PFLlib
37 methods
Wir erstellen eine anfängerfreundliche Algorithmus-Bibliothek und eine Benchmark-Plattform für die neuen Lernen mit Föderaten. Erweitern Sie die FL -Community, indem Sie Ihre Algorithmen, Datensätze und Metriken zu diesem Projekt beibehalten.
? Pfllib hat jetzt seine offizielle Website und den Domain -Namen: https: //www.pfllib.com/ !!!
? Die Rangliste ist live! Unsere Methoden - FEDCP, GPFL und Feddbe - leiten den Weg. Bemerkenswerterweise zeichnet sich Feddbe mit einer robusten Leistung über unterschiedliche Datenheterogenitätsniveaus hinweg aus.
? Wir werden die Lizenz in der nächsten Veröffentlichung in Apache-2.0 ändern.
Es wurden vier neue Datensätze hinzugefügt, von denen zwei reale Szenarien ansprechen: (1) Tumorgewebe-Patches aus Brustkrebsmetastasen in Lymphknotenabschnitten aus verschiedenen Krankenhäusern und (2) Wildtierfotos, die von verschiedenen Kamera-Fallen aufgenommen wurden. Die anderen beiden Datensätze konzentrieren sich auf das Szenario des Label-Skew : Röntgenbilder von Brustbildern aus Krankenhäusern für Covid-19 und endoskopische Bilder aus Krankenhäusern zur Erkennung von Magen-Darm-Erkrankungen. Diese Datensätze sind auch mit unserem HTfllib kompatibel
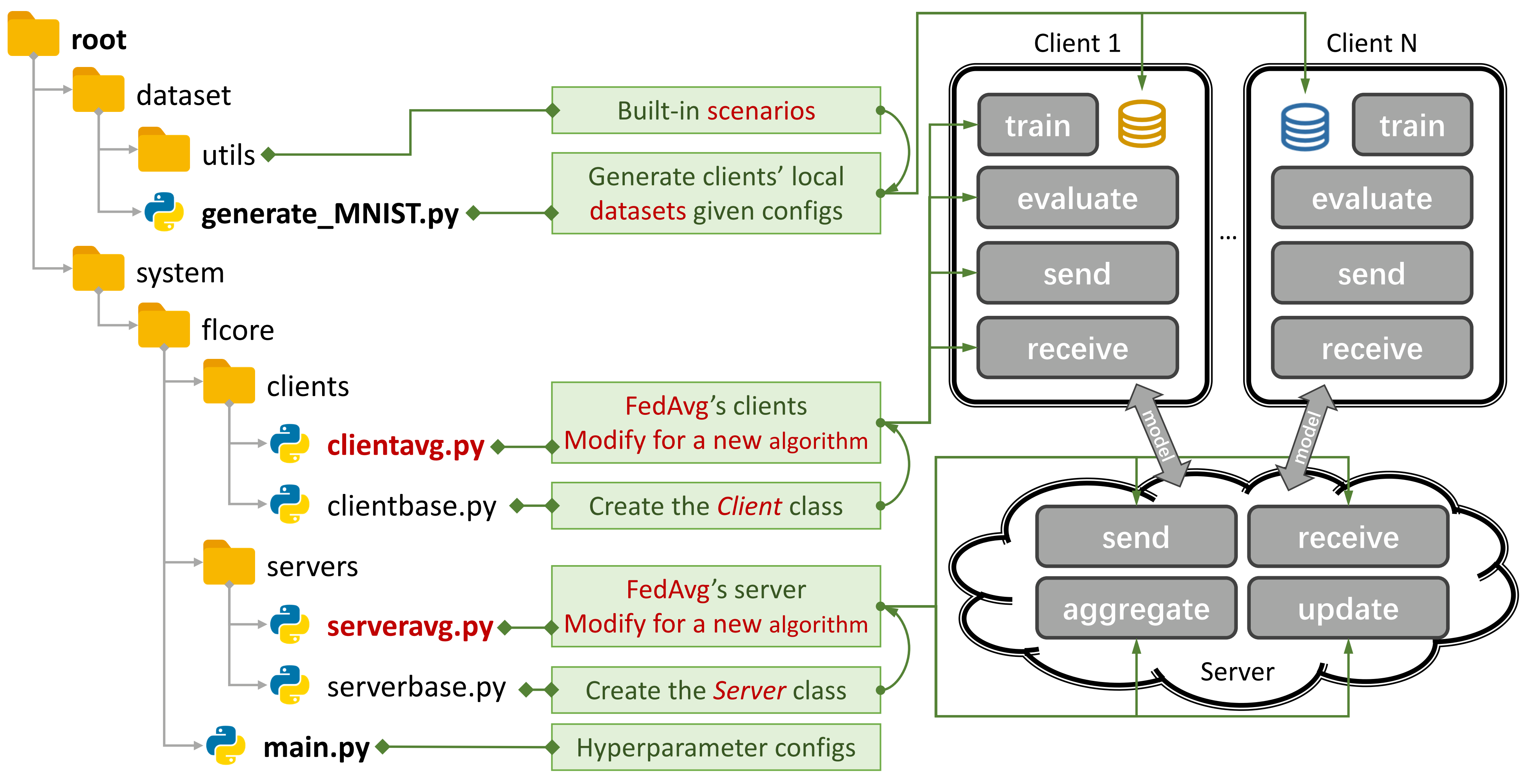 Abbildung 1: Ein Beispiel für Fedavg. Sie können ein Szenario mit
Abbildung 1: Ein Beispiel für Fedavg. Sie können ein Szenario mit generate_DATA.py erstellen und einen Algorithmus mit main.py , clientNAME.py und serverNAME.py ausführen. Für einen neuen Algorithmus müssen Sie nur neue Funktionen in clientNAME.py und serverNAME.py hinzufügen.
