fast autoaugment
1.0.0
Implementación oficial de autoaugación rápida en Pytorch.
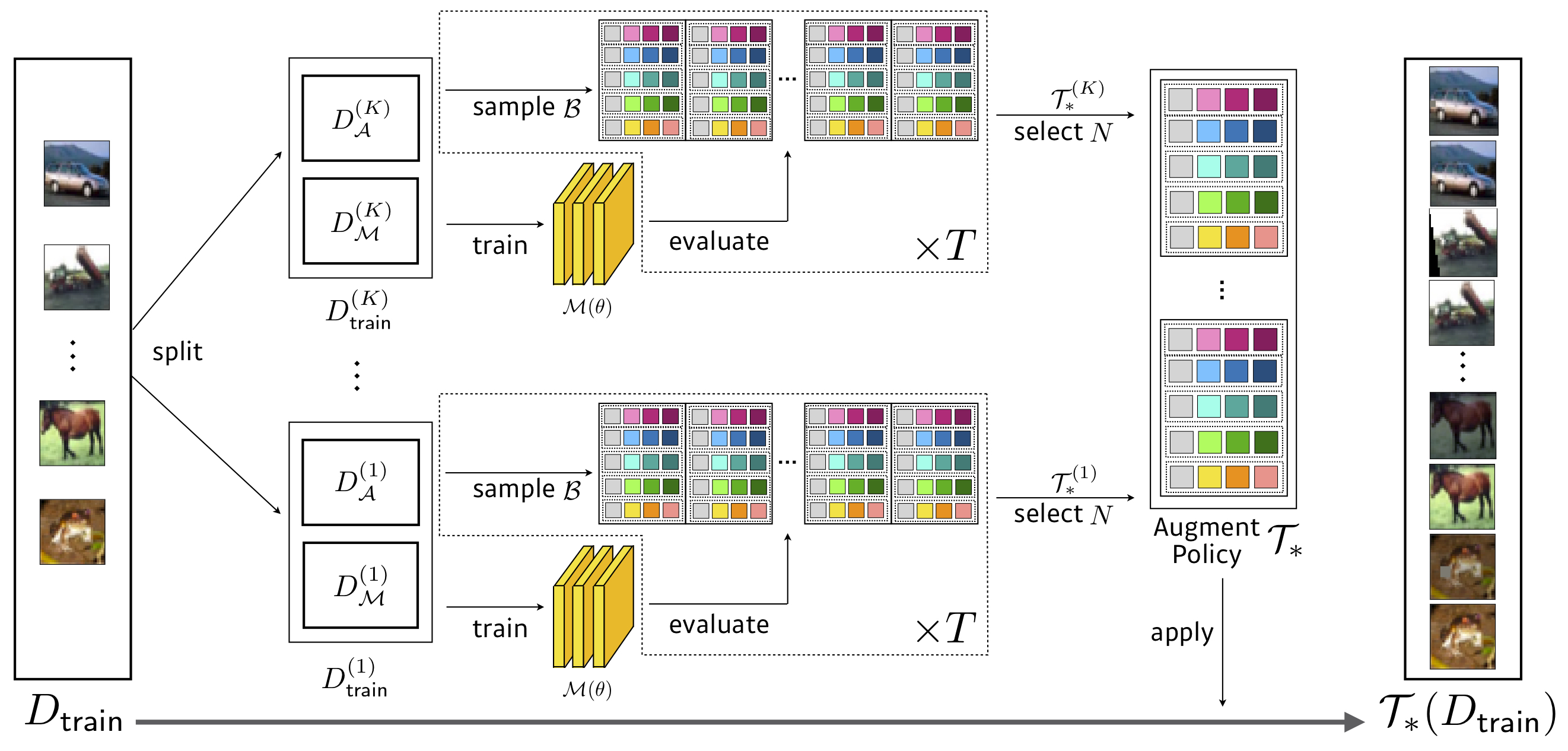
Búsqueda: 3.5 horas de GPU (1428x más rápido que el autoaugmento) , WRESNET-40X2 en CIFAR-10 reducido.
| Modelo (CIFAR-10) | Base | Separar | Autoaugación | AutoAugment rápido (transferir/directo) | |
|---|---|---|---|---|---|
| Amplio reseto-40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | Descargar |
| Amplio reinicio-28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | Descargar |
| Shake-Shake (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | Descargar |
| Shake-Shake (26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | Descargar |
| Shake-Shake (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | Descargar |
| Pyramidnet+Shakedrop | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | Descargar |
| Modelo (CIFAR-100) | Base | Separar | Autoaugación | AutoAugment rápido (transferir/directo) | |
|---|---|---|---|---|---|
| Amplio reseto-40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | Descargar |
| Amplio reinicio-28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | Descargar |
| Shake-Shake (26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | Descargar |
| Pyramidnet+Shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | Descargar |
Búsqueda: 450 horas de GPU (33 veces más rápido que el autoaugmento) , ResNet-50 en Imagenet reducido
| Modelo | Base | Autoaugación | AutoAugment rápido (Top1/Top5) | |
|---|---|---|---|---|
| Resnet-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | Descargar |
| Resnet-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | Descargar |
Notas
Hemos realizado experimentos adicionales con EficeDentNet.
| Modelo | Base | Autoaugación | Nuestra línea de base (lote) | +AA RÁPIDO | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
Búsqueda: 1.5 horas de GPU
| Base | Autoaug / nuestro | AutoAugment rápido | |
|---|---|---|---|
| Amplio reinnet28x10 | 1.5 | 1.1 | 1.1 |
Realizamos experimentos bajo
Lea el documento de Ray para construir un clúster de Ray adecuado: https://github.com/ray-project/ray, y ejecute Search.py con la dirección Redis del maestro.
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
Puede entrenar arquitecturas de red en CIFAR-10 /100 e Imagenet con nuestras políticas buscadas.
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
Al agregar los argumentos, solo eval y-salvo, puede probar modelos capacitados sin entrenamiento.
Si desea entrenar con múltiples GPU/nodo, use torch.distributed.launch como
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetSi usa este código en su investigación, cite nuestro documento.
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
Aumentamos el tamaño del lote y adaptamos la tasa de aprendizaje en consecuencia para aumentar la capacitación. De lo contrario, establecemos otros hiperparámetros iguales al autoaugmento si es posible. Para los hiperparámetros desconocidos, seguimos los valores de las referencias originales o los sintonizamos para que coincidan con las actuaciones de referencia.


