PFLlib
37 methods
เราสร้างห้องสมุดอัลกอริทึมที่เป็นมิตรกับผู้เริ่มต้นและแพลตฟอร์มมาตรฐานสำหรับผู้ที่เพิ่งเรียนรู้แบบสหพันธรัฐ เข้าร่วมกับเราในการขยายชุมชน FL โดยการบริจาคอัลกอริทึมชุดข้อมูลและตัวชี้วัดของคุณในโครงการนี้
- ตอนนี้ Pfllib มีเว็บไซต์อย่างเป็นทางการและชื่อโดเมน: https: //www.pfllib.com/ !!!
- ลีดเดอร์บอร์ดมีชีวิตอยู่! วิธีการของเรา - FEDCP, GPFL และ Feddbe - นำวิธี โดยเฉพาะอย่างยิ่ง Feddbe โดดเด่นด้วยประสิทธิภาพที่แข็งแกร่งในระดับความหลากหลายของข้อมูลที่แตกต่างกัน
- เราจะเปลี่ยนใบอนุญาตเป็น Apache-2.0 ในรุ่นถัดไป
มีการเพิ่มชุดข้อมูลใหม่ สี่ชุด ซึ่งมีสองชุดที่อยู่ในสถานการณ์ จริง : (1) แพทช์เนื้อเยื่อเนื้องอกจากการแพร่กระจายของมะเร็งเต้านมในส่วนต่อมน้ำเหลืองที่มาจาก โรงพยาบาลที่แตกต่างกัน และ (2) ภาพถ่ายสัตว์ป่าที่ถ่ายโดยกับ ดักกล้องที่แตกต่างกัน ชุดข้อมูลอีกสองชุดมุ่งเน้นไปที่สถานการณ์ การเบี่ยงเบนฉลาก : ภาพเอ็กซ์เรย์หน้าอกจาก โรงพยาบาล สำหรับ COVID-19 และภาพส่องกล้องจาก โรงพยาบาล สำหรับการตรวจหาโรคทางเดินอาหาร ชุดข้อมูลเหล่านี้ยังเข้ากันได้กับ htfllib ของเรา
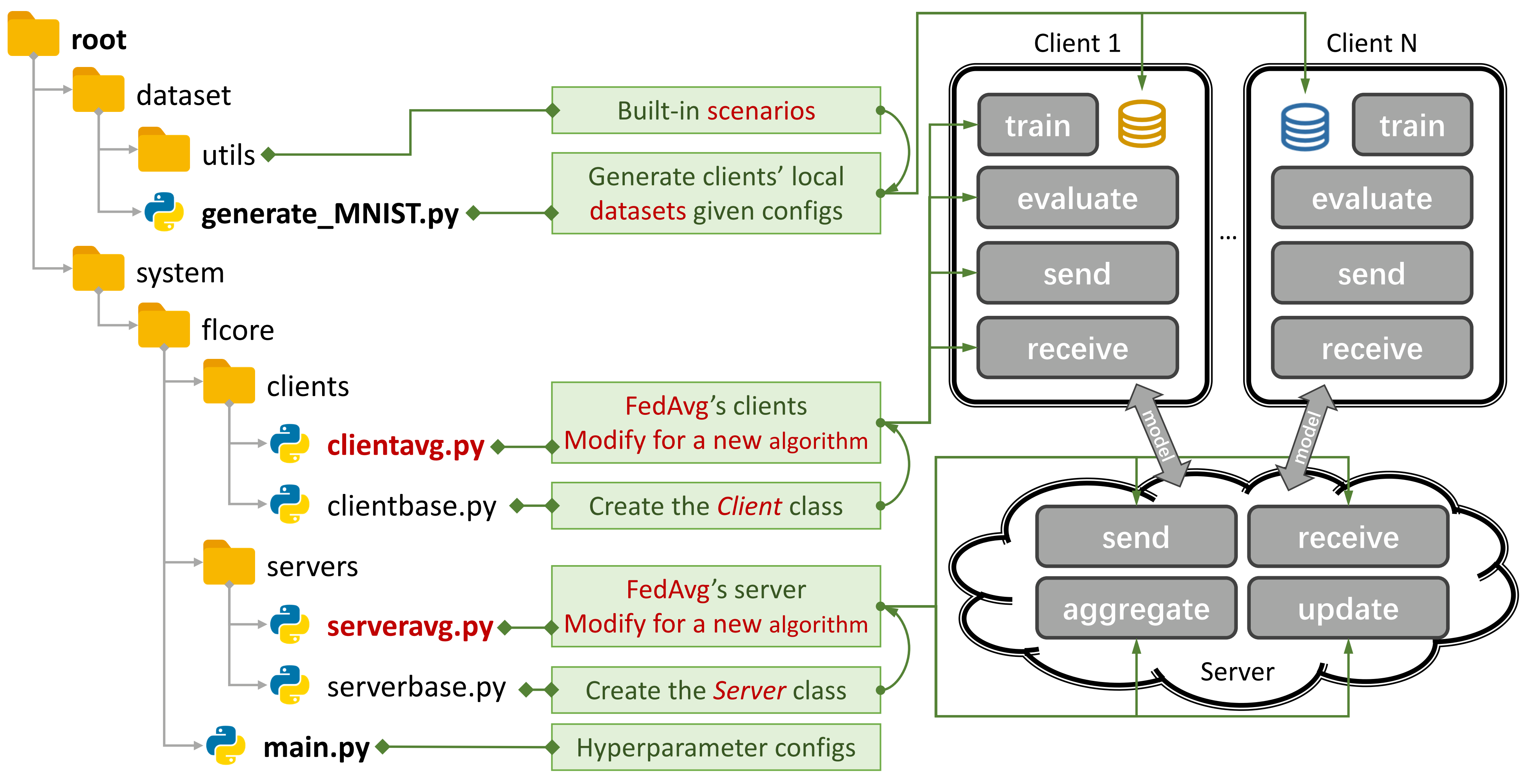 รูปที่ 1: ตัวอย่างสำหรับ fedavg คุณสามารถสร้างสถานการณ์โดยใช้
รูปที่ 1: ตัวอย่างสำหรับ fedavg คุณสามารถสร้างสถานการณ์โดยใช้ generate_DATA.py และเรียกใช้อัลกอริทึมโดยใช้ main.py , clientNAME.py และ serverNAME.py สำหรับอัลกอริทึมใหม่คุณจะต้องเพิ่มคุณสมบัติใหม่ใน clientNAME.py และ serverNAME.py
หากคุณพบว่าพื้นที่เก็บข้อมูลของเรามีประโยชน์โปรดอ้างอิงกระดาษที่เกี่ยวข้อง:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 อัลกอริทึม FL แบบดั้งเดิม (TFL) และอัลกอริทึม FL (PFL) ส่วนบุคคล 3 สถานการณ์และชุดข้อมูล 24 ชุด
ผลการทดลอง บางอย่างสามารถใช้งานได้ในกระดาษและที่นี่
อ้างถึงคู่มือนี้เพื่อเรียนรู้วิธีการใช้งาน
แพลตฟอร์มมาตรฐานสามารถจำลองสถานการณ์โดยใช้ CNN 4 ชั้นบน CIFAR100 สำหรับ ลูกค้า 500 ราย ใน การ์ด NVIDIA GeForce RTX 3090 GPU ที่มีค่าใช้จ่าย หน่วยความจำ GPU เพียง 5.08GB เพียง 5.08GB
เราให้การประเมินความเป็นส่วนตัวและการวิจัยอย่างเป็นระบบ
