PFLlib
37 methods
Creamos una biblioteca de algoritmo y una plataforma de referencia para principiantes para aquellos nuevos en el aprendizaje federado. Únase a nosotros para expandir la comunidad FL contribuyendo con sus algoritmos, conjuntos de datos y métricas a este proyecto.
? Pfllib ahora tiene su sitio web oficial y nombre de dominio: https: //www.pfllib.com/ !!!
? ¡La tabla de clasificación está en vivo! Nuestros métodos, FEDCP, GPFL y FEDDBE, lideran el camino. En particular, FedDBE se destaca con un rendimiento robusto en diferentes niveles de heterogeneidad de datos.
? Cambiaremos la licencia a Apache-2.0 en la próxima versión.
Se han agregado cuatro conjuntos de datos nuevos, dos de los cuales abordan escenarios del mundo real : (1) parches de tejido tumoral de metástasis de cáncer de mama en secciones de ganglios linfáticos procedentes de diferentes hospitales , y (2) fotos de vida silvestre capturadas por diferentes trampas de cámara . Los otros dos conjuntos de datos se centran en el escenario de etiqueta-sesgo : imágenes de rayos X de tórax de hospitales para Covid-19 e imágenes endoscópicas de hospitales para la detección de enfermedades gastrointestinales. Estos conjuntos de datos también son compatibles con nuestro htfllib
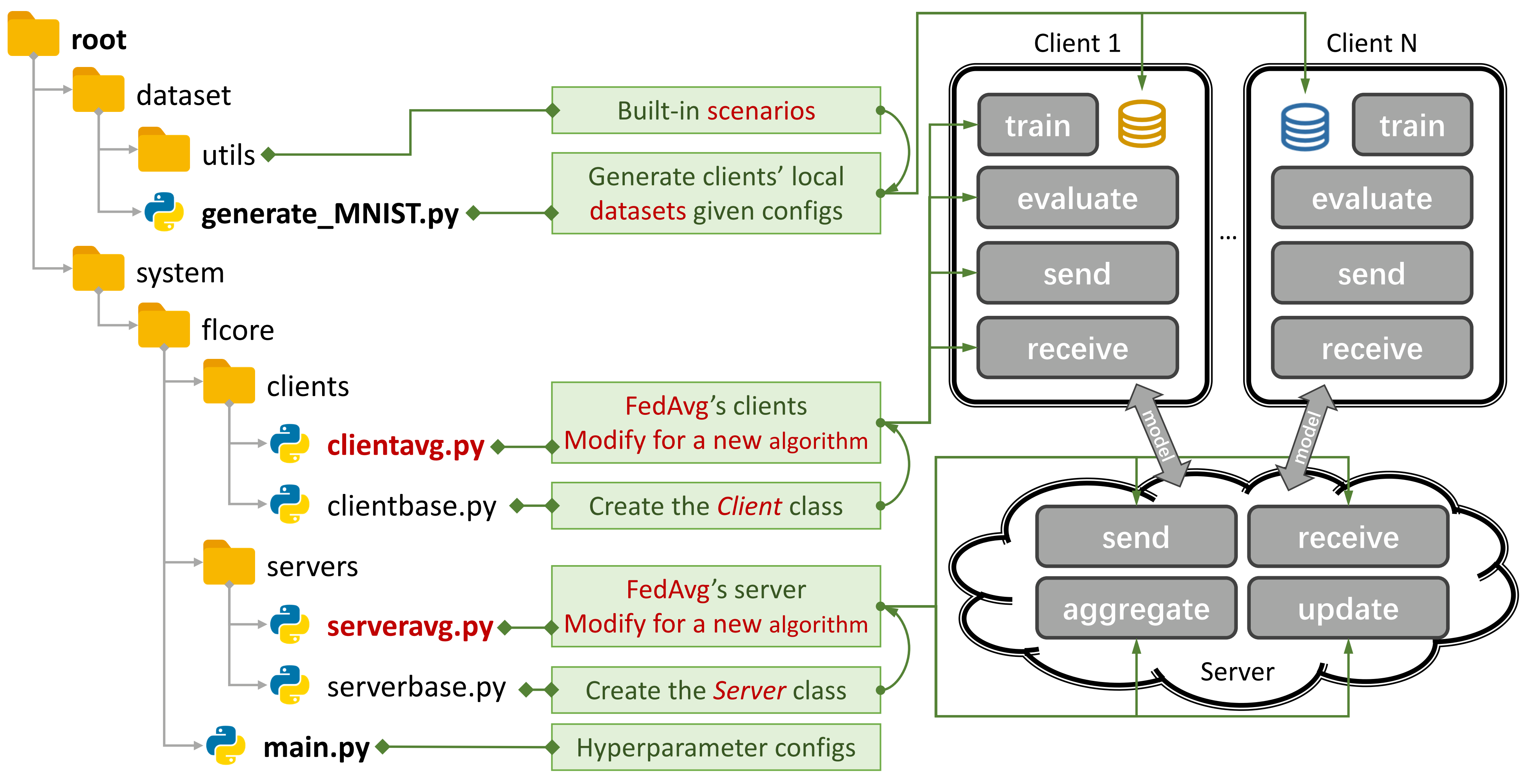 Figura 1: Un ejemplo para FedAVG. Puede crear un escenario usando
Figura 1: Un ejemplo para FedAVG. Puede crear un escenario usando generate_DATA.py y ejecutar un algoritmo usando main.py , clientNAME.py y serverNAME.py . Para un nuevo algoritmo, solo necesita agregar nuevas funciones en clientNAME.py y serverNAME.py .
Si encuentra útil nuestro repositorio, cite el documento correspondiente:
@article{zhang2023pfllib,
title={PFLlib: Personalized Federated Learning Algorithm Library},
author={Zhang, Jianqing and Liu, Yang and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian},
journal={arXiv preprint arXiv:2312.04992},
