fast autoaugment
1.0.0
Pytorch의 공식 빠른 자동 조정 구현.
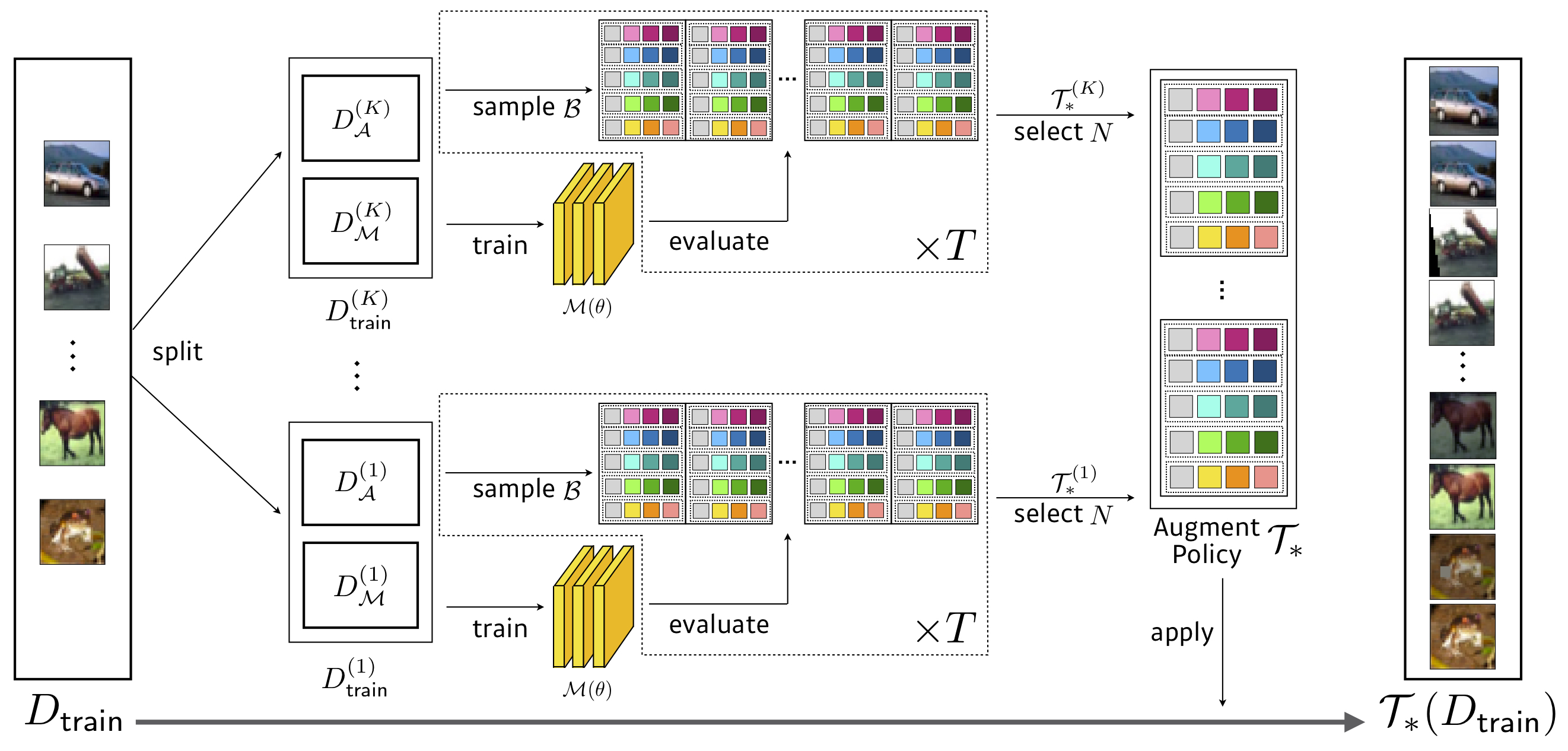
검색 : 3.5 GPU 시간 (자동 조정보다 1428 배 빠른 1428 배 더 빠르기)
| 모델 (CIFAR-10) | 기준선 | 차단 | 자동 조정 | 빠른자가 조정 (전송/직접) | |
|---|---|---|---|---|---|
| 넓은 레즈넷 -40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | 다운로드 |
| 넓은 레즈넷 -28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | 다운로드 |
| Shake-Shake (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | 다운로드 |
| Shake-Shake (26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | 다운로드 |
| Shake-Shake (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | 다운로드 |
| 피라미드 넷+셰이크 롭 | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | 다운로드 |
| 모델 (CIFAR-100) | 기준선 | 차단 | 자동 조정 | 빠른자가 조정 (전송/직접) | |
|---|---|---|---|---|---|
| 넓은 레즈넷 -40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | 다운로드 |
| 넓은 레즈넷 -28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | 다운로드 |
| Shake-Shake (26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | 다운로드 |
| 피라미드 넷+셰이크 롭 | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | 다운로드 |
검색 : 450 gpu 시간 (자가 조정보다 33 배 빠른 33 배 더 빠르기) , Resnet-50 감소 된 Imagenet
| 모델 | 기준선 | 자동 조정 | 빠른자가 조정 (Top1/Top5) | |
|---|---|---|---|---|
| RESNET-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | 다운로드 |
| RESNET-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | 다운로드 |
메모
우리는 효율적인 넷으로 추가 실험을 수행했습니다.
| 모델 | 기준선 | 자동 조정 | 우리의 기준선 (배치) | +빠른 AA | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
검색 : 1.5 GPU 시간
| 기준선 | autoaug / 우리 | 빠른자가 조정 | |
|---|---|---|---|
| 와이드 레즈넷 28x10 | 1.5 | 1.1 | 1.1 |
우리는 실험을 수행했습니다
Ray의 문서를 읽으십시오. https://github.com/ray-project/ray, Master의 Redis 주소로 Search.py를 실행하십시오.
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
CIFAR-10 / 100에서 네트워크 아키텍처와 검색 된 정책으로 Imagenet을 훈련시킬 수 있습니다.
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
-only-eval 및-save 인수를 추가하면 훈련없이 훈련 된 모델을 테스트 할 수 있습니다.
멀티 -GPU/노드로 훈련하려면 torch.distributed.launch 사용하십시오.
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenet연구 에서이 코드를 사용하는 경우 논문을 인용하십시오.
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
배치 크기를 늘리고 교육을 강화하기 위해 학습 속도를 조정합니다. 그렇지 않으면, 우리는 가능한 경우자가 조정과 동일한 다른 하이퍼 파라미터를 설정합니다. 알려지지 않은 과파 리터의 경우 원래 참조의 값을 따르거나 기준 성능과 일치하도록 조정합니다.


