fast autoaugment
1.0.0
Официальная быстрая реализация автоаугмента в Pytorch.
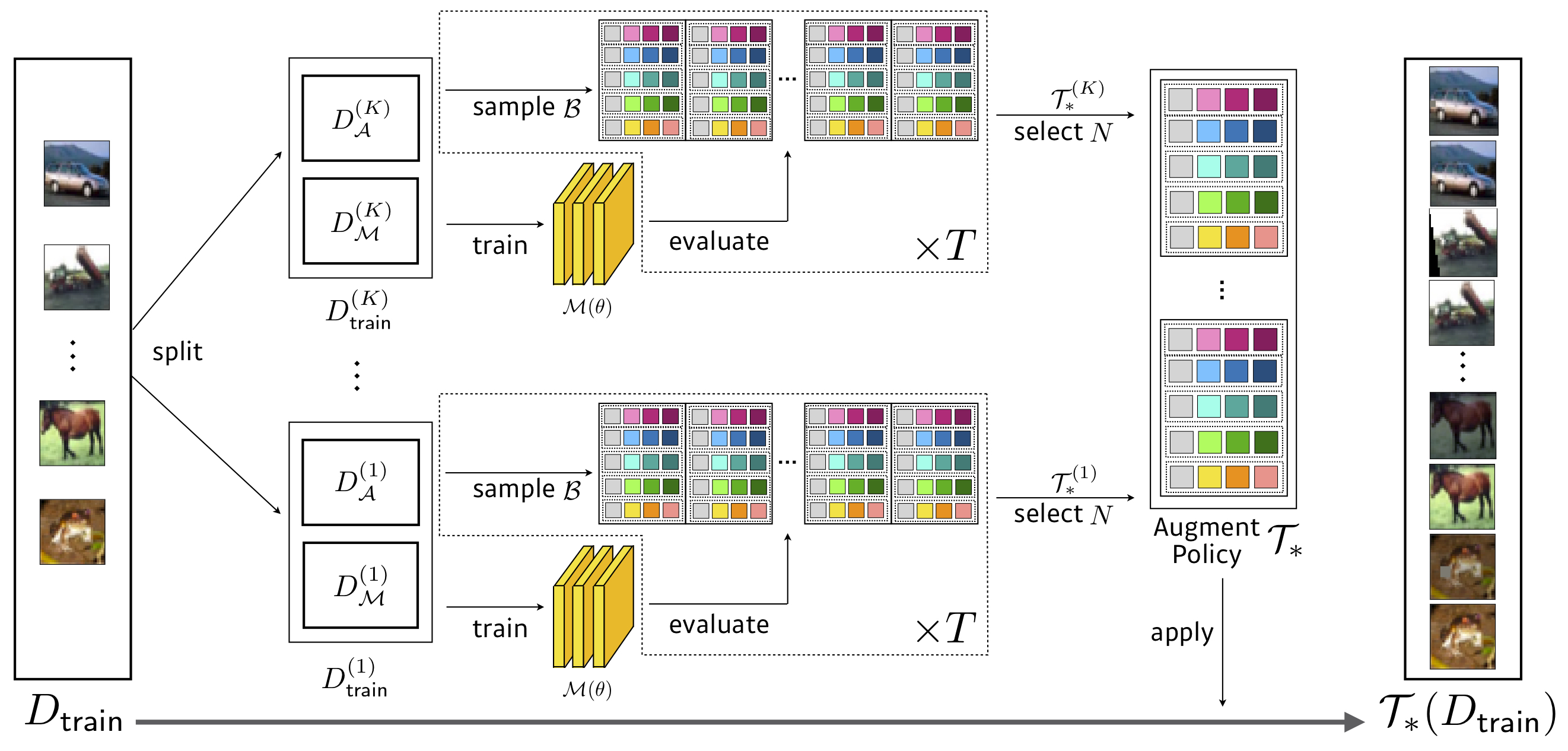
Поиск: 3,5 часа графического процессора (в 1428x быстрее, чем автоаугация) , WRESNET-40x2 на уменьшенном CIFAR-10
| Модель (CIFAR-10) | Базовый уровень | Вырезать | Автоауг | Быстрое автоауг (Передача/прямой) | |
|---|---|---|---|---|---|
| Широко-resnet-40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | Скачать |
| Широкий Реснет-28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2,7 | Скачать |
| Встряхнуть (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2,5 | Скачать |
| Встряхнуть (26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | Скачать |
| Встряхнуть (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | Скачать |
| Pyramidnet+Shakedrop | 2.7 | 2.3 | 1.5 | 1,8 / 1,7 | Скачать |
| Модель (CIFAR-100) | Базовый уровень | Вырезать | Автоауг | Быстрое автоауг (Передача/прямой) | |
|---|---|---|---|---|---|
| Широко-resnet-40-2 | 26.0 | 25.2 | 20.7 | 20,7 / 20,6 | Скачать |
| Широкий Реснет-28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | Скачать |
| Встряхнуть (26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | Скачать |
| Pyramidnet+Shakedrop | 14.0 | 12.2 | 10.7 | 11,9 / 11,7 | Скачать |
Поиск: 450 часов графического процессора (в 33 раза быстрее, чем автоаугация) , Resnet-50 на сниженном ImageNet
| Модель | Базовый уровень | Автоауг | Быстрое автоауг (TOP1/TOP5) | |
|---|---|---|---|---|
| Resnet-50 | 23,7 / 6,9 | 22.4 / 6.2 | 22.4 / 6.3 | Скачать |
| Resnet-200 | 21,5 / 5,8 | 20.0 / 5.0 | 19.4 / 4.7 | Скачать |
Примечания
Мы провели дополнительные эксперименты с AffiveNet.
| Модель | Базовый уровень | Автоауг | Наша базовая линия (партия) | +Быстрая аа | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
Поиск: 1,5 часа графического процессора
| Базовый уровень | Autoaug / наш | Быстрое автоауг | |
|---|---|---|---|
| Широко-resnet28x10 | 1.5 | 1.1 | 1.1 |
Мы провели эксперименты под
Пожалуйста, прочитайте документ Рэя, чтобы построить правильный кластер лучей: https://github.com/ray-project/ray, и запустите search.py с адресом Master's Redis.
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
Вы можете обучать сетевые архитектуры на CIFAR-10 /100 и ImageNet с нашими поисковыми политиками.
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
Добавляя-только в экипированных и совет аргументы, вы можете проверить обученные модели без обучения.
Если вы хотите тренироваться с мульти-GPU/Node, используйте torch.distributed.launch такой как
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetЕсли вы используете этот код в своем исследовании, пожалуйста, укажите нашу статью.
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
Мы увеличиваем размер партии и соответствующим образом адаптируем уровень обучения, чтобы повысить обучение. В противном случае мы устанавливаем другие гиперпараметры, равные автоаугации, если это возможно. Для неизвестных гиперпараметров мы следим за значениями из исходных ссылок или настраиваем их, чтобы соответствовать базовым выступлениям.