year={2023}
}
37 algoritmos tradicionales FL (TFL) y FL (PFL) personalizados, 3 escenarios y 24 conjuntos de datos.
Algunos resultados experimentales son avalibles en su artículo y aquí.
Consulte esta guía para aprender a usarla.
La plataforma de referencia puede simular escenarios utilizando el CNN de 4 capas en CIFAR100 para 500 clientes en una tarjeta GPU Nvidia GeForce RTX 3090 con solo 5.08 GB de costo de memoria de GPU .
Proporcionamos evaluación de privacidad e investigación sistemática Suprot.
Ahora puede capacitar a algunos clientes y evaluar el rendimiento en nuevos clientes estableciendo args.num_new_clients en ./system/main.py . Tenga en cuenta que no todos los algoritmos TFL/PFL admiten esta función.
PFLLIB se centra principalmente en la heterogeneidad de los datos (estadísticos). Para los algoritmos y una plataforma de referencia que aborden tanto los datos como la heterogeneidad del modelo , consulte nuestro proyecto Federado Heterogéneo (HTFLLIB) del proyecto extendido.
A medida que nos esforzamos por satisfacer diversas demandas de los usuarios, las actualizaciones frecuentes del proyecto pueden alterar la configuración predeterminada y los códigos de creación de escenarios, afectando los resultados experimentales.
Los problemas cerrados pueden ayudarlo mucho cuando surgen errores.
Al enviar solicitudes de extracción, proporcione suficientes instrucciones y ejemplos en el cuadro de comentarios.
El origen del fenómeno de la heterogeneidad de los datos son las características de los usuarios, que generan datos no IID (no independientes e idénticamente distribuidos) y desequilibrados. Con la heterogeneidad de los datos existente en el escenario FL, se ha propuesto una miríada de enfoques para descifrar esta tuerca dura. En contraste, el FL personalizado (PFL) puede aprovechar los datos estadísticamente heterogéneos para aprender el modelo personalizado para cada usuario.
