fast autoaugment
1.0.0
تنفيذ AutoAgment الرسمي السريع في Pytorch.
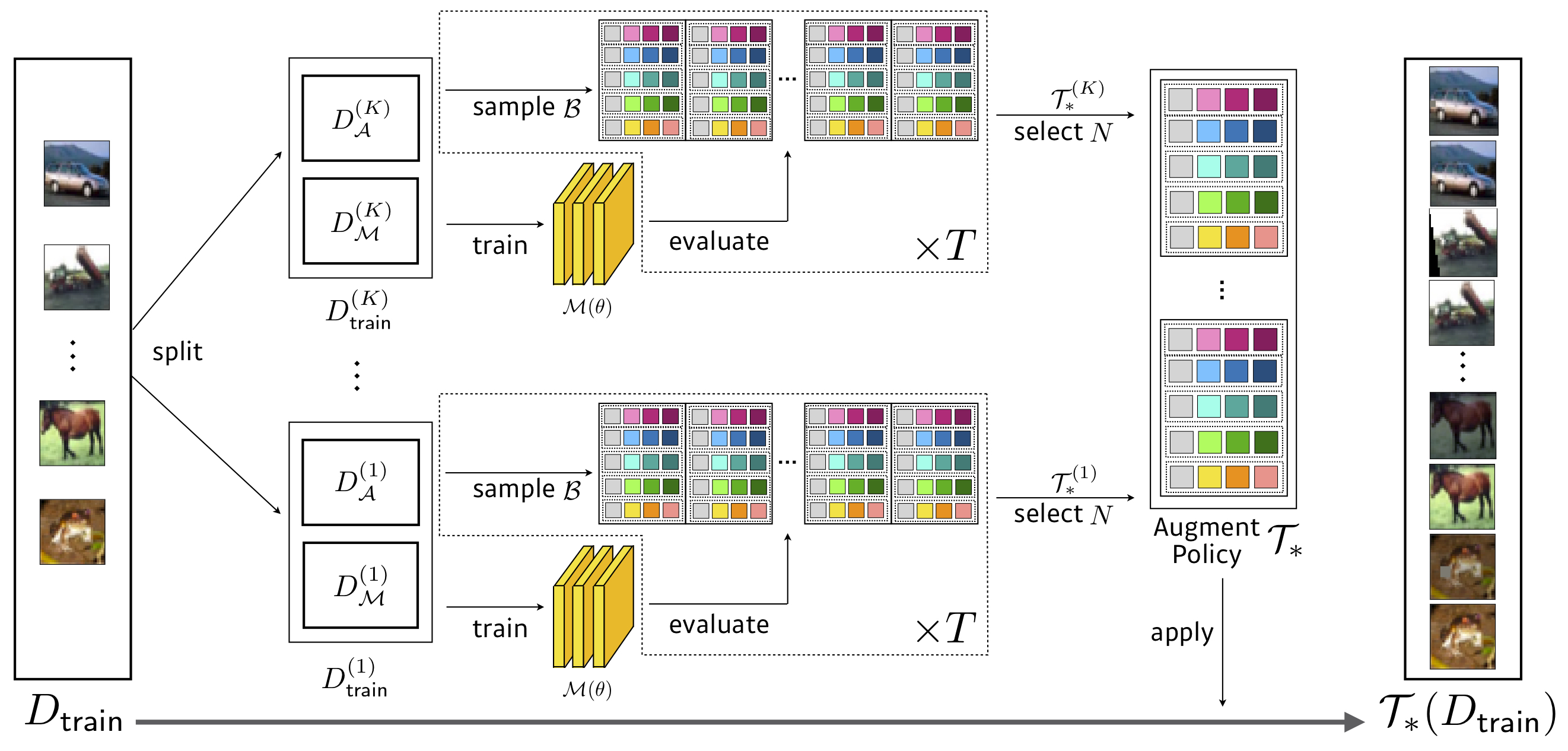
البحث: 3.5 ساعات GPU (1428x أسرع من AutoAgment) ، Wresnet-40x2 على مخفضة CIFAR-10
| النموذج (CIFAR-10) | خط الأساس | انقطاع | AutoAgment | سريع التلقائي (النقل/المباشر) | |
|---|---|---|---|---|---|
| واسعة الرصيف -40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | تحميل |
| واسعة الرصيف -28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | تحميل |
| Shake-Shake (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | تحميل |
| Shake-Shake (26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | تحميل |
| Shake-Shake (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | تحميل |
| Pyramidnet+shakedrop | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | تحميل |
| نموذج (CIFAR-100) | خط الأساس | انقطاع | AutoAgment | سريع التلقائي (النقل/المباشر) | |
|---|---|---|---|---|---|
| واسعة الرصيف -40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | تحميل |
| واسعة الرصيف -28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | تحميل |
| Shake-Shake (26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | تحميل |
| Pyramidnet+shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | تحميل |
البحث: 450 ساعة GPU (33x أسرع من AutoAgment) ، Resnet-50 على ImageNet مخفضة
| نموذج | خط الأساس | AutoAgment | سريع التلقائي (TOP1/TOP5) | |
|---|---|---|---|---|
| RESNET-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | تحميل |
| RESNET-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | تحميل |
ملحوظات
لقد أجرينا تجارب إضافية مع كفاءة.
| نموذج | خط الأساس | AutoAgment | خط الأساس لدينا (دفعة) | +FAST AA | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
البحث: 1.5 ساعات معالجة الرسومات
| خط الأساس | Autoaug / لدينا | سريع التلقائي | |
|---|---|---|---|
| واسعة RESNET28X10 | 1.5 | 1.1 | 1.1 |
أجرينا تجارب تحت
يرجى قراءة وثيقة Ray لإنشاء مجموعة راي مناسبة: https://github.com/ray-project/ray ، وقم بتشغيل Search.py مع عنوان Redis الرئيسي.
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
يمكنك تدريب بنيات الشبكة على CIFAR-10 /100 و ImageNet مع سياساتنا التي تم تفتيشها.
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
من خلال إضافة الحجج-الحجرية و--يمكنك اختبار النماذج المدربة دون تدريب.
إذا كنت ترغب في التدريب باستخدام GPU/Node Multi-GPU ، فاستخدم torch.distributed.launch مثل
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetإذا كنت تستخدم هذا الرمز في بحثك ، فيرجى الاستشهاد بالورقة.
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
نزيد من حجم الدُفعة وتكييف معدل التعلم وفقًا لذلك لتعزيز التدريب. خلاف ذلك ، قمنا بتعيين مكافآت أخرى تساوي AutoAgment إن أمكن. بالنسبة إلى المداخل غير المعروفة ، نتبع القيم من المراجع الأصلية أو نربطها لمطابقة العروض الأساسية.


