PFLlib
37 methods
우리는 연합 학습을 처음 접하는 사람들을위한 초보자 친화적 인 알고리즘 라이브러리와 벤치 마크 플랫폼을 만듭니다. 이 프로젝트에 대한 알고리즘, 데이터 세트 및 메트릭을 기고하여 FL 커뮤니티를 확장하는 데 참여하십시오.
? pfllib은 이제 공식 웹 사이트와 도메인 이름이 있습니다 : https : //www.pfllib.com/ !!!
? 리더 보드가 라이브입니다! 우리의 방법 - FEDCP, GPFL 및 Feddbe는 길을 열어주십시오. 특히, Feddbe는 다양한 데이터 이질성 수준에서 강력한 성능으로 두드러집니다.
? 다음 릴리스에서 라이센스를 Apache-2.0으로 변경합니다.
4 개의 새로운 데이터 세트가 추가되었습니다. 그 중 2 개는 실제 시나리오를 다루었습니다. (1) 다른 병원 에서 공급되는 림프절 섹션의 유방암 전이의 종양 조직 패치 및 (2) 다른 카메라 트랩 으로 포착 된 야생 동물 사진. 다른 두 데이터 세트는 라벨이없는 시나리오에 중점을 둡니다. COVID-19 용 병원 의 흉부 X- 레이 이미지 및 위장병 검출을위한 병원 의 내시경 이미지. 이 데이터 세트는 HTFllib 와도 호환됩니다
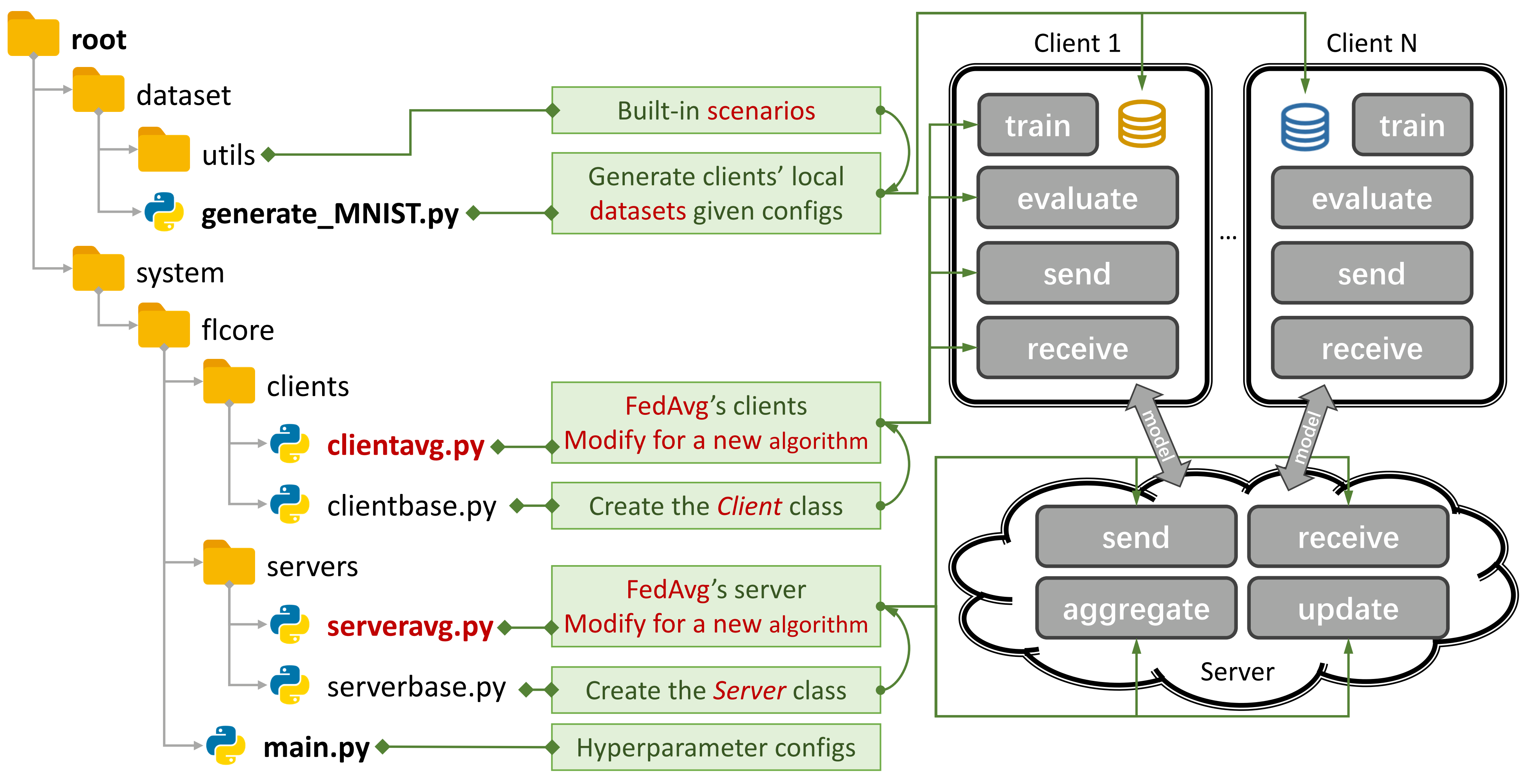 그림 1 : Fedavg의 예.