FL tradicional (TFL)
TFL básico
FedAVG -Aprendizaje de la comunicación eficiente de redes profundas de datos descentralizados AISTAT 2017
TFL basado en corrección de actualizaciones
Andamio - andamio: promedio controlado estocástico para el aprendizaje federado ICML 2020
TFL basado en la regularización
FedProx - Optimización federada en redes heterogéneas MLSYS 2020
Feddyn - Aprendizaje federado basado en regularización dinámica ICLR 2021
TFL basado en la división de modelos
Luna -Modelo Contrastive Federado Learning CVPR 2021
FEDLC - Aprendizaje federado con distribución de etiquetas sesgo a través de logits calibración ICML 2022
TFL basado en la discusión de conocimiento
Fedgen -Destilación del conocimiento sin datos para el aprendizaje federado heterogéneo ICML 2021
Fedntd -Preservación del conocimiento global por destilación no verdadera en neuripas de aprendizaje federado 2022
FL personalizado (PFL)
PFL basado en meta-aprendizaje
Por-FEDAVG -Aprendizaje federado personalizado con garantías teóricas: un enfoque de meta-aprendizaje agnóstico del modelo Neurips 2020
PFL basado en la regularización
PFEDME - Aprendizaje federado personalizado con Moreau Sobres Neurips 2020
Ídem - Ditto: aprendizaje federado justo y robusto a través de la personalización ICML 2021
PFL basado en la agregación personalizada
APFL - Aprendizaje federado personalizado adaptativo 2020
Fedfomo : aprendizaje federado personalizado con optimización del modelo de primer orden ICLR 2021
FEDAMP -Aprendizaje federado personalizado de Silo en datos no IID AAAI 2021
FedPhP - FedPhp: personalización federada con modelos privados heredados ECML PKDD 2021
Apple -Adapte a la adaptación: Personalización de aprendizaje para el aprendizaje de federación de silbido IJCAI 2022
Fedala - Fedala: agregación local adaptativa para el aprendizaje federado personalizado AAAI 2023
PFL basado en la división de modelos
Fedper - Aprendizaje federado con capas de personalización 2019
LG-FEDAVG -Piense localmente, actúe a nivel mundial: aprendizaje federado con representaciones locales y globales 2020
FedRep - Explotación de representaciones compartidas para el aprendizaje federado personalizado ICML 2021
FEDROD - Sobre unir aprendizaje federado genérico y personalizado para la clasificación de imágenes ICLR 2022
Fedbabu - Fedbabu: hacia una representación mejorada para la clasificación de imágenes federadas ICLR 2022
FEDGC - Aprendizaje federado para el reconocimiento facial con corrección de gradiente AAAI 2022
FedCP - FedCP: Separación de información de características para el aprendizaje federado personalizado a través de la política condicional KDD 2023
GPFL - GPFL: aprendiendo simultáneamente información de características genéricas y personalizadas para el aprendizaje federado personalizado ICCV 2023
Fedgh - Fedgh: aprendizaje federado heterogéneo con encabezado global generalizado ACM MM 2023
FEDDBE - Eliminando el sesgo de dominio para el aprendizaje federado en la representación del espacio de la representación Neurips 2023
FedCac - Bold pero cauteloso: desbloquear el potencial del aprendizaje federado personalizado a través de una colaboración cautelosamente agresiva ICCV 2023
PFL-DA -Aprendizaje federado personalizado a través de la adaptación de dominio con una aplicación a la impresión 3D distribuida Technometrics 2023
Otro PFL
Fedmtl (no moca) -Federated Multy-Task Learning Neurips 2017
Fedbn -FedBn: aprendizaje federado en características no IID a través de la normalización de lotes locales ICLR 2021
PFL basado en la discusión de conocimiento (más en htfllib)
FedDistill (FD) -Aprendizaje automático en el dispositivo eficiente en comunicación: destilación federada y aumento bajo datos privados no IID 2018
FML - Aprendizaje mutuo federado 2020
FEDKD -Aprendizaje federado eficiente en comunicación a través de la destilación de conocimiento Comunicaciones de la naturaleza 2022
FedProto - FedProto: aprendizaje prototipo federado a través de clientes heterogéneos AAAI 2022
FedPCl (sin modelos previamente capacitados) -Aprendizaje federado de modelos previamente capacitados: un enfoque de aprendizaje contrastante Neurips 2022
FEDPAC - Aprendizaje federado personalizado con alineación de características y colaboración del clasificador ICLR 2023
Admitimos 3 tipos de escenarios con varios conjuntos de datos y movemos el código de división del conjunto de datos común a ./dataset/utils para una fácil extensión. Si necesita otro conjunto de datos, simplemente escriba otro código para descargarlo y luego use los Utils.
