PFLlib
37 methods
Nous créons une bibliothèque d'algorithmes et une plate-forme de référence pour les débutants pour les nouveaux à l'apprentissage fédéré. Rejoignez-nous pour élargir la communauté FL en contribuant à vos algorithmes, ensembles de données et mesures à ce projet.
? Pfllib a maintenant son site Web officiel et son nom de domaine: https: //www.pfllib.com/ !!!
? Le classement est en direct! Nos méthodes - FEDCP, GPFL et FEDDBE - ont été la voie. Notamment, FedDBE se démarque avec des performances robustes à travers des niveaux d'hétérogénéité des données variables.
? Nous changerons la licence en Apache-2.0 dans la prochaine version.
Quatre nouveaux ensembles de données ont été ajoutés, dont deux abordent des scénarios du monde réel : (1) les patchs de tissus tumoraux des métastases du cancer du sein dans des sections de ganglions lymphatiques provenant de différents hôpitaux , et (2) des photos de la faune capturées par différents pièges à caméra . Les deux autres ensembles de données se concentrent sur le scénario d'étiquette : les images de rayons X thoraciques des hôpitaux pour Covid-19 et des images endoscopiques des hôpitaux pour la détection des maladies gastro-intestinales. Ces ensembles de données sont également compatibles avec notre htfllib
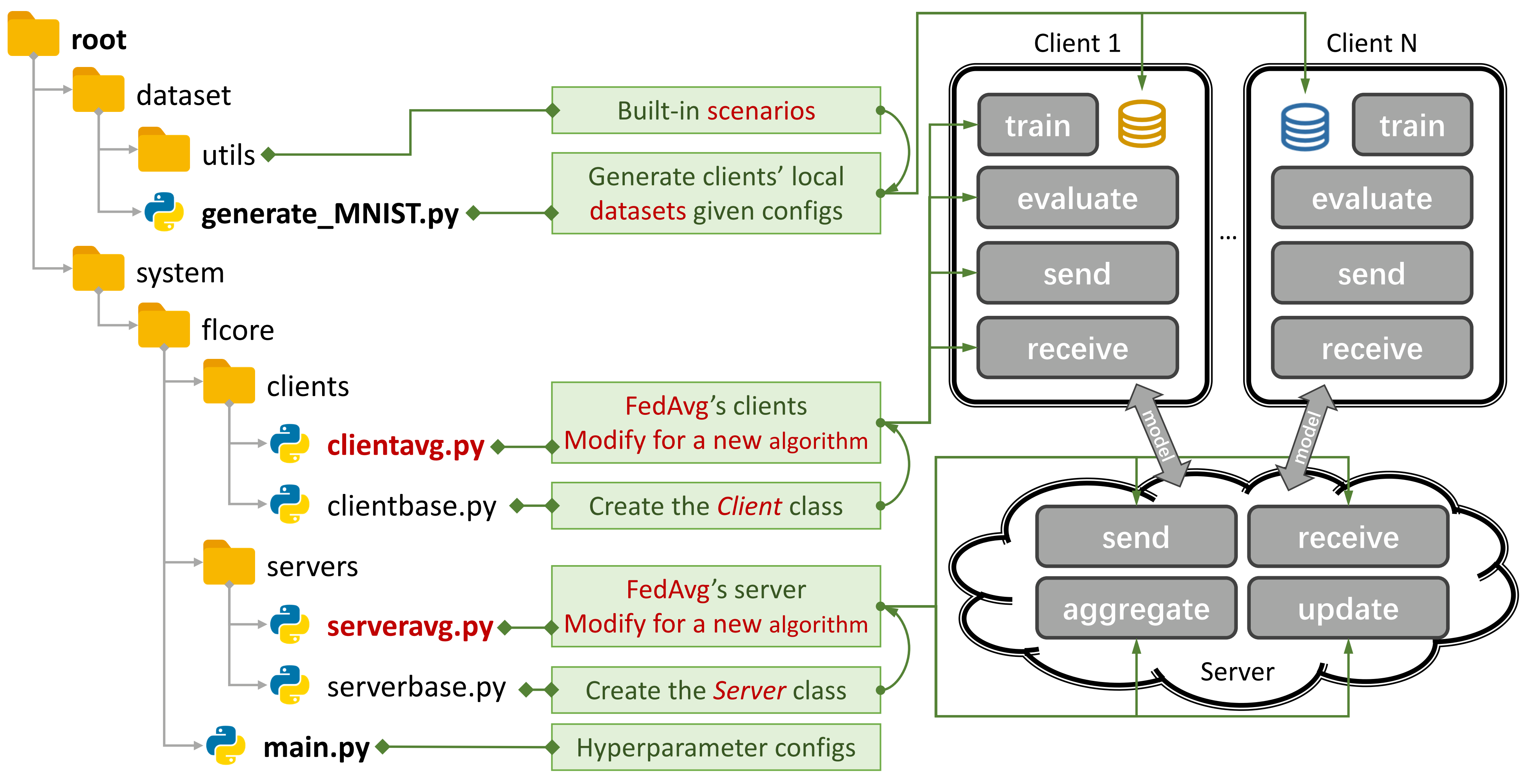 Figure 1: Un exemple pour Fedavg. Vous pouvez créer un scénario à l'aide de
Figure 1: Un exemple pour Fedavg. Vous pouvez créer un scénario à l'aide de generate_DATA.py et exécuter un algorithme à l'aide de main.py , clientNAME.py et serverNAME.py . Pour un nouvel algorithme, il vous suffit d'ajouter de nouvelles fonctionnalités dans clientNAME.py et serverNAME.py .