그림 1 : Fedavg의 예. generate_DATA.py 사용하여 시나리오를 작성하고 main.py , clientNAME.py 및 serverNAME.py 사용하여 알고리즘을 실행할 수 있습니다. 새로운 알고리즘의 경우 clientNAME.py 및 serverNAME.py 에 새로운 기능 만 추가하면됩니다.
유용한 저장소가 유용하다고 생각되면 해당 용지를 인용하십시오.
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 전통적인 FL (TFL) 및 개인화 된 FL (PFL) 알고리즘, 3 개의 시나리오 및 24 개의 데이터 세트.
일부 실험 결과는 종이와 여기에서 불가능합니다.
사용 방법을 배우려면이 안내서를 참조하십시오.
벤치 마크 플랫폼은 CIFAR100의 4 층 CNN을 사용하여 500 개의 클라이언트를 사용하여 500 개의 클라이언트를 사용하여 5.08GB GPU 메모리 비용만으로 시나리오를 시뮬레이션 할 수 있습니다.
우리는 개인 정보 평가 및 체계적인 연구를 제공합니다.
이제 일부 클라이언트를 훈련시키고 args.num_new_clients ./system/main.py 로 설정하여 새로운 고객에 대한 성과를 평가할 수 있습니다. 모든 TFL/PFL 알고리즘 이이 기능을 지원하는 것은 아닙니다.
pfllib는 주로 데이터 (통계적) 이질성에 중점을 둡니다. 데이터 및 모델 이질성을 모두 해결하는 알고리즘과 벤치 마크 플랫폼의 경우 확장 된 프로젝트 이종 연합 학습 (HTFLLIB) 을 참조하십시오.
다양한 사용자 요구를 충족시키기 위해 노력하면서 프로젝트에 대한 빈번한 업데이트는 기본 설정 및 시나리오 작성 코드를 변경하여 실험 결과에 영향을 줄 수 있습니다.
폐쇄 된 문제는 오류가 발생할 때 많은 도움이 될 수 있습니다.
풀 요청을 제출할 때 댓글 상자에 충분한 지침 과 예제를 제공하십시오.
데이터 이질성 현상의 기원은 비 IID (독립적이고 동일하게 분포되지 않은) 및 불균형 데이터를 생성하는 사용자의 특성입니다. FL 시나리오에 데이터 이질성이 존재함에 따라,이 단단한 너트를 깨뜨리기위한 수많은 접근법이 제안되었습니다. 대조적으로, 개인화 된 FL (PFL)은 통계적으로 이질적인 데이터를 활용하여 각 사용자의 개인화 된 모델을 학습 할 수 있습니다.
전통적인 FL (TFL)
기본 TFL
Fedavg- 분산 된 데이터 Aistats 2017 의 심층 네트워크의 커뮤니케이션 효율적인 학습
업데이트-수정 기반 TFL
스캐 폴드 - 스캐 폴드 : 연합 학습을위한 확률 론적 제어 평균 ICML 2020
정규화 기반 TFL
FedProx - 이종 네트워크 MLSYS 2020 에서의 연합 최적화
Feddyn - 역동적 인 정규화 ICLR 2021 에 기반한 Federated Learning
모델-분할 기반 TFL
문 -모델 대상 연합 학습 CVPR 2021
FEDLC - 로그 캘리브레이션 ICML 2022를 통한 라벨 분포 왜곡으로 페더레이션 학습
지식-방지 기반 TFL
Fedgen- 이종 연합 학습 ICML 2021에 대한 데이터가없는 지식 증류
FEDNTD- 연합 학습 신경 립스에서 진실하지 않은 증류에 의한 글로벌 지식 보존 2022
개인화 된 FL (PFL)
메타 학습 기반 PFL
FEDAVG 당 -이론적 보증을 가진 개인화 된 연합 학습 : 모델 공유 메타 학습 접근법 Neurips 2020
정규화 기반 PFL
PFEDME - Moreau Envelopes Neurips 2020을 가진 개인화 된 연합 학습
Ditto - Ditto : 개인화를 통한 공정하고 강력한 연합 학습 ICML 2021
개인화 된 응집 기반 PFL
APFL - 적응 형 맞춤형 연합 학습 2020
Fedfomo - 1 차 모델 최적화 ICLR 2021을 사용한 개인화 된 연합 학습
Fedamp- 비 IID 데이터에 대한 개인화 된 크로스 실로 연합 학습 AAAI 2021
FEDPHP - FEDPHP : 상속 된 개인 모델과의 연합 개인화 ECML PKDD 2021
