PFLlib
37 methods
نقوم بإنشاء مكتبة خوارزمية صديقة للمبتدئين ومنصة معيارية لأولئك الذين يعانون من التعلم الفدرالي الجديد. انضم إلينا في توسيع مجتمع FL من خلال المساهمة في الخوارزميات ومجموعات البيانات والمقاييس لهذا المشروع.
؟ Pfllib لديها الآن موقع الويب الرسمي ونطاقها: https: //www.pfllib.com/ !!!
؟ المتصدرين يعيشون! أساليبنا - FEDCP و GPFL و Feddbe - تحلق الطريق. والجدير بالذكر أن FedDbe تبرز بأداء قوي عبر مستويات عدم تجانس البيانات المختلفة.
؟ سنقوم بتغيير الترخيص إلى Apache-2.0 في الإصدار التالي.
تمت إضافة أربع مجموعات بيانات جديدة ، اثنان منها يعالجان السيناريوهات في العالم الحقيقي : (1) بقع أنسجة الورم من ورم خبيث سرطان الثدي في أقسام العقدة الليمفاوية التي يتم الحصول عليها من مستشفيات مختلفة ، (2) صور الحياة البرية التي تم التقاطها بواسطة مصائد الكاميرا المختلفة . تركز مجموعتي البيانات الأخرى على سيناريو التسلل إلى الملصقات : صور الأشعة السينية الصدر من المستشفيات لـ Covid-19 والصور بالمنظار من المستشفيات للكشف عن مرض الجهاز الهضمي. مجموعات البيانات هذه متوافقة أيضًا مع HTFLLIB
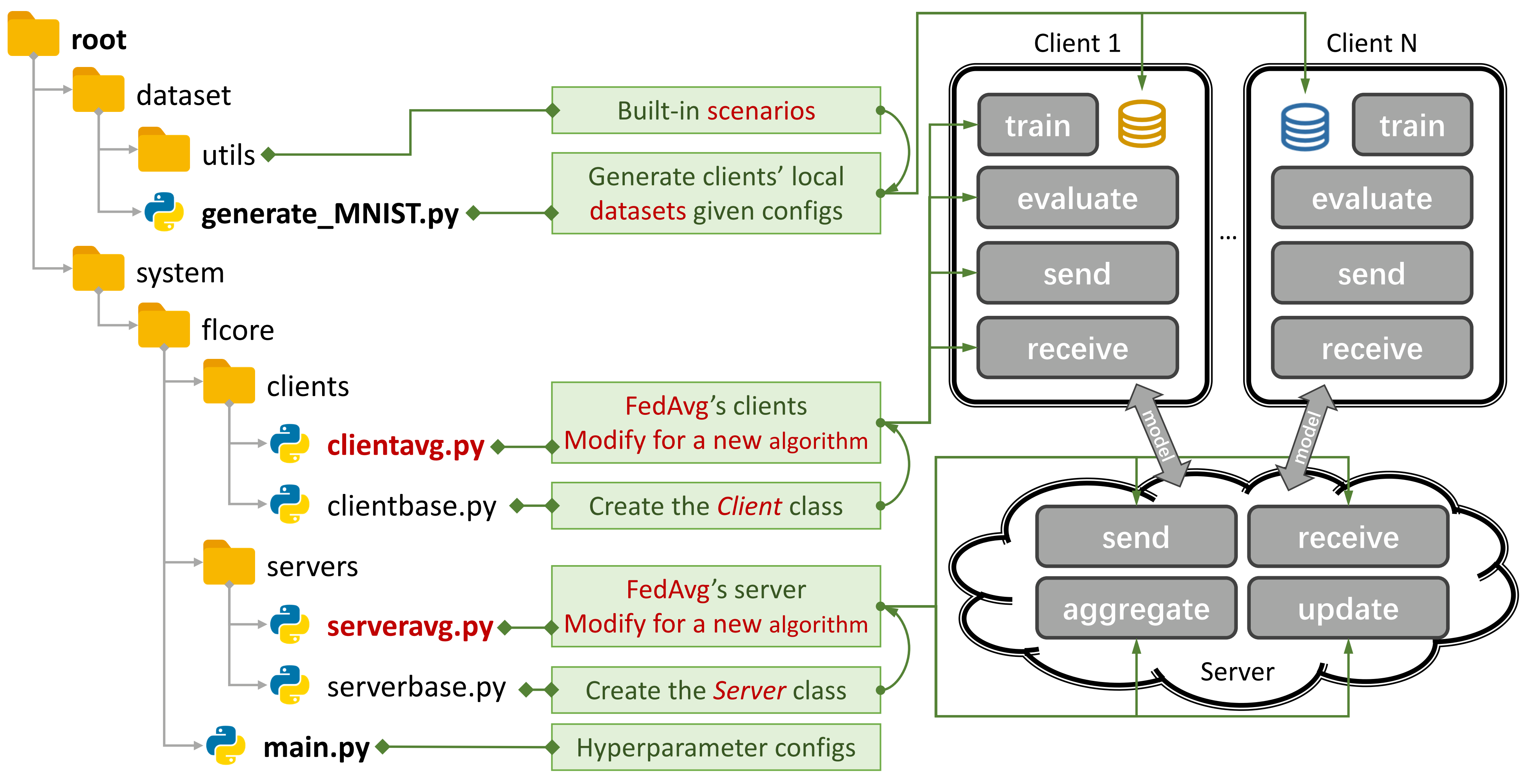 الشكل 1: مثال على Fedavg. يمكنك إنشاء سيناريو باستخدام
الشكل 1: مثال على Fedavg. يمكنك إنشاء سيناريو باستخدام generate_DATA.py وتشغيل خوارزمية باستخدام main.py و clientNAME.py و serverNAME.py . للحصول على خوارزمية جديدة ، تحتاج فقط إلى إضافة ميزات جديدة في clientNAME.py و serverNAME.py .