Si vous trouvez notre référentiel utile, veuillez citer le papier correspondant:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 Algorithmes traditionnels FL (TFL) et FL personnalisés (PFL), 3 scénarios et 24 ensembles de données.
Certains résultats expérimentaux sont disponibles dans son article et ici.
Reportez-vous à ce guide pour apprendre à l'utiliser.
La plate-forme de référence peut simuler des scénarios en utilisant le CNN à 4 couches sur CIFAR100 pour 500 clients sur une carte GPU NVIDIA GEFORCE RTX 3090 avec seulement 5,08 Go de coût de mémoire GPU .
Nous fournissons l'évaluation de la confidentialité et la recherche systématique Supprot.
Vous pouvez désormais vous entraîner sur certains clients et évaluer les performances sur de nouveaux clients en définissant args.num_new_clients dans ./system/main.py . Veuillez noter que tous les algorithmes TFL / PFL ne prennent pas en charge cette fonctionnalité.
Pfllib se concentre principalement sur l'hétérogénéité des données (statistique). Pour les algorithmes et une plate-forme de référence qui abordent à la fois les données et l'hétérogénéité du modèle , veuillez vous référer à notre projet étendu d'apprentissage fédéré hétérogène (HTFLLIB) .
Alors que nous nous efforçons de répondre à diverses exigences des utilisateurs, des mises à jour fréquentes du projet peuvent modifier les paramètres par défaut et les codes de création de scénarios, affectant les résultats expérimentaux.
Les problèmes fermés peuvent vous aider beaucoup lorsque des erreurs surviennent.
Lors de la soumission des demandes de traction, veuillez fournir des instructions et des exemples suffisants dans la zone de commentaire.
L'origine du phénomène d' hétérogénéité des données est les caractéristiques des utilisateurs, qui génèrent des données non IID (non indépendantes et distribuées à l'identification) et déséquilibrées. Avec l'hétérogénéité des données existant dans le scénario FL, une myriade d'approches ont été proposées pour casser cet écrou dur. En revanche, le FL personnalisé (PFL) peut profiter des données statistiquement hétérogènes pour apprendre le modèle personnalisé pour chaque utilisateur.
FL traditionnel (TFL)
TFL de base
FEDAVG - Apprentissage économe en communication des réseaux profonds à partir de données décentralisées Aistats 2017
TFL basé sur la correction de mise à jour
Échafaud - Échafaudage: moyenne contrôlée stochastique pour l'apprentissage fédéré ICML 2020
TFL basé sur la régularisation
FedProx - Optimisation fédérée dans les réseaux hétérogènes MLSYS 2020
Feddyn - Apprentissage fédéré basé sur la régularisation dynamique ICLR 2021
TFL basé sur un modèle
Lune - Apprentissage fédéré contrôlé par le modèle CVPR 2021
FedLC - Apprentissage fédéré avec distribution d'étiquette biaisée via les logits Calibration ICML 2022
TFL basé sur la distillation des connaissances
Fedgen - Distillation des connaissances sans données pour l'apprentissage fédéré hétérogène ICML 2021
Fedntd - Préservation des connaissances globales par distillation non truy dans l'apprentissage fédéré Neirips 2022
FL personnalisé (PFL)
PFL basé sur le méta-apprentissage
PER-FEDAVG - Apprentissage fédéré personnalisé avec garanties théoriques: une approche de méta-apprentissage modèle modèle-autoritaire Neirips 2020
PFL basé sur la régularisation
PFEDME - Apprentissage fédéré personnalisé avec Moreau Enveloppes Neirips 2020
Idem - Idem: apprentissage fédéré juste et robuste à travers la personnalisation ICML 2021
PFL basé sur l'accrégation personnalisée
APFL - Apprentissage fédéré personnalisé adaptatif 2020
FEDFOMO - Apprentissage fédéré personnalisé avec optimisation du modèle de premier ordre ICLR 2021
Fedamp - Apprentissage fédéré inter-silo personnalisé sur les données non IID AAAI 2021
FEDPHP - FEDPHP: Personnalisation fédérée avec des modèles privés héréditaires ECML PKDD 2021