Apple- 적응에 적응 : 크로스 실로 연합 학습을위한 개인화 학습 ijcai 2022
Fedala - Fedala : 개인화 된 Federated Learning AAAI 2023을 위한 적응 형 로컬 집계
모델-분할 기반 PFL
Fedper - 개인화 계층 2019를 이용한 연합 학습
lg-fedavg- 현지에서 생각하고, 전 세계적으로 행동 : 지역 및 글로벌 표현과의 연합 학습 2020
FedRep - 개인화 된 Federated Learning ICML 2021에 대한 공유 된 표현 악용
Fedrod - 이미지 분류를위한 일반 및 개인화 된 연합 학습 브리징 ICLR 2022
FedBabu - FedBabu : Federated Image Classification ICLR 2022에 대한 향상된 표현을 향해
FEDGC - 그라디언트 보정 AAAI 2022 로 얼굴 인식을위한 연합 학습
FEDCP - FEDCP : 조건부 정책 KDD 2023을 통한 개인화 된 연합 학습을위한 기능 정보 분리
GPFL - GPFL : 개인화 된 연합 학습을위한 일반 및 개인화 된 기능 정보를 동시에 학습 ICCV 2023
Fedgh - Fedgh : 일반화 된 글로벌 헤더 ACM MM 2023을 통한 이종 연합 학습
Feddbe - 표현 공간에서 연합 학습을위한 도메인 바이어스 제거 2023
FedCAC - 대담하지만 조심스럽게 : 신중하게 공격적인 협업 ICCV 2023을 통한 개인화 된 연합 학습의 잠재력 잠금 해제
PFL-DA- 분산 된 3D 프린팅 기술자에 대한 응용 프로그램을 사용하여 도메인 적응을 통한 개인화 된 연합 학습 2023
다른 pfl
FEDMTL (MOCHA 아님) -Federated Multi-Task Learning Neurips 2017
FEDBN -FEDBN : 로컬 배치 정규화 ICLR 2021을 통한 비 IID 기능에 대한 연합 학습
지식-방지 기반 PFL (htfllib에서 더 많이)
Feddistill (FD) -커뮤니케이션 효율적인 사후 기계 학습 : 비 IID 개인 데이터에 따른 연합 증류 및 증강 2018
FML - Federated Mutual Learning 2020
FEDKD- 지식 증류 자연 커뮤니케이션을 통한 의사 소통 효율적인 연합 학습 2022
FedProto - FedProto : 이기종 고객 AAAI 2022 에 걸친 Federated 프로토 타입 학습
FEDPCL (사전 훈련 된 모델 w/o) -미리 훈련 된 모델의 연합 학습 : 대조 학습 접근법 Neurips 2022
FEDPAC - 기능 정렬 및 분류기 공동 작업 ICLR 2023을 사용한 개인화 된 연합 학습
다양한 데이터 세트를 사용하여 3 가지 유형의 시나리오를 지원하고 공통 데이터 세트 분할 코드를 ./dataset/utils 로 이동하여 쉽게 확장 할 수 있습니다. 다른 데이터 세트가 필요한 경우 다른 코드를 작성하여 다운로드 한 다음 Utils를 사용하십시오.
레이블 Skew 시나리오의 경우 16 개의 유명한 데이터 세트를 소개합니다.
데이터 세트는 IID 및 비 IID 버전으로 쉽게 분할 될 수 있습니다. 비 IID 시나리오에서는 두 가지 유형의 분포를 구별합니다.
병리학 적 비 IID :이 경우 각 클라이언트는 레이블의 하위 집합 만 보유합니다. 예를 들어 전체 데이터 세트에 10 개의 레이블이 모두 포함되어 있어도 MNIST 데이터 세트에서 10 개의 레이블 중 2 개만 표시됩니다. 이로 인해 클라이언트 전체의 데이터 분포가 매우 비뚤어집니다.
실질적인 비 IID : 여기서는 Dirichlet 분포를 사용하여 데이터 배포를 모델링하여보다 현실적이고 덜 극단적 인 불균형을 나타냅니다. 이에 대한 자세한 내용은이 논문을 참조하십시오.
또한 모든 클라이언트에 데이터 금액이 균등하게 배포되는 balance 옵션을 제공합니다.
기능 시계 시나리오의 경우 도메인 적응에서 널리 사용되는 3 가지 데이터 세트를 사용합니다.
실제 시나리오의 경우 자연적으로 분리 된 5 가지 데이터 세트를 소개합니다.