إذا وجدت مستودعنا مفيدًا ، فيرجى الاستشهاد بالورقة المقابلة:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 خوارزميات FL (TFL) التقليدية و FL (PFL) ، 3 سيناريوهات ، و 24 مجموعة بيانات.
بعض النتائج التجريبية هي جاذبية في ورقتها وهنا.
الرجوع إلى هذا الدليل لمعرفة كيفية استخدامه.
يمكن للمنصة المعيارية محاكاة السيناريوهات باستخدام CNN من 4 طبقات على CIFAR100 لـ 500 عميل على بطاقة GPU NVIDIA GEFORCE RTX 3090 بتكلفة ذاكرة GPU 5.08GB فقط.
نحن نقدم تقييم الخصوصية والبحث المنتظم.
يمكنك الآن التدريب على بعض العملاء وتقييم الأداء على العملاء الجدد عن طريق تعيين args.num_new_clients في ./system/main.py . يرجى ملاحظة أنه لا تدعم جميع خوارزميات TFL/PFL هذه الميزة.
يركز Pfllib بشكل أساسي على عدم التجانس (إحصائي). بالنسبة للخوارزميات ومنصة قياسية تتناول كل من البيانات وعدم تجانس النماذج ، يرجى الرجوع إلى تعليمنا الموحد غير المتجانس (HTFLLIB) .
بينما نسعى جاهدين لتلبية متطلبات المستخدمين المتنوعة ، قد تغير التحديثات المتكررة للمشروع الإعدادات الافتراضية ورموز إنشاء السيناريو ، مما يؤثر على النتائج التجريبية.
قد تساعدك المشكلات المغلقة كثيرًا عند ظهور الأخطاء.
عند تقديم طلبات السحب ، يرجى تقديم تعليمات وأمثلة كافية في مربع التعليق.
