fast autoaugment
1.0.0
Pytorchでの公式の高速オートオージュの実装。
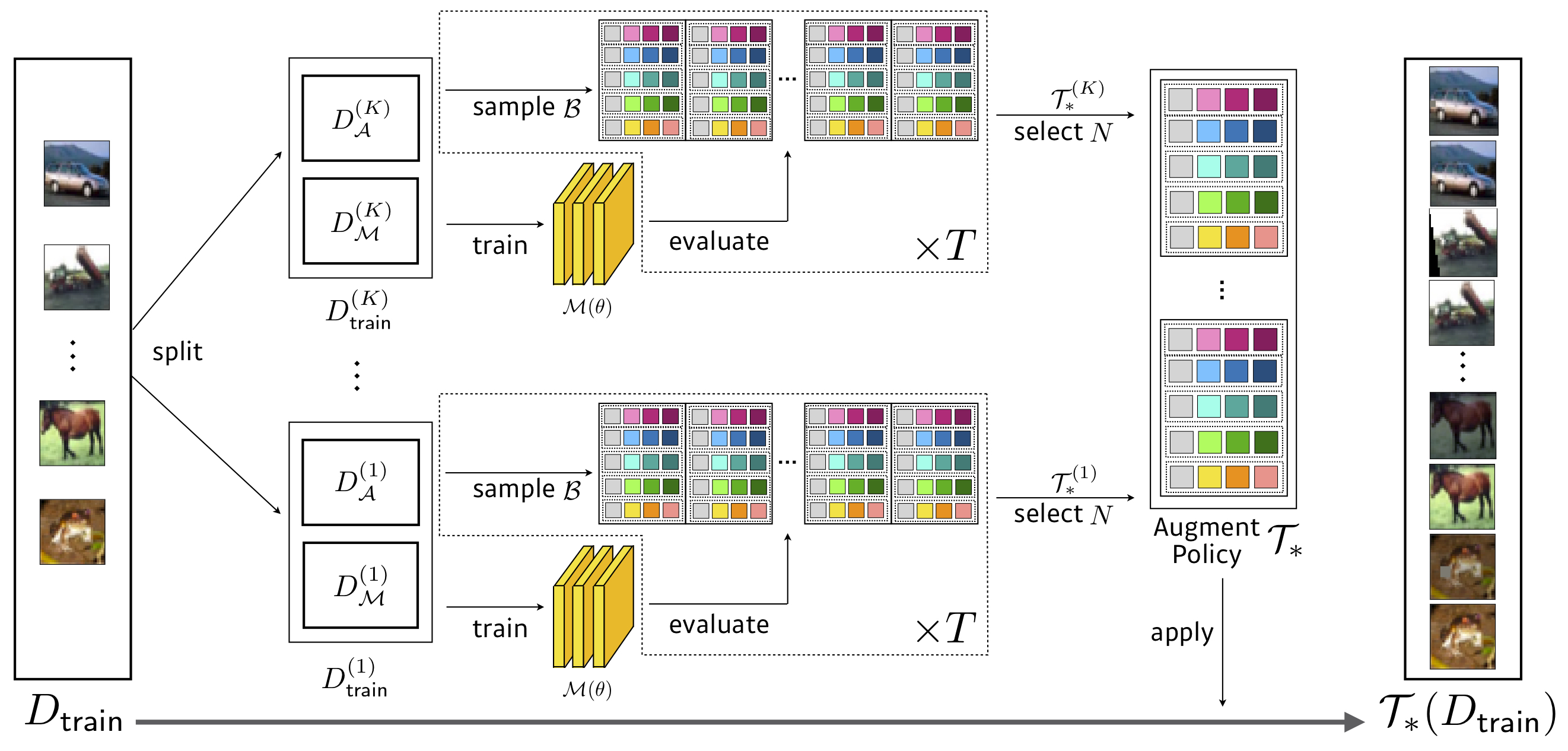
検索: 3.5 gpu時間(自動席よりも1428倍高速) 、cifar-10の減少でwresnet-40x2
| モデル(CIFAR-10) | ベースライン | 切り取る | 自動検査 | 高速の自己順位 (転送/直接) | |
|---|---|---|---|---|---|
| ワイドレスネット-40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | ダウンロード |
| ワイドレスネット-28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | ダウンロード |
| シェイクシェイク(26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | ダウンロード |
| シェイクシェイク(26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | ダウンロード |
| シェイクシェイク(26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | ダウンロード |
| pyramidnet+shakedrop | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | ダウンロード |
| モデル(CIFAR-100) | ベースライン | 切り取る | 自動検査 | 高速の自己順位 (転送/直接) | |
|---|---|---|---|---|---|
| ワイドレスネット-40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | ダウンロード |
| ワイドレスネット-28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | ダウンロード |
| シェイクシェイク(26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | ダウンロード |
| pyramidnet+shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | ダウンロード |
検索: 450 gpu時間(自動検査よりも33倍高速) 、resnet-50の削減されたイメージネット
| モデル | ベースライン | 自動検査 | 高速の自己順位 (TOP1/TOP5) | |
|---|---|---|---|---|
| Resnet-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | ダウンロード |
| Resnet-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | ダウンロード |
メモ
EfficientNetを使用して追加の実験を実施しました。
| モデル | ベースライン | 自動検査 | 私たちのベースライン(バッチ) | +fast aa | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
検索: 1.5 GPU時間
| ベースライン | AutoAug /私たち | 高速の自己順位 | |
|---|---|---|---|
| Wide-Resnet28x10 | 1.5 | 1.1 | 1.1 |
下で実験を行いました
Rayのドキュメントを読んで、適切なレイクラスターを作成してください:https://github.com/ray-project/ray、およびMasterのRedisアドレスでSearch.pyを実行してください。
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
検索されたポリシーで、CIFAR-10 /100およびImagenetでネットワークアーキテクチャをトレーニングできます。
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
-only-valおよび - save引数を追加することにより、トレーニングなしで訓練されたモデルをテストできます。
Multi-GPU/ノードでトレーニングしたい場合は、 torch.distributed.launchなどを使用します。
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetこのコードを調査で使用する場合は、私たちの論文を引用してください。
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
バッチサイズを増やし、それに応じて学習率を適応させて、トレーニングを促進します。それ以外の場合は、可能であれば、自動検査に等しい他のハイパーパラメーターを設定します。未知のハイパーパラメーターについては、元の参照から値に従うか、ベースラインのパフォーマンスに合わせてチューニングします。


