fast autoaugment
1.0.0
Implementasi autoaugment cepat resmi di Pytorch.
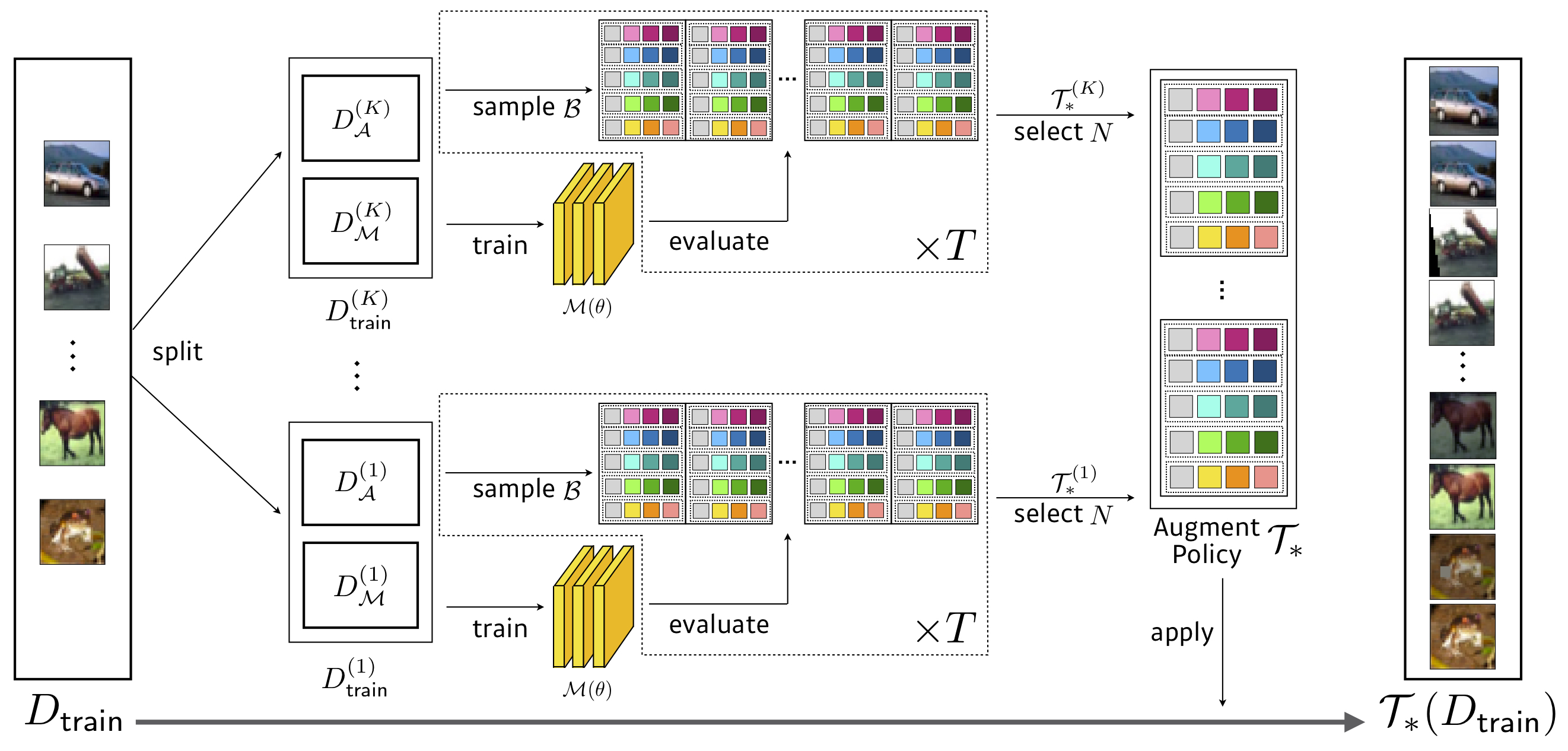
Pencarian: 3,5 jam GPU (1428x lebih cepat dari autoaugment) , WRESNET-40X2 pada CIFAR-10 yang dikurangi
| Model (CIFAR-10) | Baseline | Cutout | Autoaugment | Autoaugment cepat (Transfer/Direct) | |
|---|---|---|---|---|---|
| Wide-Resnet-40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | Unduh |
| Wide-Resnet-28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | Unduh |
| Shake-shake (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | Unduh |
| Shake-shake (26 2x96d) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | Unduh |
| Shake-shake (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | Unduh |
| Pyramidnet+shakedrop | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | Unduh |
| Model (CIFAR-100) | Baseline | Cutout | Autoaugment | Autoaugment cepat (Transfer/Direct) | |
|---|---|---|---|---|---|
| Wide-Resnet-40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | Unduh |
| Wide-Resnet-28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | Unduh |
| Shake-shake (26 2x96d) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | Unduh |
| Pyramidnet+shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | Unduh |
Pencarian: 450 jam GPU (33x lebih cepat dari autoaugment) , resnet-50 pada pengurangan imagenet
| Model | Baseline | Autoaugment | Autoaugment cepat (TOP1/TOP5) | |
|---|---|---|---|---|
| ResNet-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | Unduh |
| ResNet-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | Unduh |
Catatan
Kami telah melakukan percobaan tambahan dengan EfficientNet.
| Model | Baseline | Autoaugment | Baseline kami (batch) | +Fast AA | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
Pencarian: 1,5 jam GPU
| Baseline | Autoaug / kami | Autoaugment cepat | |
|---|---|---|---|
| RESNET28X10 yang luas | 1.5 | 1.1 | 1.1 |
Kami melakukan percobaan di bawah
Harap baca dokumen Ray untuk membuat ray cluster yang tepat: https://github.com/ray-project/ray, dan jalankan search.py dengan alamat redis master.
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
Anda dapat melatih arsitektur jaringan di CIFAR-10 /100 dan Imagenet dengan kebijakan kami yang dicari.
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
Dengan menambahkan-hanya argumen eval dan-save, Anda dapat menguji model terlatih tanpa pelatihan.
Jika Anda ingin berlatih dengan multi-GPU/node, gunakan torch.distributed.launch seperti
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetJika Anda menggunakan kode ini dalam riset Anda, silakan kutip makalah kami.
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
Kami meningkatkan ukuran batch dan mengadaptasi tingkat pembelajaran yang sesuai untuk meningkatkan pelatihan. Kalau tidak, kami mengatur hyperparameters lain yang sama dengan autoaugment jika memungkinkan. Untuk hiperparameter yang tidak diketahui, kami mengikuti nilai -nilai dari referensi asli atau kami menyetelnya untuk mencocokkan kinerja dasar.