أصل ظاهرة عدم تجانس البيانات هو خصائص المستخدمين ، الذين ينشئون غير IID (غير مستقلة وموزعة بشكل متطابق) والبيانات غير المتوازنة. مع عدم تجانس البيانات الموجود في سيناريو FL ، تم اقتراح عدد لا يحصى من الأساليب لكسر هذا الجوز الصلب. في المقابل ، قد يستفيد FL (PFL) المخصص من البيانات غير المتجانسة إحصائياً لتعلم النموذج المخصص لكل مستخدم.
FL التقليدية (TFL)
TFL الأساسي
Fedavg- التعلم الفعال للاتصالات للشبكات العميقة من البيانات اللامركزية Aistats 2017
TFL القائم على تصحيح التحديث
سقالة - سقالة: متوسط مسيطر على العشوائي للتعلم الفيدرالي ICML 2020
TFL القائم على التنظيم
FedProx - التحسين الفدرالي في الشبكات غير المتجانسة MLSYS 2020
FEDDYN - التعلم المودري بناءً على تنظيم ديناميكي ICLR 2021
TFL القائم على التقسيم النموذج
القمر -التعلم الفدرالي المتحكم النموذجي CVPR 2021
FEDLC - التعلم الاتحادي مع انحراف توزيع الملصقات عبر معايرة سجلات ICML 2022
TFL القائم على تقسيم المعرفة
FEDGEN- تقطير المعرفة الخالي من البيانات للتعلم الفدرالي غير المتجانس ICML 2021
FEDNTD- الحفاظ على المعرفة العالمية من خلال التقطير غير المصنفة في التعلم الفيدرالي Neups 2022
مخصصة FL (PFL)
PFL المستندة إلى التعلم
Per-Fedavg- التعلم الفدرالي المخصص مع الضمانات النظرية: نهج التعلم التلوي العشوائي النموذجية Neurips 2020
التنظيم القائم على PFL
PFEDME - التعلم الفيدرالي المخصص مع مظاريف Moreau Neupips 2020
Ditto - Ditto: التعلم الفدرالي العادل والقوي من خلال التخصيص ICML 2021
PFL القائم على التمييز
APFL - التعلم الفدرالي المخصص التكيفي 2020
FedFomo - التعلم الفدرالي الشخصي مع تحسين نموذج الدرجة الأولى ICLR 2021
Fedamp- التعلم الفدرالي المتقاطع المتقاطع على البيانات غير IID AAAI 2021
FEDPHP - FEDPHP: التخصيص الفدرالي مع النماذج الخاصة الموروثة ECML PKDD 2021
Apple- التكيف مع التكيف: التعلم التخصيص للتعلم الفدرالي المتقاطع IJCAI 2022
Fedala - Fedala: التجميع المحلي التكيفي للتعلم الفدرالي الشخصي AAAI 2023
PFL القائم على تقسيم النموذج
Feder - التعلم الاتحادي مع طبقات التخصيص 2019
LG-FEDAVG- فكر محليًا ، ACT على الصعيد العالمي: التعلم الفدرالي مع التمثيلات المحلية والعالمية 2020
FedRep - استغلال تمثيل مشترك للتعلم الفدرالي المخصص ICML 2021
FEDROD - على سد التعلم الفيدرالي العام والشخصي لتصنيف الصور ICLR 2022
FedBabu - FedBabu: نحو التمثيل المحسن لتصنيف الصور الفدرالي ICLR 2022
FEDGC - التعلم الاتحادي للتعرف على الوجه مع تصحيح التدرج AAAI 2022
FEDCP - FEDCP: فصل معلومات الميزة للتعلم الفدرالي المخصص عبر السياسة الشرطية KDD 2023
GPFL - GPFL: في وقت واحد تعلم معلومات ميزة عامة وشخصية للتعلم الفدرالي المخصص ICCV 2023
Fedgh - Fedgh: التعلم المتدرب غير المتجانس مع الرأس العالمي المعمم ACM MM 2023
FedDBE - القضاء على تحيز المجال للتعلم الموحدة في تمثيل الفضاء العصبي 2023