Apple - Adapter à l'adaptation: personnalisation d'apprentissage pour l'apprentissage fédéré croisé IJCAI 2022
Fedala - Fedala: agrégation locale adaptative pour l'apprentissage fédéré personnalisé AAAI 2023
PFL basé sur un modèle
Fedper - Apprentissage fédéré avec couches de personnalisation 2019
LG-Fedavg - Pensez localement, agissez dans le monde: apprentissage fédéré avec les représentations locales et mondiales 2020
Fedrep - Exploitation des représentations partagées pour l'apprentissage fédéré personnalisé ICML 2021
FedDrod - Sur le pontage générique et personnalisé d'apprentissage fédéré pour la classification d'images ICLR 2022
Fedbabu - Fedbabu: vers une représentation améliorée pour la classification des images fédérée ICLR 2022
FEDGC - Apprentissage fédéré pour la reconnaissance faciale avec correction du gradient AAAI 2022
FEDCP - FEDCP: séparation des informations sur les fonctionnalités pour l'apprentissage fédéré personnalisé via la politique conditionnelle KDD 2023
GPFL - GPFL: Apprentissage simultanément des informations sur les fonctionnalités génériques et personnalisées pour l'apprentissage fédéré personnalisé ICCV 2023
Fedgh - Fedgh: apprentissage fédéré hétérogène avec en-tête global généralisé ACM MM 2023
FedDBE - Éliminer les biais de domaine pour l'apprentissage fédéré dans l'espace de représentation des nevrips 2023
FEDCAC - Audacieux mais prudent: déverrouiller le potentiel de l'apprentissage fédéré personnalisé par une collaboration prudemment agressive ICCV 2023
PFL-DA - Apprentissage fédéré personnalisé via l'adaptation du domaine avec une application pour distribution d'impression 3D Technometrics 2023
Autre PFL
FEDMTL (pas Mocha) - Federated Multi-task Learning Neirips 2017
FedBn - FedBn: apprentissage fédéré sur les fonctionnalités non IID via la normalisation locale de la normalisation ICLR 2021
PFL basé sur la distillation des connaissances (plus dans HTFLLIB)
FedDistill (FD) - Apprentissage automatique sur distillation et augmentation de la communication: Distillation et augmentation fédérée sous Données privées non IID 2018
FML - Federated Mutual Learning 2020
Fedkd - Apprentissage fédéré économe en communication via la distillation des connaissances Communications naturelles 2022
Fedproto - Fedproto: apprentissage du prototype fédéré à travers les clients hétérogènes AAAI 2022
FedPCL (sans modèles pré-formés) - Apprentissage fédéré à partir de modèles pré-formés: une approche d'apprentissage contrastive Neirips 2022
FEDPAC - Apprentissage fédéré personnalisé avec alignement des fonctionnalités et collaboration du classificateur ICLR 2023
Nous prenons en charge 3 types de scénarios avec divers ensembles de données et déplaçons le code de division de l'ensemble de données commun en ./dataset/utils pour une extension facile. Si vous avez besoin d'un autre ensemble de données, écrivez simplement un autre code pour les télécharger, puis utilisez les utils.
Pour le scénario de biais de label , nous introduisons 16 ensembles de données célèbres:
Les ensembles de données peuvent être facilement divisés en versions IID et non IIID . Dans le scénario non IIID , nous distinguons deux types de distribution:
Non-IID pathologique : Dans ce cas, chaque client ne détient qu'un sous-ensemble des étiquettes, par exemple, seulement 2 étiquettes sur 10 de l'ensemble de données MNIST, même si l'ensemble de données global contient les 10 étiquettes. Cela conduit à une distribution très biaisée des données entre les clients.
Non-IID pratique : Ici, nous modélisons la distribution des données en utilisant une distribution de Dirichlet, ce qui se traduit par un déséquilibre plus réaliste et moins extrême. Pour plus de détails à ce sujet, reportez-vous à ce document.
De plus, nous proposons une option balance , où le montant des données est réparti uniformément entre tous les clients.