Wenn Sie unser Repository nützlich finden, zitieren Sie bitte das entsprechende Papier:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 Traditionelle FL (TFL) und personalisierte FL (PFL) -Algorithmen, 3 Szenarien und 24 Datensätze.
Einige experimentelle Ergebnisse sind in seinem Papier und hier verteilt.
Siehe diesen Leitfaden, um zu erfahren, wie man sie benutzt.
Die Benchmark-Plattform kann Szenarien mit dem 4-Layer-CNN auf CIFAR100 für 500 Clients auf einer NVIDIA Geforce RTX 3090 GPU-Karte mit nur 5,08 GB GPU- Speicherkosten simulieren.
Wir bieten Datenschutzbewertungen und systematische Forschung untertoten.
Sie können jetzt einige Kunden schulen und die Leistung für neue Kunden bewerten, indem Sie args.num_new_clients in ./system/main.py einstellen. Bitte beachten Sie, dass nicht alle TFL/PFL -Algorithmen diese Funktion unterstützen.
Pfllib konzentriert sich hauptsächlich auf Daten (statistische) Heterogenität. Für Algorithmen und eine Benchmark -Plattform, die sowohl Daten als auch Modellheterogenität angeht, finden Sie in unserem erweiterten Projekt Heterogenes Federated Learning (HTFllib) .
Wenn wir uns bemühen, verschiedene Benutzeranforderungen zu erfüllen, können häufige Aktualisierungen des Projekts Standardeinstellungen und Szenarienerstellungscodes verändern und die experimentellen Ergebnisse beeinflussen.
Geschlossene Probleme können Ihnen bei Auftreten von Fehlern sehr helfen.
Bei der Übermittlung von Pull -Anfragen geben Sie bitte ausreichende Anweisungen und Beispiele im Kommentarfeld an.