FedCac - جريئة ولكن حذرة: فتح إمكانات التعلم الموحدة المخصصة من خلال التعاون العدواني بحذر ICCV 2023
PFL-DA- التعلم الفدرالي المخصص عبر التكيف مع المجال مع تطبيق لتوزيع تقنيات الطباعة ثلاثية الأبعاد 2023
أخرى PFL
FedMtl (وليس Mocha) -تعليمي متعددة المهام Neurips 2017
FEDBN -FEDBN: التعلم الفيدرالي على الميزات غير IID عبر تطبيع الدفعة المحلية ICLR 2021
PFL القائم على تقسيم المعرفة (المزيد في HTFLLIB)
FedDistill (FD) -التعلم الآلي على الجهاز فعال الاتصالات: التقطير والزيادة الموحدة بموجب بيانات خاصة غير IID 2018
FML - التعلم المتبادل الاتحاد 2020
FEDKD- التعلم الاتحادي فعال الاتصال عبر الاتصالات الطبيعة لتقطير المعرفة 2022
FedProto - FedProto: التعلم النموذجية الموحدة عبر العملاء غير المتجانسين AAAI 2022
FEDPCL (W/O النماذج التي تم تدريبها مسبقًا) -التعلم الموحد من النماذج التي تم تدريبها مسبقًا: نهج التعلم التباين Neups 2022
FEDPAC - التعلم الفدرالي المخصص مع محاذاة الميزة وتعاون المصنف ICLR 2023
نحن ندعم 3 أنواع من السيناريوهات مع مختلف مجموعات البيانات ونقل رمز تقسيم مجموعة البيانات الشائعة إلى ./dataset/utils لسهولة التمديد. إذا كنت بحاجة إلى مجموعة بيانات أخرى ، فما عليك سوى كتابة رمز آخر لتنزيله ثم استخدم utils.
لسيناريو منحرفة التسمية ، نقدم 16 مجموعة بيانات شهيرة:
يمكن تقسيم مجموعات البيانات بسهولة إلى إصدارات IID وغير IID . في السيناريو غير IID ، نميز بين نوعين من التوزيع:
المرضية غير IID : في هذه الحالة ، يحمل كل عميل فقط مجموعة فرعية من الملصقات ، على سبيل المثال ، فقط 2 من أصل 10 ملصقات من مجموعة بيانات MNIST ، على الرغم من أن مجموعة البيانات الإجمالية تحتوي على جميع الملصقات العشرة. هذا يؤدي إلى توزيع منحرف للغاية للبيانات عبر العملاء.
عملي غير IID : هنا ، نحن نمثل توزيع البيانات باستخدام توزيع Dirichlet ، مما يؤدي إلى خلل أكثر واقعية وأقل تطرفًا. لمزيد من التفاصيل حول هذا ، راجع هذه الورقة.
بالإضافة إلى ذلك ، نقدم خيار balance ، حيث يتم توزيع مبلغ البيانات بالتساوي على جميع العملاء.
لسيناريو تحول الميزة ، نستخدم 3 مجموعات بيانات تستخدم على نطاق واسع في تكيف المجال:
لسيناريو العالم الحقيقي ، نقدم 5 مجموعات بيانات منفصلة بشكل طبيعي:
لمزيد من التفاصيل حول مجموعات البيانات وخوارزميات FL في إنترنت الأشياء ، يرجى الرجوع إلى FL -IOT.
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy إخراج سطر الأوامر لتشغيل python generate_MNIST.py noniid - dir
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
ل mnist و minist
لـ CIFAR10 و CIFAR100 و TINY-IMAGENET
لـ Ag_news و Sogou_news
ل AmazonReview
ل Omniglot
لهار وباماب
تثبيت CUDA.
تثبيت كوندا أحدث وتفعيل كوندا.
للحصول على تكوينات إضافية ، راجع البرنامج النصي prepare.sh .
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version قم بتنزيل هذا المشروع إلى موقع مناسب باستخدام GIT.
git clone https://github.com/TsingZ0/PFLlib.gitإنشاء بيئات مناسبة (انظر البيئات).
