fast autoaugment
1.0.0
Mise en œuvre officielle de l'autoaugment rapide dans Pytorch.
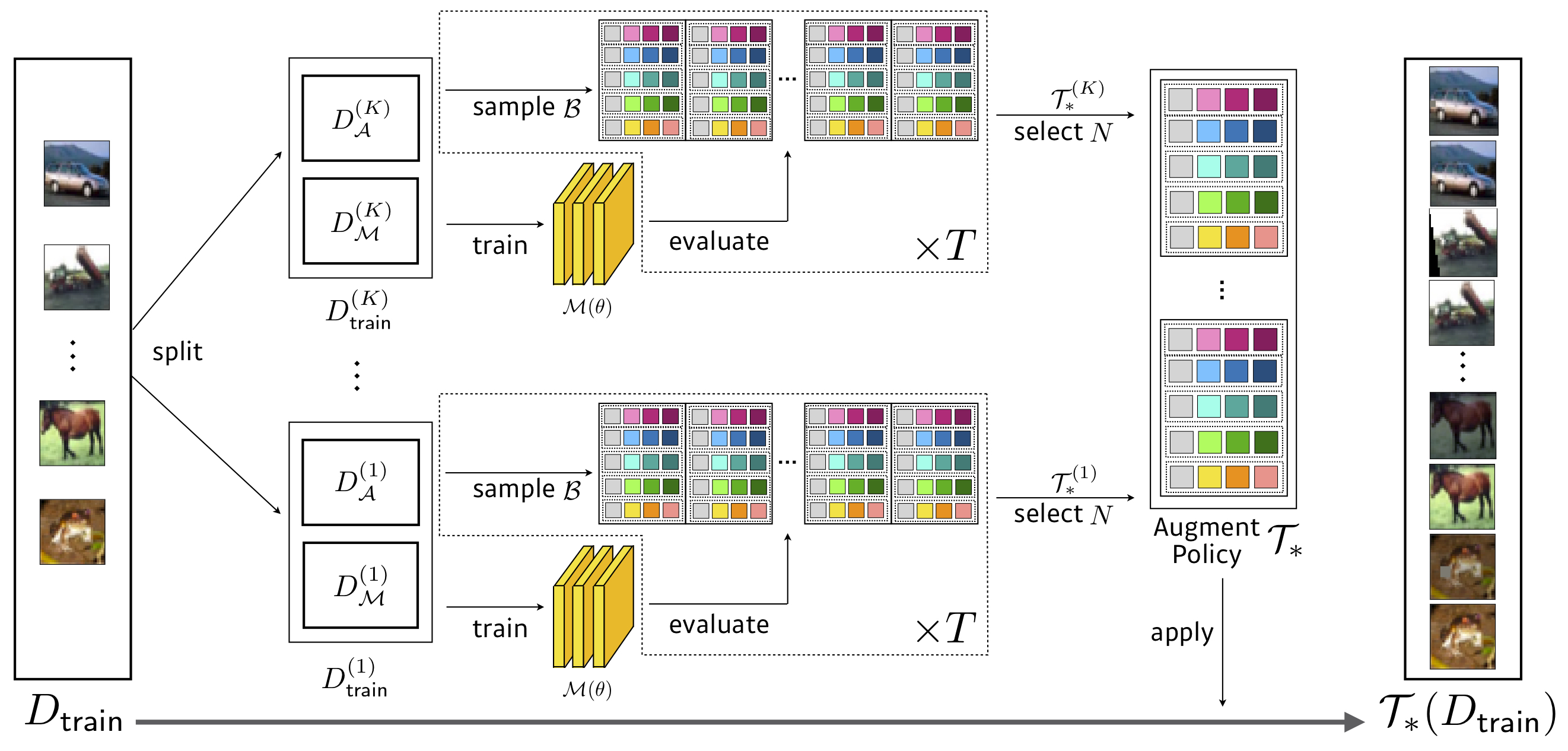
Recherche: 3,5 heures de GPU (1428x plus vite que l'autoaugment) , Wresnet-40x2 sur le CIFAR-10 réduit
| Modèle (CIFAR-10) | Base de base | Découper | Autoaugment | Autoaugment rapide (transfert / direct) | |
|---|---|---|---|---|---|
| Wide-Resnet-40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | Télécharger |
| Wide-Resnet-28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | Télécharger |
| Shake-Shake (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | Télécharger |
| Shake-Shake (26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | Télécharger |
| Shake-Shake (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | Télécharger |
| Pyramidnet + shakedrop | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | Télécharger |
| Modèle (CIFAR-100) | Base de base | Découper | Autoaugment | Autoaugment rapide (transfert / direct) | |
|---|---|---|---|---|---|
| Wide-Resnet-40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | Télécharger |
| Wide-Resnet-28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | Télécharger |
| Shake-Shake (26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | Télécharger |
| Pyramidnet + shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | Télécharger |
Recherche: 450 heures de GPU (33x plus vite que l'autoaugment) , Resnet-50 sur ImageNet réduit
| Modèle | Base de base | Autoaugment | Autoaugment rapide (Top1 / top5) | |
|---|---|---|---|---|
| Resnet-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | Télécharger |
| RESNET-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | Télécharger |
Notes
Nous avons mené des expériences supplémentaires avec unNet efficace.
| Modèle | Base de base | Autoaugment | Notre base de référence (lot) | + Fast AA | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
Recherche: 1,5 heures de GPU
| Base de base | Autoaug / notre | Autoaugment rapide | |
|---|---|---|---|
| Wide-Resnet28x10 | 1.5 | 1.1 | 1.1 |
Nous avons mené des expériences sous
Veuillez lire le document de Ray pour construire un cluster de rayons approprié: https://github.com/ray-project/ray et exécutez Search.py avec l'adresse Redis du Master.
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
Vous pouvez former des architectures de réseau sur CIFAR-10/100 et ImageNet avec nos politiques recherchées.
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
En ajoutant des arguments - uniquement-EVAL et - économiques, vous pouvez tester des modèles formés sans formation.
Si vous souhaitez vous entraîner avec le multi-GPU / Node, utilisez torch.distributed.launch tel que
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetSi vous utilisez ce code dans votre recherche, veuillez citer notre article.
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
Nous augmentons la taille du lot et adaptons le taux d'apprentissage en conséquence pour augmenter la formation. Sinon, nous définissons d'autres hyperparamètres égaux à l'autoaugment si possible. Pour les hyperparamètres inconnus, nous suivons les valeurs des références originales ou nous les réglons pour faire correspondre les performances de référence.


