fast autoaugment
1.0.0
Offizielle schnelle Autoaugment -Implementierung in Pytorch.
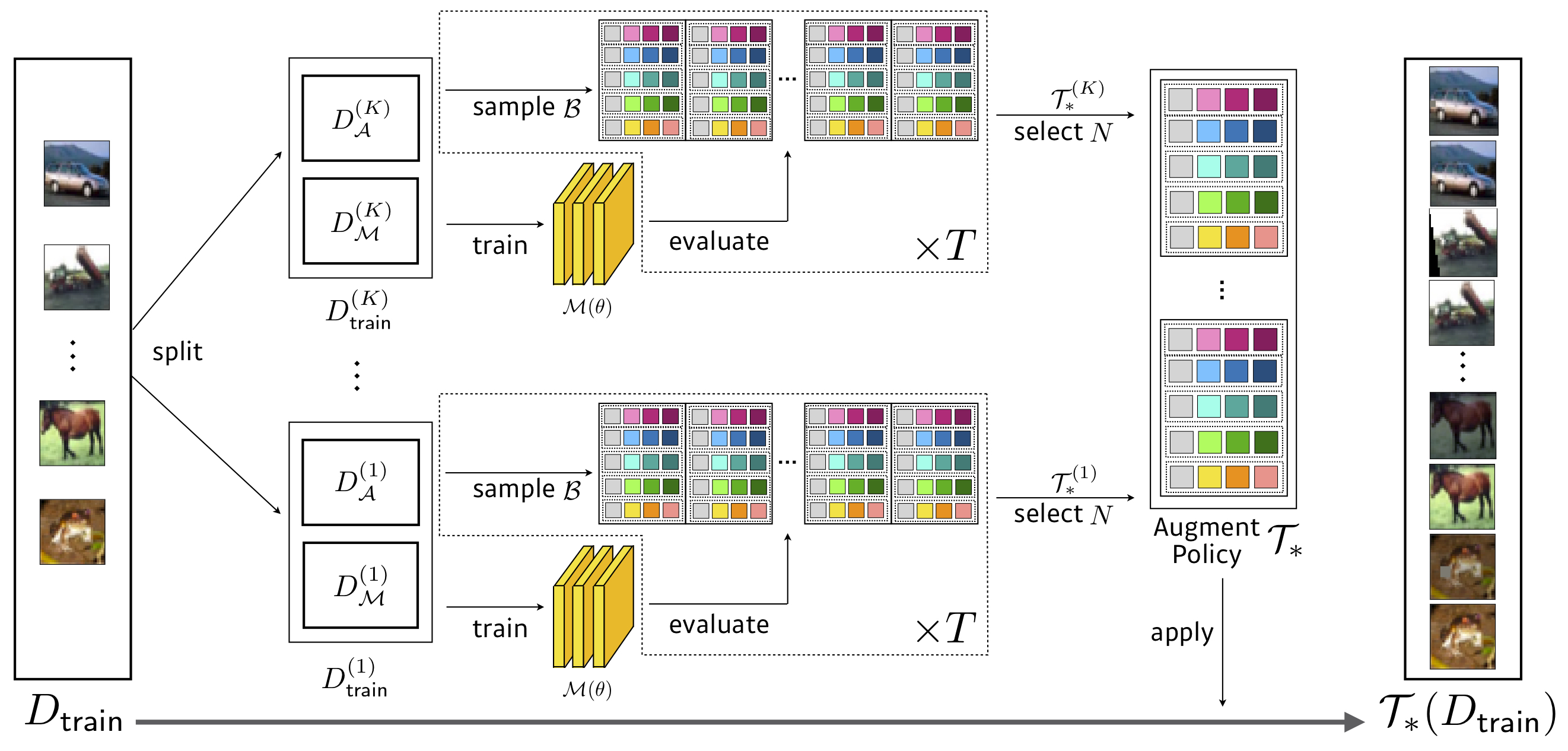
Suche: 3,5 GPU-Stunden (1428x schneller als Autoaugment) , Wresnet-40x2 auf reduziertem CIFAR-10
| Modell (CIFAR-10) | Grundlinie | Ausgeschnitten | Autoaugment | Schnelle Autoaugment (Übertragung/Direkt) | |
|---|---|---|---|---|---|
| Breit-resnet-40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | Herunterladen |
| Breit-resnet-28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | Herunterladen |
| Shake-Shake (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | Herunterladen |
| Shake-Shake (26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | Herunterladen |
| Shake-Shake (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1,9 | Herunterladen |
| Pyramidnet+Shakedrop | 2.7 | 2.3 | 1.5 | 1,8 / 1,7 | Herunterladen |
| Modell (CIFAR-100) | Grundlinie | Ausgeschnitten | Autoaugment | Schnelle Autoaugment (Übertragung/Direkt) | |
|---|---|---|---|---|---|
| Breit-resnet-40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | Herunterladen |
| Breit-resnet-28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | Herunterladen |
| Shake-Shake (26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | Herunterladen |
| Pyramidnet+Shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | Herunterladen |
Suche: 450 GPU-Stunden (33x schneller als Autoaugment) , resnet-50 auf reduziertem ImageNet
| Modell | Grundlinie | Autoaugment | Schnelle Autoaugment (Top1/Top5) | |
|---|---|---|---|---|
| Resnet-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | Herunterladen |
| Resnet-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | Herunterladen |
Notizen
Wir haben zusätzliche Experimente mit effizientemNET durchgeführt.
| Modell | Grundlinie | Autoaugment | Unsere Grundlinie (Batch) | +Schnell aa | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
Suche: 1,5 GPU -Stunden
| Grundlinie | Autoaug / unser | Schnelle Autoaugment | |
|---|---|---|---|
| Breit-resnet28x10 | 1.5 | 1.1 | 1.1 |
Wir haben Experimente unter durchgeführt
Bitte lesen Sie das Dokument von Ray, um einen richtigen Ray-Cluster zu konstruieren: https://github.com/ray-project/ray, und führen Sie Search.py mit der Redis-Adresse des Masters aus.
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
Sie können Netzwerkarchitekturen auf CIFAR-10 /100 und ImageNet mit unseren durchsuchten Richtlinien ausbilden.
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
Durch das Hinzufügen von Argumenten nur für Eval und -Save können Sie geschulte Modelle ohne Training testen.
Wenn Sie mit Multi-GPU/Knoten trainieren möchten, verwenden Sie torch.distributed.launch wie z.
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetWenn Sie diesen Code in Ihrer Forschung verwenden, zitieren Sie bitte unser Papier.
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
Wir erhöhen die Chargengröße und passen die Lernrate entsprechend an, um das Training zu steigern. Andernfalls setzen wir andere Hyperparameter, wenn möglich der Autoaugment. Für die unbekannten Hyperparameter folgen wir Werten aus den ursprünglichen Referenzen oder stimmen sie so ein, dass sie die Basisaufführungen entsprechen.