ตอนนี้คุณสามารถฝึกอบรมลูกค้าบางรายและประเมินประสิทธิภาพของลูกค้าใหม่ได้โดยการตั้งค่า args.num_new_clients ใน ./system/main.py โปรดทราบว่าไม่ใช่อัลกอริทึม TFL/PFL ทั้งหมดที่รองรับคุณสมบัตินี้
PFLLIB มุ่งเน้นไปที่ความหลากหลายของข้อมูล (สถิติ) สำหรับอัลกอริทึมและแพลตฟอร์มมาตรฐานที่ระบุ ทั้งข้อมูลและความหลากหลายของโมเดล โปรดดูที่ การเรียนรู้แบบสหพันธรัฐที่แตกต่างกันของโครงการขยาย (HTFLLIB)
ในขณะที่เรามุ่งมั่นที่จะตอบสนองความต้องการของผู้ใช้ที่หลากหลายการอัปเดตบ่อยครั้งในโครงการอาจเปลี่ยนการตั้งค่าเริ่มต้นและรหัสการสร้างสถานการณ์ซึ่งส่งผลต่อผลการทดลอง
ปัญหาที่ปิดอาจช่วยคุณได้มากเมื่อเกิดข้อผิดพลาด
เมื่อส่งคำขอดึงโปรดให้ คำแนะนำ และ ตัวอย่าง ที่เพียงพอในช่องแสดงความคิดเห็น
ที่มาของปรากฏการณ์ ความหลากหลายของข้อมูล คือลักษณะของผู้ใช้ที่สร้าง Non-IID (ไม่เป็นอิสระและกระจายเหมือนกัน) และข้อมูลที่ไม่สมดุล ด้วยความแตกต่างของข้อมูลที่มีอยู่ในสถานการณ์ FL ได้มีการเสนอวิธีการมากมายให้แตกนุทยากนี้ ในทางตรงกันข้าม FL (PFL) ส่วนบุคคลอาจใช้ประโยชน์จากข้อมูลที่ต่างกันทางสถิติเพื่อเรียนรู้โมเดลส่วนบุคคลสำหรับผู้ใช้แต่ละคน
FLASTION (TFL) แบบดั้งเดิม
TFL พื้นฐาน
FEDAVG- การเรียนรู้ที่มีประสิทธิภาพในการสื่อสารของเครือข่ายลึกจากข้อมูลการกระจายอำนาจ AISTATS 2017
TFL แบบอัพเดทการแก้ไข
นั่งร้าน - นั่งร้าน: ค่าเฉลี่ยควบคุมแบบสุ่มสำหรับการเรียนรู้แบบสหพันธรัฐ ICML 2020
TFL ตามมาตรฐาน
FedProx - การเพิ่มประสิทธิภาพแบบรวมในเครือข่ายที่ต่างกัน MLSYS 2020
Feddyn - การเรียนรู้แบบสหพันธรัฐขึ้นอยู่กับการทำให้เป็นมาตรฐานแบบไดนามิก ICLR 2021
TFL แบบจำลองแบบแยก
MOON- การเรียนรู้แบบสหพันธรัฐแบบจำลองการเรียนรู้ CVPR 2021
FEDLC - การเรียนรู้แบบสหพันธรัฐพร้อมการกระจายฉลากเบ้ผ่านการสอบเทียบ LOGITS ICML 2022
TFL ตามความรู้
FEDGEN- การกลั่นความรู้ที่ปราศจากข้อมูลสำหรับการเรียนรู้แบบสหพันธรัฐที่ต่างกัน ICML 2021
Fedntd- การเก็บรักษาความรู้ระดับโลกโดยการกลั่นแบบไม่จริงใน Neurips การเรียนรู้แบบสหพันธรัฐ 2022
FL (PFL) ส่วนบุคคล (PFL)
PFL ที่ใช้ Meta-Learning