Der Ursprung des Datenheterogenitätsphänomens sind die Eigenschaften von Benutzern, die nicht-IID (nicht unabhängig und identisch verteilt) und unausgeglichene Daten generieren. Mit der im FL -Szenario vorhandenen Datenheterogenität wurden eine Vielzahl von Ansätzen vorgeschlagen, um diese harte Nuss zu knacken. Im Gegensatz dazu kann der personalisierte FL (PFL) die statistisch heterogenen Daten nutzen, um das personalisierte Modell für jeden Benutzer zu erlernen.
Traditioneller FL (TFL)
Basic TFL
FEDAVG -Kommunikationsbewertetes Lernen von tiefen Netzwerken aus dezentralen Daten Aistats 2017
Update-Korrektur-basierte TFL
Gerüst - Gerüst: Stochastische kontrollierte Mittelung für Federated Learning ICML 2020
Regularisierungsbasierte TFL
FEDPROX - Föderierte Optimierung in heterogenen Netzwerken MLSYS 2020
Feddyn - Föderiertes Lernen basierend auf der dynamischen Regularisierung ICLR 2021
Modell spaltungsbasiert TFL
Mond -Modellkontrastive Federated Learning CVPR 2021
FEDLC - Föderiertes Lernen mit Etikettenverteilung über Logits Kalibrierung ICML 2022
Wissensdestillationsbasierte TFL
Fedgen -datenfreie Wissensdestillation für heterogene Föderierten Lernen ICML 2021
FEDNTD -Erhaltung des globalen Wissens durch nicht strukturierte Destillation in Föderierten Learning Neurips 2022
Personalisierte FL (PFL)
Meta-Learning-basierte PFL
Per-Fedavg -Personalisiertes Föderierte Lernen mit theoretischen Garantien: Ein Modell-Agnostic Meta-Learning-Ansatz Neurips 2020
Regularisierungsbasierte PFL
PFEDME - Personalisierte Föderierte Lernen mit Moreau umhüllt Neurips 2020
Dito - dito: faires und robustes Föderierten durch Personalisierung ICML 2021
Personalisierte Aggregationsbasis PFL
APFL - Adaptive Personalisierte föderiertes Lernen 2020
FEDFOMO - Personalisiertes Federated Learning mit Modelloptimierung erster Ordnung ICLR 2021
FEDAMP -Personalisierte Cross-Silo-Föderierte Lernen auf Nicht-IID-Daten AAAI 2021
FEDPHP - FEDPHP: Föderierte Personalisierung mit ererbten privaten Modellen ECML PKDD 2021
Apple -Anpassen an die Anpassung: Lernen der Personalisierung für das Cross-Silo-Verbund-Lernen IJCAI 2022
Fedala - Fedala: Adaptive lokale Aggregation für personalisiertes Föderierten Lernen AAAI 2023
Modell spaltungsbasiert PFL
Fedper - Föderierte Lernen mit Personalisierungsschichten 2019
LG-FEDAVG -Denken Sie lokal, handeln Sie global: Föderiertes Lernen mit lokalen und globalen Darstellungen 2020
FEDREP - Nutzung gemeinsamer Darstellungen für personalisiertes Föderierte Lernen ICML 2021
FEDROD - Über die Überbrückung generischer und personalisierter Federated Learning for Image Classification ICLR 2022
FEDBABU - Fedbabu: Auf dem Weg zu einer verbesserten Darstellung für die föderierte Bildklassifizierung ICLR 2022
FEDGC - Föderiertes Lernen für Gesichtserkennung mit Gradientenkorrektur AAAI 2022
FEDCP - FEDCP: Trennung von Funktionsinformationen für das persönliche Föderierte Lernen über bedingte Richtlinien KDD 2023
GPFL - GPFL: Gleichzeitig lernen generische und personalisierte Funktionsinformationen für personalisiertes Föderierten Lernen ICCV 2023
FEDGH - FEDGH: Heterogener Föderierte Lernen mit verallgemeinerter globaler Header ACM MM 2023
FEDDBE - Domänenverzerrung für das Föderierten Lernen in Repräsentationsraumneurips 2023 beseitigen