Para el escenario de sesgo de la etiqueta , presentamos 16 conjuntos de datos famosos:
Los conjuntos de datos se pueden dividir fácilmente en versiones IID y no IID . En el escenario no IID , distinguimos entre dos tipos de distribución:
No IID patológico : en este caso, cada cliente solo contiene un subconjunto de las etiquetas, por ejemplo, solo 2 de cada 10 etiquetas del conjunto de datos MNIST, a pesar de que el conjunto de datos general contiene las 10 etiquetas. Esto lleva a una distribución de datos altamente sesgada entre los clientes.
Práctico no IID : aquí, modelamos la distribución de datos utilizando una distribución de Dirichlet, lo que resulta en un desequilibrio más realista y menos extremo. Para obtener más detalles sobre esto, consulte este documento.
Además, ofrecemos una opción balance , donde el monto de los datos se distribuye uniformemente en todos los clientes.
Para el escenario de cambio de características , utilizamos 3 conjuntos de datos ampliamente utilizados en la adaptación de dominio:
Para el escenario del mundo real , presentamos 5 conjuntos de datos separados naturalmente:
Para obtener más detalles sobre conjuntos de datos y algoritmos FL en IoT , consulte FL-IOT.
cd ./dataset
# python generate_MNIST.py iid - - # for iid and unbalanced scenario
# python generate_MNIST.py iid balance - # for iid and balanced scenario
# python generate_MNIST.py noniid - pat # for pathological noniid and unbalanced scenario
python generate_MNIST.py noniid - dir # for practical noniid and unbalanced scenario
# python generate_MNIST.py noniid - exdir # for Extended Dirichlet strategy La salida de línea de comando de ejecutar python generate_MNIST.py noniid - dir
Number of classes: 10
Client 0 Size of data: 2630 Labels: [0 1 4 5 7 8 9]
Samples of labels: [(0, 140), (1, 890), (4, 1), (5, 319), (7, 29), (8, 1067), (9, 184)]
--------------------------------------------------
Client 1 Size of data: 499 Labels: [0 2 5 6 8 9]
Samples of labels: [(0, 5), (2, 27), (5, 19), (6, 335), (8, 6), (9, 107)]
--------------------------------------------------
Client 2 Size of data: 1630 Labels: [0 3 6 9]
Samples of labels: [(0, 3), (3, 143), (6, 1461), (9, 23)]
-------------------------------------------------- Client 3 Size of data: 2541 Labels: [0 4 7 8]
Samples of labels: [(0, 155), (4, 1), (7, 2381), (8, 4)]
--------------------------------------------------
Client 4 Size of data: 1917 Labels: [0 1 3 5 6 8 9]
Samples of labels: [(0, 71), (1, 13), (3, 207), (5, 1129), (6, 6), (8, 40), (9, 451)]
--------------------------------------------------
Client 5 Size of data: 6189 Labels: [1 3 4 8 9]
Samples of labels: [(1, 38), (3, 1), (4, 39), (8, 25), (9, 6086)]
--------------------------------------------------
Client 6 Size of data: 1256 Labels: [1 2 3 6 8 9]
Samples of labels: [(1, 873), (2, 176), (3, 46), (6, 42), (8, 13), (9, 106)]
--------------------------------------------------
Client 7 Size of data: 1269 Labels: [1 2 3 5 7 8]
Samples of labels: [(1, 21), (2, 5), (3, 11), (5, 787), (7, 4), (8, 441)]
--------------------------------------------------
Client 8 Size of data: 3600 Labels: [0 1]
Samples of labels: [(0, 1), (1, 3599)]
--------------------------------------------------
Client 9 Size of data: 4006 Labels: [0 1 2 4 6]
Samples of labels: [(0, 633), (1, 1997), (2, 89), (4, 519), (6, 768)]
--------------------------------------------------
Client 10 Size of data: 3116 Labels: [0 1 2 3 4 5]
Samples of labels: [(0, 920), (1, 2), (2, 1450), (3, 513), (4, 134), (5, 97)]