PER-FEDAVG- การเรียนรู้แบบสหพันธรัฐส่วนบุคคลด้วยการรับประกันเชิงทฤษฎี: วิธีการเรียนรู้แบบจำลอง อภิมาน
PFL ตามมาตรฐาน
PFEDME - การเรียนรู้แบบสหพันธ์ส่วนบุคคลกับ Moreau Envelopes Neurips 2020
DITTO - DITTO: การเรียนรู้แบบรวมที่ยุติธรรมและมีประสิทธิภาพผ่านการปรับความเป็นส่วนตัว ICML 2021
PFL ตามส่วนบุคคล
APFL - การเรียนรู้แบบสหพันธ์ส่วนบุคคลที่ปรับตัวได้ 2020
FEDFOMO - การเรียนรู้แบบสหพันธรัฐส่วนบุคคลด้วยการเพิ่มประสิทธิภาพแบบจำลองการสั่งซื้อครั้งแรก ICLR 2021
Fedamp- การเรียนรู้ข้าม Silo Federated ส่วนบุคคลเกี่ยวกับข้อมูลที่ไม่ใช่ IID AAAI 2021
FedPhp - FedPhp: การปรับให้เป็นแบบส่วนบุคคลด้วยโมเดลส่วนตัวที่สืบทอดมา ECML PKDD 2021
Apple- ปรับตัวเข้ากับการปรับตัว: การเรียนรู้ส่วนบุคคลสำหรับการเรียนรู้แบบสหพันธรัฐข้าม Silo IJCAI 2022
Fedala - Fedala: การรวมตัวในท้องถิ่นที่ปรับตัวได้สำหรับการเรียนรู้แบบสหพันธ์ส่วนบุคคล AAAI 2023
PFL แบบจำลองแบบแยก
FEDPER - การเรียนรู้แบบรวมกับเลเยอร์การปรับแต่งเอง 2019
LG-FEDAVG- คิดในท้องถิ่นดำเนินการทั่วโลก: การเรียนรู้แบบรวมกับตัวแทนท้องถิ่นและระดับโลก 2020
FEDREP - ใช้ประโยชน์จากการเป็นตัวแทนที่ใช้ร่วมกันสำหรับการเรียนรู้แบบสหพันธรัฐส่วนบุคคล ICML 2021
FEDROD - ในการเชื่อมโยงการเรียนรู้ทั่วไปและเป็นส่วนตัวสำหรับการจำแนกรูปภาพ ICLR 2022
Fedbabu - Fedbabu: ไปสู่การเป็นตัวแทนที่เพิ่มขึ้นสำหรับการจำแนกภาพแบบสหพันธรัฐ ICLR 2022
FEDGC - การเรียนรู้แบบสหพันธรัฐสำหรับการจดจำใบหน้าด้วยการแก้ไขการไล่ระดับสี AAAI 2022
FEDCP - FEDCP: การแยกข้อมูลคุณสมบัติสำหรับการเรียนรู้แบบสหพันธรัฐส่วนบุคคลผ่านนโยบายเงื่อนไข KDD 2023
GPFL - GPFL: การเรียนรู้ข้อมูลคุณสมบัติทั่วไปและส่วนบุคคลพร้อมกันสำหรับการเรียนรู้แบบส่วนบุคคล ICCV 2023
FEDGH - FEDGH: การเรียนรู้แบบสหพันธรัฐที่ต่างกันด้วยส่วนหัวทั่วโลก ACM MM 2023
FEDDBE - กำจัดอคติโดเมนสำหรับการเรียนรู้แบบ รวม
FedCac - กล้าหาญ แต่ระมัดระวัง: ปลดล็อคศักยภาพของการเรียนรู้แบบรวมเป็นส่วนบุคคลผ่านการทำงานร่วมกันอย่างระมัดระวังอย่างระมัดระวัง ICCV 2023