Fedcac - mutig, aber vorsichtig: das Potenzial des personalisierten Föderierten Lernens durch vorsichtig aggressive Zusammenarbeit ICCV 2023 freischalten
PFL-DA -Personalisiertes Federated Learning über Domänenanpassung mit einer Anwendung auf verteilte 3D-Drucktechnometrie 2023
Andere PFL
FedMTL (nicht Mokka) -Verbund Multi-Task Learning Neurips 2017
FEDBN -FEDBN: Federated Learning on Nicht-IID-Merkmale über die lokale Stapel-Normalisierung ICLR 2021
Wissensdestillationsbasierte PFL (mehr in Htfllib)
Feddistill (FD) -Kommunikationsbewertetes maschinelles Lernen auf dem Gerät: Föderierte Destillation und Augmentation nach Nicht-IID-privaten Daten 2018
FML - Federated Mutual Learning 2020
Fedkd -Kommunikationsbewertetes Föderierte Lernen über Wissensdestillation Naturkommunikation 2022
FEDPROTO - FEDPROTO: Federated Prototyp -Lernen über heterogene Kunden AAAI 2022
FEDPCL (W/O-Modelle vorgeblieben) -Föderiertes Lernen aus vorgebliebenen Modellen: Ein kontrastiver Lernansatz Neurips 2022
FEDPAC - Personalisierte Föderierte Lernen mit Feature -Ausrichtung und Klassifikator -Zusammenarbeit ICLR 2023
Wir unterstützen 3 Arten von Szenarien mit verschiedenen Datensätzen und verschieben den gemeinsamen Datensatz -Spaltungscode in ./dataset/utils für eine einfache Erweiterung. Wenn Sie einen weiteren Datensatz benötigen, schreiben Sie einfach einen anderen Code, um ihn herunterzuladen, und verwenden Sie dann die Utils.
Für das Szenario des Etiketts führen wir 16 berühmte Datensätze vor:
Die Datensätze können leicht in IID- und Nicht-IID -Versionen aufgeteilt werden. Im Nicht-IID -Szenario unterscheiden wir zwischen zwei Arten der Verteilung:
Pathologische Nicht-IID : In diesem Fall enthält jeder Client nur eine Teilmenge der Etiketten, beispielsweise nur 2 von 10 Bezeichnungen aus dem MNIST-Datensatz, obwohl der Gesamtdatensatz alle 10 Etiketten enthält. Dies führt zu einer stark verzerrten Verteilung der Daten über Clients hinweg.
Praktische Nicht-IID : Hier modellieren wir die Datenverteilung anhand einer Dirichlet-Verteilung, was zu einem realistischeren und weniger extremen Ungleichgewicht führt. Weitere Informationen dazu finden Sie in diesem Artikel.
Darüber hinaus bieten wir eine balance -Option an, bei der die Datenmenge gleichmäßig auf alle Kunden verteilt ist.
Für das Feature Shift -Szenario verwenden wir 3 weit verbreitete Datensätze in der Domänenanpassung:
Für das reale Szenario führen wir 5 natürlich getrennte Datensätze ein:
Weitere Informationen zu Datensätzen und FL-Algorithmen im IoT finden Sie in FL-Iot.
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy Die Befehlszeilenausgabe von Running python generate_MNIST.py noniid - dir
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
Für MNIST und Fashion-Mnist
Für CIFAR10, CIFAR100 und Tiny-Imagenet
Für Ag_News und SOGOU_NEWS
Für Amazonreview
für Omniglot
Für Har und Pamap
CUDA installieren.
Installieren Sie Conda Lineal und aktivieren Sie Conda.
Weitere Konfigurationen finden Sie im Skript prepare.sh .
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version Laden Sie dieses Projekt mit Git an einen geeigneten Ort herunter.
git clone https://github.com/TsingZ0/PFLlib.gitErstellen Sie geeignete Umgebungen (siehe Umgebungen).