Pour le scénario de décalage des fonctionnalités , nous utilisons 3 ensembles de données largement utilisés dans l'adaptation du domaine:
Pour le scénario du monde réel , nous introduisons 5 ensembles de données naturellement séparés:
Pour plus de détails sur les ensembles de données et les algorithmes FL dans l'IoT , veuillez vous référer à FL-IOT.
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy La sortie de la ligne de commande de l'exécution python generate_MNIST.py noniid - dir
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
pour Mnist et Fashion-Mnist
pour CIFAR10, CIFAR100 et Tiny-Imagenet
pour AG_NEWS et SOGOU_NEWS
pour Amazonreview
pour omniglot
Pour Har et Pamap
Installez CUDA.
Installez conda le plus tard et activez conda.
Pour des configurations supplémentaires, reportez-vous au script prepare.sh .
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version Téléchargez ce projet dans un emplacement approprié en utilisant GIT.
git clone https://github.com/TsingZ0/PFLlib.gitCréez des environnements appropriés (voir les environnements).
Créer des scénarios d'évaluation (voir ensembles de données et scénarios (mise à jour)).
Évaluation de l'exécution:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN modelRemarque : il est préférable de régler des hyper-paramètres spécifiques à l'algorithme avant d'utiliser un algorithme sur une nouvelle machine.
Cette bibliothèque est conçue pour être facilement extensible avec de nouveaux algorithmes et ensembles de données. Voici comment vous pouvez les ajouter:
Nouveau ensemble de données : pour ajouter un nouvel ensemble de données, créez simplement un fichier generate_DATA.py dans ./dataset , puis écrivez le code de téléchargement et utilisez les utils comme indiqué dans ./dataset/generate_MNIST.py (vous pouvez le considérer comme un modèle):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func Nouvel algorithme : pour ajouter un nouvel algorithme, étendez le serveur de classes de base et le client , qui sont définis dans ./system/flcore/servers/serverbase.py et ./system/flcore/clients/clientbase.py , respectivement.
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm Nouveau modèle : pour ajouter un nouveau modèle, incluez-le simplement dans ./system/flcore/trainmodel/models.py .
Nouvel optimiseur : si vous avez besoin d'un nouvel optimiseur pour la formation, ajoutez-le à ./system/flcore/optimizers/fedoptimizer.py .
Nouvelle plate-forme de référence ou bibliothèque : notre framework est flexible, permettant aux utilisateurs de créer des plates-formes ou des bibliothèques personnalisées pour des applications spécifiques, telles que FL-IOT et HTFLLIB.
Vous pouvez utiliser les méthodes d'évaluation de la confidentialité suivantes pour évaluer les capacités de préservation de la confidentialité des algorithmes TFL / PFL dans PFLIB. Veuillez vous référer à ./system/flcore/servers/serveravg.py pour un exemple. Notez que la plupart de ces évaluations ne sont généralement pas prises en compte dans les articles d'origine. Nous vous encourageons à ajouter plus d'attaques et de mesures pour l'évaluation de la confidentialité.
Pour simuler l'apprentissage fédéré (FL) dans des conditions pratiques, tels que le décrochage du client , les formateurs lents , les expéditeurs lents et le réseau TTL (Temps-to-Live) , vous pouvez ajuster les paramètres suivants:
-cdr : Taux d'abandon pour les clients. Les clients sont abandonnés au hasard à chaque tour de formation en fonction de ce taux.-tsr et -ssr : Taux d'entraîneurs lents et les taux d'expéditeur lents, respectivement. Ces paramètres définissent la proportion de clients qui se comporteront comme des formateurs lents ou des expéditeurs lents. Une fois qu'un client est sélectionné comme "entraîneur lent" ou "expéditeur lent", il s'entraînera / envoie constamment plus lentement que les autres clients.-tth : Seuil pour le réseau TTL en millisecondes.Grâce à @stonesjtu, cette bibliothèque peut également enregistrer l' utilisation de la mémoire GPU pour le modèle.
Si vous êtes intéressé par les résultats expérimentaux (par exemple, précision) pour les algorithmes mentionnés ci-dessus, vous pouvez trouver des résultats dans nos papiers FL acceptés, qui utilisent également cette bibliothèque. Ces papiers comprennent:
Veuillez noter que même si ces résultats étaient basés sur cette bibliothèque, la reproduction des résultats exacts peut être difficile car certains paramètres auraient pu changer en réponse aux commentaires de la communauté. Par exemple, dans les versions antérieures, nous définissons shuffle=False dans clientbase.py .
Voici les articles pertinents pour votre référence:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