PFL-DA- การเรียนรู้แบบสหพันธรัฐส่วนบุคคลผ่านการปรับโดเมนด้วยแอปพลิเคชันเพื่อกระจาย เทคโนโลยีการพิมพ์ 3 มิติ 2023
PFL อื่น ๆ
Fedmtl (ไม่ใช่ Mocha) -Federated Multi-Task Learning Neurips 2017
FedBN -FedBN: การเรียนรู้แบบรวมกับคุณสมบัติที่ไม่ใช่ IID ผ่านการทำให้เป็นมาตรฐานในท้องถิ่น ICLR 2021
PFL ที่ใช้ความรู้-ความรู้ (เพิ่มเติมใน htfllib)
Feddistill (FD) -การเรียนรู้เครื่องจักรการสื่อสารระหว่างอุปกรณ์การเรียนรู้: การกลั่นแบบรวมและการเสริมภายใต้ข้อมูลเอกชนที่ไม่ใช่ IID 2018
FML - Federated Mutual Learning 2020
FEDKD- การเรียนรู้ที่มีประสิทธิภาพการสื่อสารผ่านความรู้การกลั่นความรู้ ธรรมชาติการสื่อสารธรรมชาติ 2022
FEDPROTO - FedProto: การเรียนรู้ต้นแบบแบบรวมทั้งลูกค้าต่างกัน AAAI 2022
FedPCL (แบบจำลอง W/O ที่ผ่านการฝึกอบรมมาแล้ว) -การเรียนรู้แบบรวมศูนย์จากแบบจำลองที่ผ่านการฝึกอบรมมาก่อน: วิธีการเรียนรู้ แบบ ตรงกันข้าม
FEDPAC - การเรียนรู้แบบสหพันธรัฐส่วนบุคคลพร้อมการจัดตำแหน่งคุณสมบัติและการร่วมมือกันแยกประเภท ICLR 2023
เรารองรับสถานการณ์ 3 ประเภทด้วยชุดข้อมูลต่าง ๆ และย้ายรหัสการแยกชุดข้อมูลทั่วไปไปยัง ./dataset/utils dataset/utils เพื่อขยายง่าย หากคุณต้องการชุดข้อมูลอื่นเพียงเขียนรหัสอื่นเพื่อดาวน์โหลดแล้วใช้ UTILS
สำหรับสถานการณ์ ที่เบ้ฉลาก เราแนะนำชุดข้อมูลที่มีชื่อเสียง 16 ชุด :
ชุดข้อมูลสามารถแบ่งออกเป็น IID และรุ่น ที่ไม่ใช่ IID ได้อย่างง่ายดาย ในสถานการณ์ ที่ไม่ใช่ IID เราแยกแยะความแตกต่างระหว่างการกระจายสองประเภท:
ทางพยาธิวิทยาที่ไม่ใช่ IID : ในกรณีนี้ลูกค้าแต่ละรายมีชุดย่อยของฉลากเท่านั้นตัวอย่างเช่นเพียง 2 จาก 10 ป้ายกำกับจากชุดข้อมูล MNIST แม้ว่าชุดข้อมูลโดยรวมจะมีป้ายกำกับทั้งหมด 10 ป้าย สิ่งนี้นำไปสู่การกระจายข้อมูลที่เบ้ข้ามลูกค้า
การปฏิบัติที่ไม่ใช่ IID : ที่นี่เราจำลองการกระจายข้อมูลโดยใช้การกระจาย Dirichlet ซึ่งส่งผลให้เกิดความไม่สมดุลที่สมจริงและรุนแรงน้อยลง สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับเรื่องนี้โปรดดูบทความนี้
นอกจากนี้เรายังเสนอตัวเลือก balance ซึ่งมีการกระจายจำนวนข้อมูลอย่างสม่ำเสมอในลูกค้าทั้งหมด