Erstellen Sie Bewertungsszenarien (siehe Datensätze und Szenarien (Aktualisierung)).
Run -Bewertung:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN modelHINWEIS : Es ist vorzuziehen, algorithmusspezifische Hyperparameter zu stimmen, bevor ein Algorithmus auf einer neuen Maschine verwendet wird.
Diese Bibliothek ist so konzipiert, dass sie mit neuen Algorithmen und Datensätzen leicht erweitert werden kann. So können Sie sie hinzufügen:
Neuer Datensatz : Erstellen Sie einfach eine neue Dataset, erstellen Sie einfach eine Datei generate_DATA.py in ./dataset und schreiben Sie dann den Download -Code und verwenden Sie die Utils wie in ./dataset/generate_MNIST.py (Sie können es als Vorlage betrachten):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func Neuer Algorithmus : Erweitern Sie den Basisklassenserver und den Client , der in ./system/flcore/servers/serverbase.py und ./system/flcore/clients/clientbase.py definiert ist, um einen neuen Algorithmus hinzuzufügen.
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm Neues Modell : Um ein neues Modell hinzuzufügen, geben Sie es einfach in ./system/flcore/trainmodel/models.py ein.
Neuer Optimierer : Wenn Sie einen neuen Optimierer für das Training benötigen, fügen Sie es zu ./system/flcore/optimizers/fedoptimizer.py hinzu.
Neue Benchmark-Plattform oder -Bibliothek : Unser Framework ist flexibel und ermöglicht es Benutzern, benutzerdefinierte Plattformen oder Bibliotheken für bestimmte Anwendungen wie FL-IT und HTFllib zu erstellen.
Sie können die folgenden Datenschutzbewertungsmethoden anwenden, um die Datenschutzfunktionen von TFL/PFL-Algorithmen in Pfllib zu bewerten. Ein Beispiel finden Sie unter ./system/flcore/servers/serveravg.py . Beachten Sie, dass die meisten dieser Bewertungen in den ursprünglichen Papieren normalerweise nicht berücksichtigt werden. Wir ermutigen Sie, weitere Angriffe und Metriken für die Datenschutzbewertung hinzuzufügen.
Um das Federated Learning (FL) unter praktischen Bedingungen wie Kundenabbrecher , langsame Trainer , langsame Absender und Netzwerk-TTL (Time-to-Live) zu simulieren, können Sie die folgenden Parameter einstellen:
-cdr : Ausfallrate für Kunden. Die Kunden werden aufgrund dieser Rate nach dem Zufallsprinzip bei jeder Trainingsrunde fallen gelassen.-tsr und -ssr : Slow Trainer und langsame Absenderraten. Diese Parameter definieren den Anteil der Kunden, die sich als langsame Trainer oder langsame Absender verhalten. Sobald ein Kunde als "langsamer Trainer" oder "langsamer Absender" ausgewählt wurde, trainiert/sendet er sich durchweg langsamer als andere Kunden.-tth : Schwellenwert für Netzwerk -TTL in Millisekunden.Dank @StonesJtu kann diese Bibliothek auch die GPU -Speicherverwendung für das Modell aufzeichnen.
Wenn Sie an experimentellen Ergebnissen (z. B. Genauigkeit) für die oben genannten Algorithmen interessiert sind, können Sie Ergebnisse in unseren akzeptierten FL -Papieren finden, die auch diese Bibliothek verwenden. Diese Papiere umfassen:
Bitte beachten Sie, dass diese Ergebnisse zwar auf dieser Bibliothek basierten, dass die Reproduktion der genauen Ergebnisse möglicherweise eine Herausforderung sein kann, da sich einige Einstellungen möglicherweise als Reaktion auf das Feedback der Community geändert haben. Zum Beispiel setzen wir in früheren Versionen shuffle=False in clientbase.py .
Hier sind die relevanten Papiere für Ihre Referenz:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