IoT 의 데이터 세트 및 FL 알고리즘에 대한 자세한 내용은 FL-OIT을 참조하십시오.
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy python generate_MNIST.py noniid - dir 의 명령 줄 출력
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
MNIST와 Fashion-Mnist를 위해
CIFAR10, CIFAR100 및 Tiny-Imagenet의 경우
ag_news 및 sogou_news의 경우
AmazonReview의 경우
Omniglot의 경우
Har와 Pamap의 경우
CUDA를 설치하십시오.
Conda 최신을 설치하고 Conda를 활성화하십시오.
추가 구성은 prepare.sh 스크립트를 참조하십시오.
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version 이 프로젝트를 GIT를 사용하여 적절한 위치로 다운로드하십시오.
git clone https://github.com/TsingZ0/PFLlib.git적절한 환경을 만듭니다 (환경 참조).
평가 시나리오 구축 (데이터 세트 및 시나리오 (업데이트) 참조).
실행 평가 :
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN model참고 : 새 시스템에서 알고리즘을 사용하기 전에 알고리즘 별 하이퍼 파라미터를 조정하는 것이 바람직합니다.
이 라이브러리는 새로운 알고리즘과 데이터 세트로 쉽게 확장 할 수 있도록 설계되었습니다. 다음은 다음을 추가 할 수있는 방법입니다.
새 데이터 세트 : 새 데이터 세트를 추가하려면 ./dataset 에서 generate_DATA.py 파일을 작성한 다음 다운로드 코드를 작성하고 ./dataset/generate_MNIST.py (템플릿으로 간주 할 수 있음)에 표시된대로 Utils를 사용하십시오.
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func 새로운 알고리즘 : 새로운 알고리즘을 추가하려면 각각 ./system/flcore/servers/serverbase.py 및 ./system/flcore/clients/clientbase.py 에 정의 된 Base Classes 서버 및 클라이언트를 확장하십시오.
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm 새 모델 : 새 모델을 추가하려면 ./system/flcore/trainmodel/models.py 에 포함시키기 만하면됩니다.
새로운 최적화기 : 교육을 위해 새로운 최적화기가 필요한 경우 ./system/flcore/optimizers/fedoptimizer.py flcore/optimizers/fedoptimizer.py에 추가하십시오.
새로운 벤치 마크 플랫폼 또는 라이브러리 : 당사의 프레임 워크는 유연하므로 사용자는 FL-OIT 및 HTFLLIB와 같은 특정 응용 프로그램을 위해 사용자 정의 플랫폼 또는 라이브러리를 구축 할 수 있습니다.
다음 개인 정보 보호 평가 방법을 사용하여 PFLLIB에서 TFL/PFL 알고리즘의 개인 정보 보호 기능을 평가할 수 있습니다. 예를 들어 ./system/flcore/servers/serveravg.py 를 참조하십시오. 이러한 평가의 대부분은 일반적으로 원래 논문에서 고려되지 않습니다. 개인 정보 보호 평가를 위해 더 많은 공격과 메트릭을 추가하는 것이 좋습니다.
클라이언트 드롭 아웃 , 느린 트레이너 , 느린 발신자 및 네트워크 TTL (Time-to-Live) 과 같은 실제 조건에서 FL (Federated Learning)을 시뮬레이션하려면 다음 매개 변수를 조정할 수 있습니다.
-cdr : 클라이언트의 드롭 아웃 속도. 이 요금에 따라 고객은 각 교육 라운드에서 무작위로 떨어집니다.-tsr 및 -ssr : 각각 느린 트레이너 및 느린 발신자 요금. 이 매개 변수는 느린 트레이너 또는 느린 발신자로 작동하는 클라이언트의 비율을 정의합니다. 클라이언트가 "느린 트레이너"또는 "느린 발신자"로 선정되면 다른 고객보다 느리게 훈련/보내는 것을 지속적으로 발송합니다.-tth : 밀리 초의 네트워크 TTL의 임계 값.@stonesjtu 덕분 에이 라이브러리는 모델의 GPU 메모리 사용을 기록 할 수도 있습니다.
위에서 언급 한 알고리즘의 실험 결과 (예 : 정확도) 에 관심이 있다면이 라이브러리를 활용하는 허용 된 FL 용지에서 결과를 찾을 수 있습니다. 이 논문에는 다음이 포함됩니다.
이 결과는이 라이브러리를 기반으로했지만 커뮤니티 피드백에 따라 일부 설정이 변경되었을 수 있으므로 정확한 결과를 재현하는 것은 어려울 수 있습니다 . 예를 들어, 이전 버전에서는 clientbase.py 에서 shuffle=False 설정합니다.
참조와 관련된 관련 논문은 다음과 같습니다.
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