สำหรับสถานการณ์ การเปลี่ยนแปลงคุณสมบัติ เราใช้ชุดข้อมูลที่ใช้กันอย่างแพร่หลาย 3 ชุด ในการปรับโดเมน:
สำหรับสถานการณ์ ในโลกแห่งความเป็นจริง เราแนะนำชุดข้อมูลที่แยกจากกันตามธรรมชาติ 5 ชุด :
สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับชุดข้อมูลและอัลกอริทึม FL ใน IoT โปรดดูที่ FL-IOT
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy เอาต์พุตบรรทัดคำสั่งของการเรียกใช้ python generate_MNIST.py noniid - dir
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
สำหรับ MNIST และ Fashion-Mnist
สำหรับ CIFAR10, CIFAR100 และ Tiny-Imagenet
สำหรับ ag_news และ sogou_news
สำหรับ AmazonReview
สำหรับ Omniglot
สำหรับ har และ pamap
ติดตั้ง CUDA
ติดตั้ง Conda ล่าสุดและเปิดใช้งาน Conda
สำหรับการกำหนดค่าเพิ่มเติมโปรดดูสคริปต์ prepare.sh
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version ดาวน์โหลดโครงการนี้ไปยังตำแหน่งที่เหมาะสมโดยใช้ Git
git clone https://github.com/TsingZ0/PFLlib.gitสร้างสภาพแวดล้อมที่เหมาะสม (ดูสภาพแวดล้อม)
สร้างสถานการณ์การประเมินผล (ดูชุดข้อมูลและสถานการณ์ (อัปเดต))
เรียกใช้การประเมินผล:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN modelหมายเหตุ : ควรปรับแต่งอัลกอริทึมเฉพาะอัลกอริทึมเฉพาะพารามิเตอร์ก่อนใช้อัลกอริทึมใด ๆ บนเครื่องใหม่
ห้องสมุดนี้ได้รับการออกแบบให้สามารถขยายได้อย่างง่ายดายด้วยอัลกอริทึมและชุดข้อมูลใหม่ นี่คือวิธีที่คุณสามารถเพิ่มได้:
ชุดข้อมูลใหม่ : หากต้องการเพิ่มชุดข้อมูลใหม่เพียงสร้างไฟล์ generate_DATA.py ใน ./dataset dataset จากนั้นเขียนรหัสดาวน์โหลดและใช้ utils ดังแสดงใน ./dataset/generate_MNIST.py (คุณสามารถพิจารณาเป็นเทมเพลต):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func อัลกอริทึมใหม่ : เพื่อเพิ่มอัลกอริทึมใหม่ขยาย เซิร์ฟเวอร์ คลาสพื้นฐานและ ไคลเอนต์ ซึ่งกำหนดไว้ใน ./system/flcore/servers/serverbase.py และ ./system/flcore/clients/clientbase.py ตามลำดับ
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm รุ่นใหม่ : ในการเพิ่มโมเดลใหม่ให้รวมไว้ใน ./system/flcore/trainmodel/models.py