--------------------------------------------------
Client 11 Size of data: 3772 Labels: [2 3 5]
Samples of labels: [(2, 159), (3, 3055), (5, 558)]
--------------------------------------------------
Client 12 Size of data: 3613 Labels: [0 1 2 5]
Samples of labels: [(0, 8), (1, 180), (2, 3277), (5, 148)]
--------------------------------------------------
Client 13 Size of data: 2134 Labels: [1 2 4 5 7]
Samples of labels: [(1, 237), (2, 343), (4, 6), (5, 453), (7, 1095)]
--------------------------------------------------
Client 14 Size of data: 5730 Labels: [5 7]
Samples of labels: [(5, 2719), (7, 3011)]
--------------------------------------------------
Client 15 Size of data: 5448 Labels: [0 3 5 6 7 8]
Samples of labels: [(0, 31), (3, 1785), (5, 16), (6, 4), (7, 756), (8, 2856)]
--------------------------------------------------
Client 16 Size of data: 3628 Labels: [0]
Samples of labels: [(0, 3628)]
--------------------------------------------------
Client 17 Size of data: 5653 Labels: [1 2 3 4 5 7 8]
Samples of labels: [(1, 26), (2, 1463), (3, 1379), (4, 335), (5, 60), (7, 17), (8, 2373)]
--------------------------------------------------
Client 18 Size of data: 5266 Labels: [0 5 6]
Samples of labels: [(0, 998), (5, 8), (6, 4260)]
--------------------------------------------------
Client 19 Size of data: 6103 Labels: [0 1 2 3 4 9]
Samples of labels: [(0, 310), (1, 1), (2, 1), (3, 1), (4, 5789), (9, 1)]
--------------------------------------------------
Total number of samples: 70000
The number of train samples: [1972, 374, 1222, 1905, 1437, 4641, 942, 951, 2700, 3004, 2337, 2829, 2709, 1600, 4297, 4086, 2721, 4239, 3949, 4577]
The number of test samples: [658, 125, 408, 636, 480, 1548, 314, 318, 900, 1002, 779, 943, 904, 534, 1433, 1362, 907, 1414, 1317, 1526]
Saving to disk.
Finish generating dataset.
para mnist y fashion-mnist
para cifar10, cifar100 y tiny-iMagenet
para AG_NEWS y SOGOU_NEWS
para AmazonReview
para omniglot
para Har y Pamap
Instale CUDA.
Instale la condición más reciente y active conda.
Para configuraciones adicionales, consulte el script prepare.sh .
conda env create -f env_cuda_latest.yaml # Downgrade torch via pip if needed to match the CUDA version Descargue este proyecto a una ubicación apropiada utilizando GIT.
git clone https://github.com/TsingZ0/PFLlib.gitCree entornos adecuados (ver entornos).
Cree escenarios de evaluación (ver conjuntos de datos y escenarios (actualización)).
Evaluación de ejecución:
cd ./system
python main.py -data MNIST -m CNN -algo FedAvg -gr 2000 -did 0 # using the MNIST dataset, the FedAvg algorithm, and the 4-layer CNN modelNota : Es preferible sintonizar los hiperparametros específicos de algoritmo antes de usar cualquier algoritmo en una nueva máquina.
Esta biblioteca está diseñada para ser fácilmente extensible con nuevos algoritmos y conjuntos de datos. Así es como puedes agregarlos:
Nuevo conjunto de datos : para agregar un nuevo conjunto de datos, simplemente cree un archivo generate_DATA.py en ./dataset y luego escriba el código de descarga y use los Utils como se muestra en ./dataset/generate_MNIST.py (puede considerarlo como una plantilla):
# `generate_DATA.py`
import necessary pkgs
from utils import necessary processing funcs
def generate_dataset (...):
# download dataset as usual
# pre-process dataset as usual
X , y , statistic = separate_data (( dataset_content , dataset_label ), ...)
train_data , test_data = split_data ( X , y )
save_file ( config_path , train_path , test_path , train_data , test_data , statistic , ...)
