuk CIFAR10, CIFAR100 dan Tiny-Imagenet
untuk ag_news dan sogou_news
untuk AmazonReview
untuk omniglot
Untuk Har dan Pamap
Instal Cuda.
Instal Conda terbaru dan aktifkan Conda.
Untuk konfigurasi tambahan, lihat skrip prepare.sh .
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version Unduh proyek ini ke lokasi yang sesuai menggunakan git.
git clone https://github.com/TsingZ0/PFLlib.gitBuat lingkungan yang tepat (lihat lingkungan).
Bangun skenario evaluasi (lihat set data dan skenario (memperbarui)).
Jalankan Evaluasi:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN modelCatatan : Lebih disukai untuk menyetel parameter hyper-parameter khusus algoritma sebelum menggunakan algoritma apa pun pada mesin baru.
Perpustakaan ini dirancang agar mudah diperpanjang dengan algoritma dan dataset baru. Begini cara Anda menambahkannya:
Dataset Baru : Untuk menambahkan dataset baru, cukup buat file generate_DATA.py di ./dataset dan kemudian tulis kode unduhan dan gunakan utils seperti yang ditunjukkan di ./dataset/generate_MNIST.py (Anda dapat mempertimbangkannya sebagai templat):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func Algoritma baru : Untuk menambahkan algoritma baru, memperluas server kelas dan klien , yang didefinisikan dalam ./system/flcore/servers/serverbase.py dan ./system/flcore/clients/clientbase.py , masing -masing.
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm Model baru : Untuk menambahkan model baru, cukup sertakan di ./system/flcore/trainmodel/models.py .
Pengoptimal baru : Jika Anda memerlukan pengoptimal baru untuk pelatihan, tambahkan ke ./system/flcore/optimizers/fedoptimizer.py .
Platform atau Perpustakaan Benchmark Baru : Kerangka kerja kami fleksibel, memungkinkan pengguna untuk membangun platform atau pustaka khusus untuk aplikasi tertentu, seperti FL-IOT dan HTFLLIB.
Anda dapat menggunakan metode evaluasi privasi berikut untuk menilai kemampuan pemeliharaan privasi dari algoritma TFL/PFL di Pfllib. Silakan merujuk ke ./system/flcore/servers/serveravg.py untuk contoh. Perhatikan bahwa sebagian besar evaluasi ini biasanya tidak dipertimbangkan dalam makalah asli. Kami mendorong Anda untuk menambahkan lebih banyak serangan dan metrik untuk evaluasi privasi.
Untuk mensimulasikan pembelajaran gabungan (FL) dalam kondisi praktis, seperti putus sekolah , pelatih lambat , pengirim lambat , dan jaringan TTL (waktu-ke-hidup) , Anda dapat menyesuaikan parameter berikut:
-cdr : Tingkat putus sekolah untuk klien. Klien secara acak dijatuhkan pada setiap putaran pelatihan berdasarkan tingkat ini.-tsr dan -ssr : masing -masing pelatih lambat dan laju pengirim lambat. Parameter ini menentukan proporsi klien yang akan berperilaku sebagai pelatih lambat atau pengirim lambat. Setelah klien dipilih sebagai "pelatih lambat" atau "pengirim lambat," itu akan secara konsisten melatih/mengirim lebih lambat dari klien lain.-tth : Ambang batas untuk jaringan TTL dalam milidetik.Berkat @stonesjtu, perpustakaan ini juga dapat merekam penggunaan memori GPU untuk modelnya.
Jika Anda tertarik dengan hasil eksperimen (misalnya, akurasi) untuk algoritma yang disebutkan di atas, Anda dapat menemukan hasil dalam kertas FL yang kami terima, yang juga memanfaatkan perpustakaan ini. Makalah ini termasuk:
Harap dicatat bahwa sementara hasil ini didasarkan pada perpustakaan ini, mereproduksi hasil yang tepat mungkin menantang karena beberapa pengaturan mungkin telah berubah dalam menanggapi umpan balik masyarakat. Misalnya, dalam versi sebelumnya, kami mengatur shuffle=False di clientbase.py .
Berikut adalah makalah yang relevan untuk referensi Anda:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