Optimizer ใหม่ : หากคุณต้องการเครื่องมือเพิ่มประสิทธิภาพใหม่สำหรับการฝึกอบรมให้เพิ่มลงใน ./system/flcore/optimizers/fedoptimizer.py
แพลตฟอร์มหรือห้องสมุดมาตรฐานใหม่ : เฟรมเวิร์กของเรามีความยืดหยุ่นช่วยให้ผู้ใช้สามารถสร้างแพลตฟอร์มหรือไลบรารีที่กำหนดเองสำหรับแอปพลิเคชันเฉพาะเช่น FL-IOT และ HTFLLIB
คุณสามารถใช้วิธีการประเมินความเป็นส่วนตัวต่อไปนี้เพื่อประเมินความสามารถในการรักษาความเป็นส่วนตัวของอัลกอริทึม TFL/PFL ใน PFLLIB โปรดดูที่ ./system/flcore/servers/serveravg.py สำหรับตัวอย่าง โปรดทราบว่าโดยทั่วไปแล้วการประเมินเหล่านี้จะไม่ได้รับการพิจารณาในเอกสารต้นฉบับ เราขอแนะนำให้คุณเพิ่มการโจมตีและตัวชี้วัดเพิ่มเติมสำหรับการประเมินความเป็นส่วนตัว
เพื่อจำลองการเรียนรู้แบบสหพันธรัฐ (FL) ภายใต้เงื่อนไขการปฏิบัติเช่น การออกกลางคันของลูกค้า ผู้ฝึกสอนช้า ผู้ส่งช้า และ เครือข่าย TTL (เวลาถึงชีวิต) คุณสามารถปรับพารามิเตอร์ต่อไปนี้:
-cdr : อัตราการออกกลางคันสำหรับลูกค้า ลูกค้าจะถูกสุ่มลดลงในแต่ละรอบการฝึกอบรมตามอัตรานี้-tsr และ -ssr : ผู้ฝึกสอนช้าและอัตราผู้ส่งช้าตามลำดับ พารามิเตอร์เหล่านี้กำหนดสัดส่วนของลูกค้าที่จะทำตัวเป็นผู้ฝึกสอนที่ช้าหรือผู้ส่งช้า เมื่อลูกค้าถูกเลือกให้เป็น "ผู้ฝึกสอนช้า" หรือ "ผู้ส่งช้า" มันจะฝึกอบรม/ส่งช้ากว่าลูกค้ารายอื่นอย่างต่อเนื่อง-tth : Threshold สำหรับเครือข่าย TTL ในมิลลิวินาทีขอบคุณ @stonesjtu ไลบรารีนี้ยังสามารถบันทึก การใช้หน่วยความจำ GPU สำหรับรุ่น
หากคุณสนใจ ผลการทดลอง (เช่นความแม่นยำ) สำหรับอัลกอริทึมที่กล่าวถึงข้างต้นคุณสามารถค้นหาผลลัพธ์ในเอกสาร FL ที่ได้รับการยอมรับของเราซึ่งใช้ห้องสมุดนี้ด้วย เอกสารเหล่านี้รวมถึง:
โปรดทราบว่าในขณะที่ผลลัพธ์เหล่านี้ขึ้นอยู่กับห้องสมุดนี้ การทำซ้ำผลลัพธ์ที่แน่นอนอาจเป็นสิ่งที่ท้าทาย เนื่องจากการตั้งค่าบางอย่างอาจมีการเปลี่ยนแปลงในการตอบสนองต่อความคิดเห็นของชุมชน ตัวอย่างเช่นในเวอร์ชันก่อนหน้าเราตั้งค่า shuffle=False ใน clientbase.py
นี่คือเอกสารที่เกี่ยวข้องสำหรับการอ้างอิงของคุณ:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


