fast autoaugment
1.0.0
Pytorch的官方快速自动实施实施。
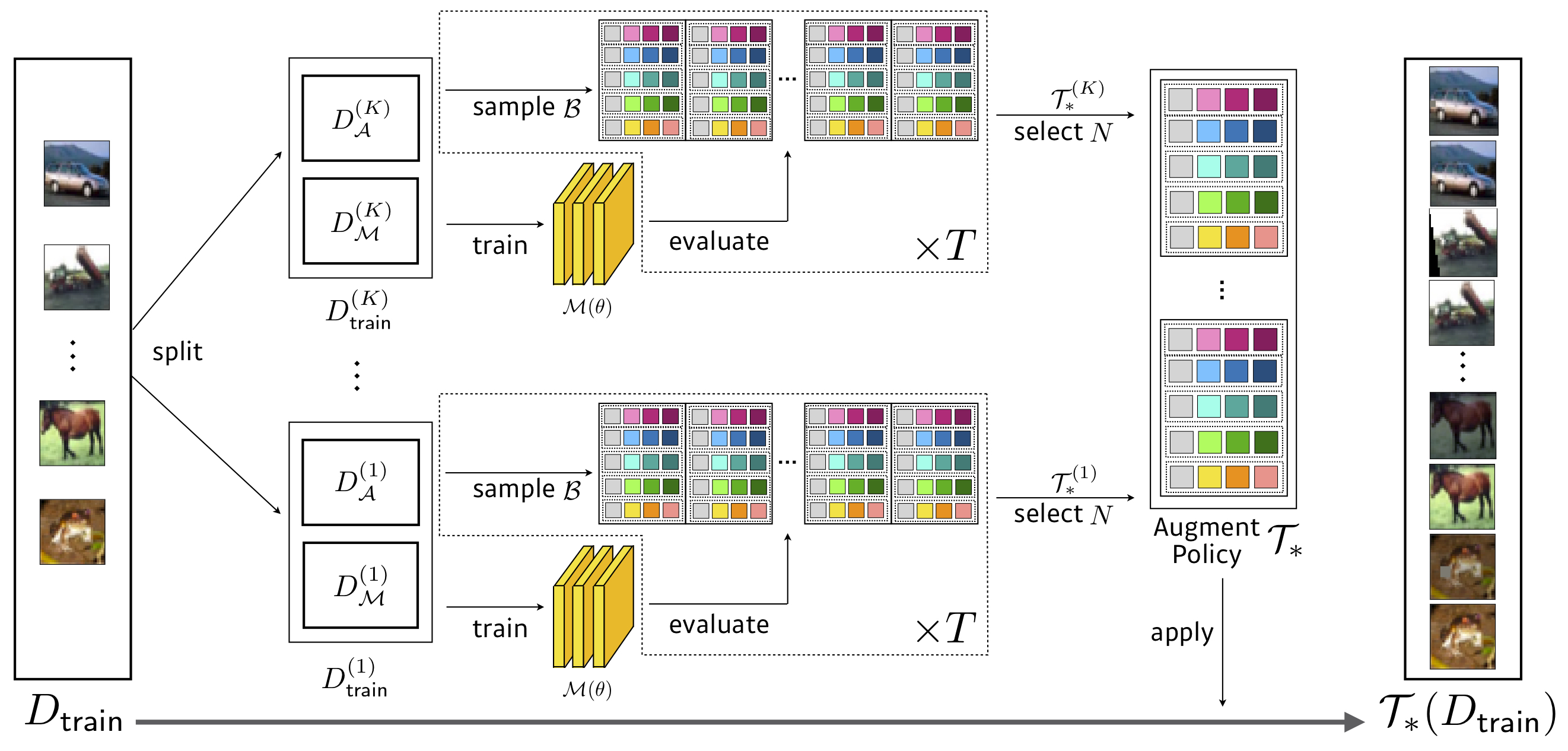
搜索: 3.5个GPU小时(比自动仪快1428倍) ,降低CIFAR-10的WRESNET-40X2
| 型号(CIFAR-10) | 基线 | 剪下 | 自动说明 | 快速自动说明 (转移/直接) | |
|---|---|---|---|---|---|
| 广泛的RESNET-40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | 下载 |
| 广泛的28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | 下载 |
| 摇晃(26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | 下载 |
| 摇晃(26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | 下载 |
| 摇晃(26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | 下载 |
| 金字塔+shakedrop | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | 下载 |
| 型号(CIFAR-100) | 基线 | 剪下 | 自动说明 | 快速自动说明 (转移/直接) | |
|---|---|---|---|---|---|
| 广泛的RESNET-40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | 下载 |
| 广泛的28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | 下载 |
| 摇晃(26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | 下载 |
| 金字塔+shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | 下载 |
搜索: 450 GPU小时(比自动说明快33倍) ,Resnet-50在减少的Imagenet上
| 模型 | 基线 | 自动说明 | 快速自动说明 (top1/top5) | |
|---|---|---|---|---|
| Resnet-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | 下载 |
| Resnet-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | 下载 |
笔记
我们已经对有效网络进行了其他实验。
| 模型 | 基线 | 自动说明 | 我们的基线(批次) | +快速AA | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
搜索: 1.5 GPU小时
| 基线 | Autoaug /我们的 | 快速自动说明 | |
|---|---|---|---|
| 宽resnet28x10 | 1.5 | 1.1 | 1.1 |
我们进行了实验
请阅读Ray的文档,以构建适当的射线群集:https://github.com/ray-project/ray,并使用Master's Redis地址运行search.py。
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
您可以在CIFAR-10 /100上培训网络体系结构,并通过我们的搜索策略进行Imagenet。
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
通过添加一种 - 一种效果和 - 储备论证,您可以在不培训的情况下测试训练有素的模型。
如果您想使用Multi-GPU/ torch.distributed.launch进行训练
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenet如果您在研究中使用此代码,请引用我们的论文。
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
我们增加了批量的规模并相应地适应学习率以提高培训。否则,如果可能的话,我们将其他等于自动仪的超参数设置为等于自动仪。对于未知的超参数,我们遵循原始参考文献中的值,或者我们调整它们以匹配基线性能。


