fast autoaugment
1.0.0
การใช้งานอัตโนมัติอย่างเป็นทางการใน Pytorch
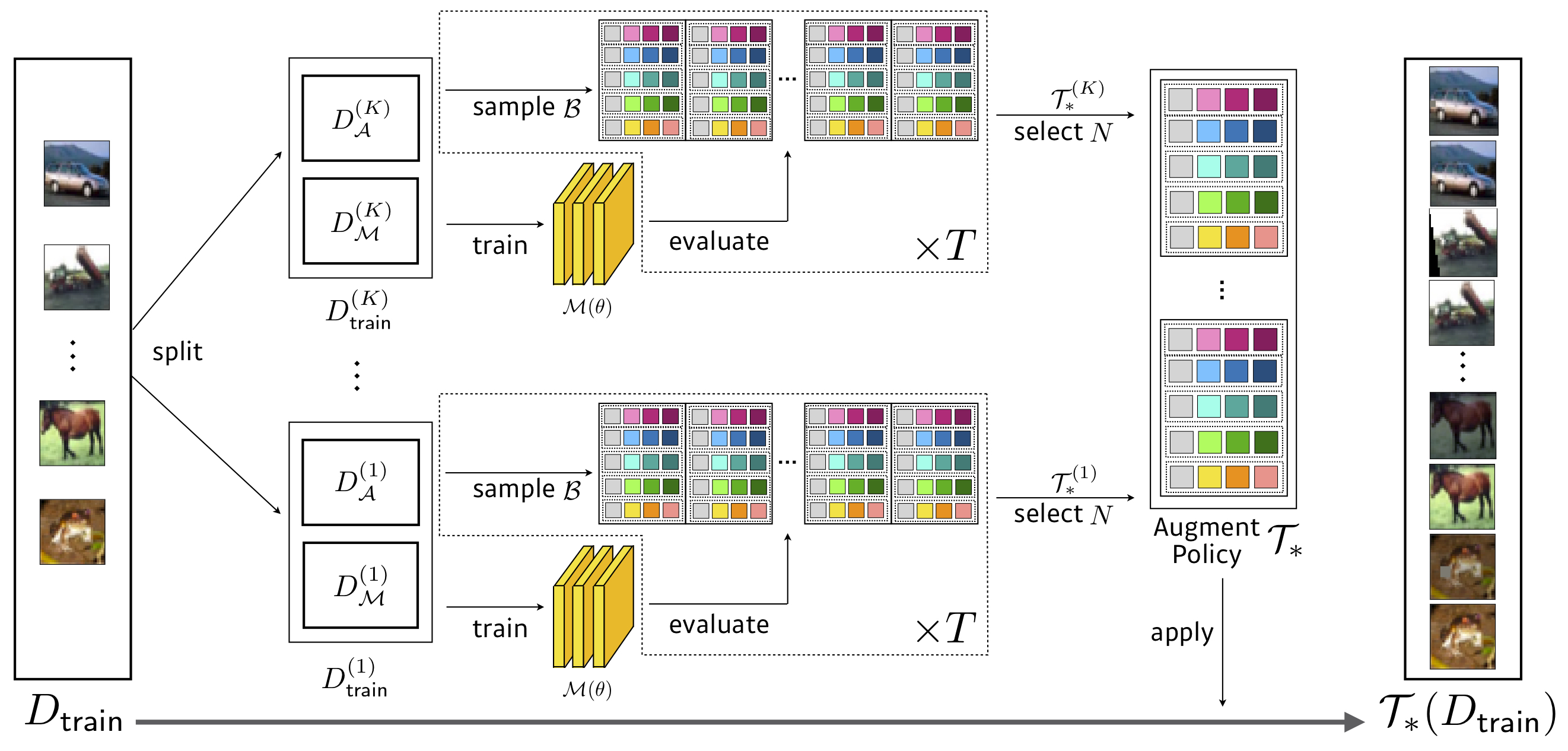
ค้นหา: 3.5 GPU ชั่วโมง (1428X เร็วกว่า AutoAugment) , WRESNET-40X2 เมื่อลด CIFAR-10
| โมเดล (CIFAR-10) | พื้นฐาน | การตัดทอน | การตรวจสอบอัตโนมัติ | autoaugment ที่รวดเร็ว (โอน/โดยตรง) | |
|---|---|---|---|---|---|
| Resnet-40-2 กว้าง | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | การดาวน์โหลด |
| Resnet-28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | การดาวน์โหลด |
| Shake-Shake (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | การดาวน์โหลด |
| Shake-Shake (26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | การดาวน์โหลด |
| Shake-Shake (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | การดาวน์โหลด |
| Pyramidnet+Shakedrop | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | การดาวน์โหลด |
| รุ่น (CIFAR-100) | พื้นฐาน | การตัดทอน | การตรวจสอบอัตโนมัติ | autoaugment ที่รวดเร็ว (โอน/โดยตรง) | |
|---|---|---|---|---|---|
| Resnet-40-2 กว้าง | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | การดาวน์โหลด |
| Resnet-28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | การดาวน์โหลด |
| Shake-Shake (26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | การดาวน์โหลด |
| Pyramidnet+Shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | การดาวน์โหลด |
ค้นหา: 450 gpu ชั่วโมง (เร็วกว่า 33x มากกว่า autoaugment) , resnet-50 บน imagenet ที่ลดลง
| แบบอย่าง | พื้นฐาน | การตรวจสอบอัตโนมัติ | autoaugment ที่รวดเร็ว (TOP1/TOP5) | |
|---|---|---|---|---|
| resnet-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | การดาวน์โหลด |
| Resnet-2000 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | การดาวน์โหลด |
หมายเหตุ
เราได้ทำการทดลองเพิ่มเติมด้วย EfficientNet
| แบบอย่าง | พื้นฐาน | การตรวจสอบอัตโนมัติ | พื้นฐานของเรา (แบทช์) | +Fast AA | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
ค้นหา: 1.5 GPU ชั่วโมง
| พื้นฐาน | autoaug / ของเรา | autoaugment ที่รวดเร็ว | |
|---|---|---|---|
| Resnet28x10 | 1.5 | 1.1 | 1.1 |
เราทำการทดลองภายใต้
โปรดอ่านเอกสารของ Ray เพื่อสร้างคลัสเตอร์เรย์ที่เหมาะสม: https://github.com/ray-project/ray และเรียกใช้ search.py กับที่อยู่ Redis ของอาจารย์
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
คุณสามารถฝึกอบรมสถาปัตยกรรมเครือข่ายบน CIFAR-10 /100 และ ImageNet ด้วยนโยบายการค้นหาของเรา
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
โดยการเพิ่ม-อาร์กิวเมนต์-eval และ--คุณสามารถทดสอบโมเดลที่ผ่านการฝึกอบรมได้โดยไม่ต้องฝึกอบรม
หากคุณต้องการฝึกอบรมด้วย multi-gpu/node ให้ใช้ torch.distributed.launch เช่น
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetหากคุณใช้รหัสนี้ในการวิจัยของคุณโปรดอ้างอิงบทความของเรา
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
เราเพิ่มขนาดแบทช์และปรับอัตราการเรียนรู้ให้เหมาะสมเพื่อเพิ่มการฝึกอบรม มิฉะนั้นเราตั้งค่าพารามิเตอร์ hypermeters อื่น ๆ เท่ากับ autoaugment ถ้าเป็นไปได้ สำหรับไฮเปอร์พารามิเตอร์ที่ไม่รู้จักเราติดตามค่าจากการอ้างอิงดั้งเดิมหรือเราปรับให้เข้ากับการแสดงพื้นฐาน