بناء سيناريوهات التقييم (انظر مجموعات البيانات والسيناريوهات (التحديث)).
تقييم التقييم:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN modelملاحظة : من الأفضل ضبط المعلمات المفرطة الخاصة بالخوارزمية قبل استخدام أي خوارزمية على جهاز جديد.
تم تصميم هذه المكتبة لتكون قابلة للتمديد بسهولة مع خوارزميات جديدة ومجموعات البيانات. إليك كيف يمكنك إضافتها:
./dataset/generate_MNIST.py بيانات جديدة : لإضافة مجموعة بيانات جديدة ، ما عليك سوى إنشاء ملف generate_DATA.py في ./dataset
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func خوارزمية جديدة : لإضافة خوارزمية جديدة ، تمديد خادم الفئات الأساسية والعميل ، والتي يتم تعريفها في ./system/flcore/servers/serverbase.py و ./system/flcore/clients/clientbase.py ، على التوالي.
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm نموذج جديد : لإضافة نموذج جديد ، ببساطة تضمينه في ./system/flcore/trainmodel/models.py .
مُحسِّن جديد : إذا كنت بحاجة إلى مُحسّن جديد للتدريب ، فأضفه إلى ./system/flcore/optimizers/fedoptimizer.py .
منصة أو مكتبة مؤيدية جديدة : إطار عملنا مرن ، مما يسمح للمستخدمين بإنشاء منصات أو مكتبات مخصصة لتطبيقات محددة ، مثل FL -IOT و HTFLLIB.
يمكنك استخدام أساليب تقييم الخصوصية التالية لتقييم إمكانات الحفاظ على الخصوصية لخوارزميات TFL/PFL في PFLLIB. يرجى الرجوع إلى ./system/flcore/servers/serveravg.py على سبيل المثال. لاحظ أن معظم هذه التقييمات لا يتم النظر فيها عادة في الأوراق الأصلية. نشجعك على إضافة المزيد من الهجمات والمقاييس لتقييم الخصوصية.
لمحاكاة التعلم الفيدرالي (FL) في ظل ظروف عملية ، مثل تسرب العميل ، والمدربين البطيئين ، والمرسلين البطيئين ، و TTL الشبكة (من الوقت إلى الخلف) ، يمكنك ضبط المعلمات التالية:
-cdr : معدل التسرب للعملاء. يتم إسقاط العملاء بشكل عشوائي في كل جولة تدريب بناءً على هذا المعدل.-tsr و -ssr : مدرب بطيء وأسعار المرسل البطيء ، على التوالي. تحدد هذه المعلمات نسبة العملاء الذين سيتصرفون كمدربين بطيئين أو مرسلين بطيئين. بمجرد اختيار العميل باعتباره "مدربًا بطيئًا" أو "مرسلًا بطيئًا" ، فإنه سيدرب/إرسال باستمرار أبطأ من العملاء الآخرين.-tth : عتبة لشبكة TTL بالميلي ثانية.بفضل stonesjtu ، يمكن لهذه المكتبة أيضًا تسجيل استخدام ذاكرة GPU للنموذج.
إذا كنت مهتمًا بالنتائج التجريبية (على سبيل المثال ، الدقة) للخوارزميات المذكورة أعلاه ، يمكنك العثور على نتائج في أوراق FL المقبولة ، والتي تستخدم أيضًا هذه المكتبة. وتشمل هذه الأوراق:
يرجى ملاحظة أنه على الرغم من أن هذه النتائج كانت تستند إلى هذه المكتبة ، إلا أن إعادة إنتاج النتائج الدقيقة قد يكون تحديًا لأن بعض الإعدادات قد تغيرت استجابة لتعليقات المجتمع. على سبيل المثال ، في الإصدارات السابقة ، قمنا بتعيين shuffle=False في clientbase.py .
فيما يلي الأوراق ذات الصلة للرجوع إليها:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