# call the generate_dataset func Nuevo algoritmo : para agregar un nuevo algoritmo, extienda el servidor y el cliente de las clases base, que se definen en ./system/flcore/servers/serverbase.py y ./system/flcore/clients/clientbase.py , respectivamente.
# serverNAME.py
import necessary pkgs
from flcore . clients . clientNAME import clientNAME
from flcore . servers . serverbase import Server
class NAME ( Server ):
def __init__ ( self , args , times ):
super (). __init__ ( args , times )
# select slow clients
self . set_slow_clients ()
self . set_clients ( clientAVG )
def train ( self ):
# server scheduling code of your algorithm # clientNAME.py
import necessary pkgs
from flcore . clients . clientbase import Client
class clientNAME ( Client ):
def __init__ ( self , args , id , train_samples , test_samples , ** kwargs ):
super (). __init__ ( args , id , train_samples , test_samples , ** kwargs )
# add specific initialization
def train ( self ):
# client training code of your algorithm Nuevo modelo : para agregar un nuevo modelo, simplemente incluya en ./system/flcore/trainmodel/models.py .
Nuevo optimizador : si necesita un nuevo optimizador para el entrenamiento, agréguelo a ./system/flcore/optimizers/fedoptimizer.py .
Nueva plataforma o biblioteca de referencia : nuestro marco es flexible, lo que permite a los usuarios crear plataformas o bibliotecas personalizadas para aplicaciones específicas, como FL-ITIT y HTFLLIB.
Puede usar los siguientes métodos de evaluación de privacidad para evaluar las capacidades de preservación de la privacidad de los algoritmos TFL/PFL en PFLLIB. Consulte ./system/flcore/servers/serveravg.py para obtener un ejemplo. Tenga en cuenta que la mayoría de estas evaluaciones no se consideran típicamente en los documentos originales. Le recomendamos que agregue más ataques y métricas para la evaluación de la privacidad.
Para simular el aprendizaje federado (FL) en condiciones prácticas, como abandono del cliente , capacitadores lentos , remitentes lentos y TTL de red (tiempo de vida) , puede ajustar los siguientes parámetros:
-cdr : tasa de abandono para clientes. Los clientes se eliminan al azar en cada ronda de entrenamiento en función de esta tarifa.-tsr y -ssr : tasas lentas del entrenador y remitente lento, respectivamente. Estos parámetros definen la proporción de clientes que se comportarán como entrenadores lentos o remitentes lentos. Una vez que un cliente se selecciona como un "entrenador lento" o "remitente lento", entrenará/enviará constantemente más lento que otros clientes.-tth : umbral para la red TTL en milisegundos.Gracias a @StonesJTU, esta biblioteca también puede registrar el uso de la memoria de GPU para el modelo.
Si está interesado en los resultados experimentales (p. Ej., Precisión) para los algoritmos mencionados anteriormente, puede encontrar resultados en nuestros documentos FL aceptados, que también utilizan esta biblioteca. Estos documentos incluyen:
Tenga en cuenta que si bien estos resultados se basaron en esta biblioteca, la reproducción de los resultados exactos puede ser un desafío ya que algunas configuraciones podrían haber cambiado en respuesta a los comentarios de la comunidad. Por ejemplo, en versiones anteriores, establecemos shuffle=False en clientbase.py .
Estos son los documentos relevantes para su referencia:
@inproceedings{zhang2023fedala,
title={Fedala: Adaptive local aggregation for personalized federated learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={9},
pages={11237--11244},
year={2023}
}
@inproceedings{Zhang2023fedcp,
author = {Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Guan, Haibing},
title = {FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy},
year = {2023},
booktitle = {Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}
}
@inproceedings{zhang2023gpfl,
title={GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning},
author={Zhang, Jianqing and Hua, Yang and Wang, Hao and Song, Tao and Xue, Zhengui and Ma, Ruhui and Cao, Jian and Guan, Haibing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5041--5051},
year={2023}
}
@inproceedings{zhang2023eliminating,
title={Eliminating Domain Bias for Federated Learning in Representation Space},
author={Jianqing Zhang and Yang Hua and Jian Cao and Hao Wang and Tao Song and Zhengui XUE and Ruhui Ma and Haibing Guan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=nO5i1XdUS0}
}


